







模型准备
预训练和微调都在PC端进行,根据需求选择合适的深度学习框架,如Caffe、PyTorch、TensorFlow等。
预训练(pre-training) 就是指预先训练的一个模型或者指预先训练模型的过程;
微调(fine-tuning) 就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程。
在 CNN 领域中,实际上,很少人自己从头训练一个 CNN 网络。主要原因是自己很小的概率会拥有足够大的数据集,基本是几百或者几千张,不像 ImageNet 有 120 万张图片这样的规模。拥有的数据集不够大,而又想使用很好的模型的话,很容易会造成过拟合。
所以,一般的操作都是在一个大型的数据集上(ImageNet)训练一个模型,然后使用该模型作为类似任务的初始化或者特征提取器。比如 VGG,Inception 等模型都提供了自己的训练参数,以便人们可以拿来 微调 。这样既节省了时间和计算资源,又能很快的达到较好的效果。
预训练(pre-training)
预训练模型就是已经用大型数据集训练好了的模型, 已经具备了提取浅层基础特征和深层抽象特征的能力 。
正常情况下,我们常用的VGG16/19等网络已经是他人调试好的优秀网络,我们无需再修改其网络结构。
常用的预训练模型有:

迁移学习/微调(fine-tuning)
迁移学习有两种使用方式:微调(fine-tuning),特征提取器(Fixed Feature Extractor)
使用迁移学习的原因:
-
自有数据集的数据量太少
-
自己搭建的CNN模型正确率太低
-
从头开始训练存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险
-
节省计算资源和计算时间
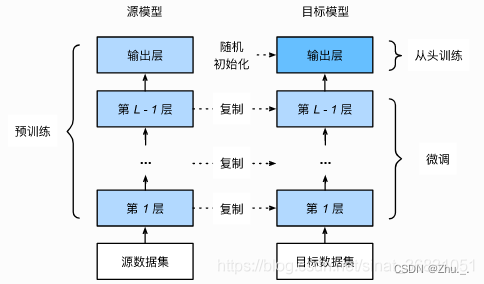
得到预训练模型(即 源模型 )后,创建一个新的神经网络模型,即 目标模型 ;
目标模型复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用;
为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化 该层 的模型参数;
在目标数据集(例如交通标志数据集)上训练目标模型。
微调(fine-tuning):输出层将从头训练,而其余层的参数都是基于源模型的参数微调得到的 ;
特征提取器(Fixed Feature Extractor):只训练输出层,其余层的参数完全不变。
微调注意事项:
-
使用较小的学习率来训练网络,通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
-
如果数据集数量过少,我们尽量只训练最后一层;如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。(前几层捕捉的是通用特征,如曲线和边,要让网络专注于学习后续深层中特定于数据集的特征。)
数据集格式不匹配 :
在进行模型微调时,我们会使用自己的数据集或适配于推理对象的公共数据集,此时新的数据集的格式可能会和感知模型的输入不匹配。
此时可以借助OpenCV库对新数据集的图片进行resize和format转换,以保持输入格式的一致性。
模型格式
训练完毕后的模型需要导入平台进行部署,这里涉及到模型训练所使用的 深度学习框架能够导出的格式 和 平台支持导入的格式 ,如果两者无法匹配则需要进行模型转换(通常为转ONNX)。
ONNX相当于一个翻译,不仅存储了神经网络模型的权重,还存储了模型的结构信息、网络中各层的输入输出等一些信息。ONNX模型转换的相关链接:
-
Pytorch2Onnx:PytTorch官方API支持直接将模型导出为ONNX模型,参考链接:(optional) Exporting a Model from PyTorch to ONNX and Running it using ONNX Runtime — PyTorch Tutorials 2.0.1+cu117 documentation
-
Tensorflow2Onnx:基于ONNX社区的onnx/tensorflow-onnx 进行转换,参考链接:GitHub - onnx/tensorflow-onnx: Convert TensorFlow, Keras, Tensorflow.js and Tflite models to ONNX
-
MXNet2Onnx:MXNet官方API支持直接将模型导出为ONNX模型,参考链接:machinelearning/test/Microsoft.ML.Tests/OnnxConversionTest.cs at main · dotnet/machinelearning · GitHub
-
更多框架的ONNX转换支持,参考链接:GitHub - onnx/tutorials: Tutorials for creating and using ONNX models
TIDL-RT支持导入的格式有:
-
Caffe (.caffemodel and .prototxt files)
-
TensorFlow (.pb files)
-
ONNX (.onnx files)
-
TFLite (.tflite files)
模型验证
模型验证过程需要检查网络算法所使用的算子是否符合平台的算子约束。
TIDL-RT支持的算子请见sdk说明文档:
./ti-processor-sdk-rtos-j721e-evm-08_05_00_11/tidl_j721e_08_05_00_16/ti_dl/docs/user_guide_html/md_tidl_layers_info.html
模型转换
模型转换步骤需要使用芯片提供的工具链将浮点模型转换为芯片可部署的模型;
此步骤包含模型导入(Import)、量化(Quantization)与编译(Graph Complier)。
TIDL-RT工具链
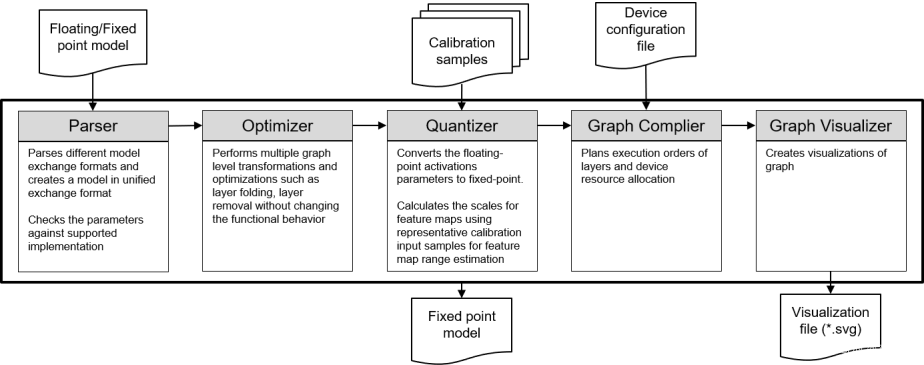
TIDL-RT的模型转换过程涉及到的参数配置分为如下几个部分,除少数必须配置的参数外,大部分参数都是可选的:
-
Basic Configuration Parameters,基础参数,包含输入模型的类型、输入输出路径、精度选项、量化选项等;
-
Configuration Parameters for Input Pre-Processing,输入预处理的参数,此处的配置需要与输入模型的设置相匹配;
-
Configuration Parameters for path of different modules,可自定义一些Importer模块内部的执行工具,如图形编译器等;
-
Configuration Parameters related to TIDL-RT inference for quantization,与推断相关的参数;
-
Configuration Parameters for quantization,量化相关的参数,如权重范围估计方法等;
-
Configuration Parameters for Graph Compiler,图形编译器的相关参数;
-
Configuration Parameters for format conversion,模型格式转换相关的参数,如输入输出的排布方式(NCHW/NHWC)等。
配置文件举例如下:
modelType = 2 numParamBits = 8 inputNetFile = "../../test/testvecs/models/public/onnx/mobilenetv2-1.0.onnx" outputNetFile = "../../test/testvecs/config/tidl_models/onnx/tidl_net_mobilenetv2.bin" outputParamsFile = "../../test/testvecs/config/tidl_models/onnx/tidl_io_mobilenetv2_" inDataNorm = 1 inMean = 123.675 116.28 103.53 inScale = 0.017125 0.017507 0.017429 resizeWidth = 256 resizeHeight = 256 inWidth = 224 inHeight = 224 inNumChannels = 3 inData = ../../test/testvecs/config/imageNet_sample_val.txt postProcType = 1
其中参数的含义为:
| Parameter | Default | Description |
|---|---|---|
| modelType | 0: Caffe | 0 : Caffe (.caffemodel and .prototxt files) 1 : TensorFlow (.pb files) 2 : ONNX (.onnx files) 3 : TFLite (.tflite files) |
| numParamBits | 8: 8-bit | 8 : 8-bit fixed-point 16 : 16-bit fixed-point 32 : 32-bit floating-point(仅支持主机端仿真,开发板不支持) |
| inputNetFile | MUST SET | 输入模型路径 |
| inputParamsFile | MUST SET if Caffe model | Caffe model的参数文件,其他模型无需设置 |
| outputNetFile | MUST SET | 输出模型路径 |
| outputParamsFile | MUST SET | 描述文件输出路径 |
| inDataNorm | 0: Disable | 是否使能输入量的标准化/归一化,只有使能的情况下才可以配置mean和scale |
| inMean | 归一化使用的均值 | |
| inScale | 归一化使用的系数值 | |
| resizeWidth | resizeWidth必须 >= inWidth,输入图像会先resize到resizeWidth,再中心裁剪为inWidth | |
| resizeHeight | 同resizeWidth操作 | |
| inWidth | 不配置时,则使用网络的原始尺寸 | |
| inHeight | 不配置时,则使用网络的原始尺寸 | |
| inNumChannels | Batches中每个输入的通道数,不配置时,则使用网络的原始尺寸 | |
| inFileFormat | 推理时的输入形式: 0 : JPEG/PNG/BMP单张图像文件输入 1 : bin文件输入 2 : txt文件(含图像文件列表)输入 | |
| inData | 推理时的输入文件路径 | |
| postProcType | 输出后处理,仅供debug 0 : Disable 1 : 分类结果 top 1 and 5 精度 2 : 为目标检测绘制bbox 3 : 绘制分割结果的彩色图 |
详细的参数配置说明在sdk中的位置如下:
./ti-processor-sdk-rtos-j721e-evm-08_05_00_11/tidl_j721e_08_05_00_16/ti_dl/docs/user_guide_html/md_tidl_model_import.html
量化(Quantization)
-
量化是一种模型压缩技术,通常是将值从大集合映射到较小集合中的值的过程( 不同精度之间的映射 ),这意味着输出包含比输入更小的可能值范围,理想情况下不会在此过程中丢失太多信息;
-
部署过程的量化会将浮点模型(Floating-point model)转化为定点模型(Fixed-point model),这个过程需要需要使用校准图像(Calibration samples)进行校准。
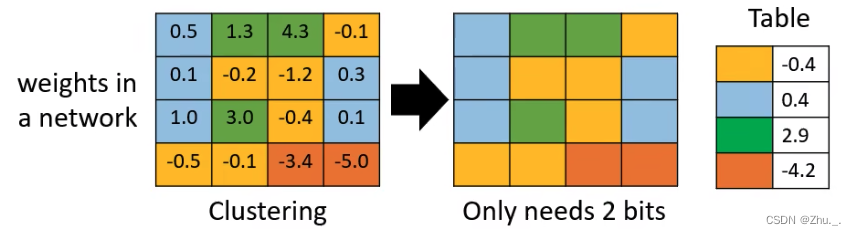
TIDL中需要进行量化的层有:
Convolution Layer、De-convolution Layer、Inner-Product Layer、Batch Normalization(Scale/Mul, Bias/Add, PReLU)
量化方法有两种,分别为:
后量化(post training quantization,PTQ) : 先训练浮点模型,然后使用校准图片计算量化参数,将浮点模型转为量化模型。
- 该方法简单、快捷,但将浮点模型直接转为量化模型难免会有一些量化损失,需要进行精度评估。
量化感知训练(quantization aware training,QAT) :在浮点训练的时候,就先对浮点模型结构进行干预,增加量化误差,使得模型能够感知到量化带来的损失。
- 该方法需要用户在全量训练集上重新训练,能有效地降低量化部署的量化误差。 一些社区框架都提供QAT方案,例如pytorch的eager mode方案、pytorch的fx graph方案、tf-lite量化方案等。
QAT训练是一种finetune方法,最好是在浮点结果已经拟合的情况下,再用QAT方法提升量化精度。 即用户的训练分为了两个步骤,先训练浮点模型,将模型精度提升到满意的指标;再通过QAT训练,提升量化精度。
为了让模型更好的感知到量化误差,QAT训练需要使用全量的训练数据集。 训练轮数和模型难度相关,大约是原来的浮点训练的1/10。 因为是在浮点模型上finetune,所以QAT训练的学习率尽量和浮点模型的最后几个epoch一致。
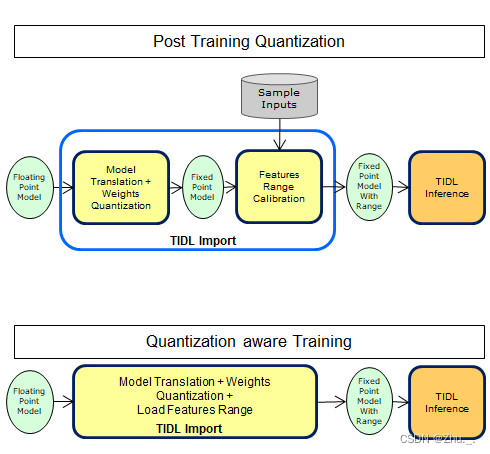
TIDL对两种量化方式(PTQ/QAT)都支持,并推荐使用PTQ方式,同时提供 PTQ方式下提升精度的指导 ,详见sdk描述:
./ti-processor-sdk-rtos-j721e-evm-08_05_00_11/tidl_j721e_08_05_00_16/ti_dl/docs/user_guide_html/md_tidl_fsg_quantization.html
经过模型转换的感知模型已经可以在板上运行,一般来说芯片供应商也会提供相应的工具链支持在PC端运行以debug。
性能评估
经TIDL导出模型后可在板上运行该模型以查看模型的性能表现,一般的关注点为:模型耗时、内存占用(可细致为模型运行每帧读取/存储的数据量)两方面。 针对TIDL,可通过配置导入时的参数 debugTraceLevel = 1 来输出模型运行结果,以下为输出示例:

其中,第一行Network Cycles为整个网络运行的cycle数,其后为网络每一层运行的cycle数,根据cycle数可计算得到模型的运算速度:
- Time-taken-per-frame (ms) = (1000 / C7x CPU clock in MHz) x (Number of mega cycles)
- FPS = 1 / Time-taken-per-frame
对于内存占用的情况,TIDL未给出测量的方法,需要借助其他手段进行观测。
性能调优
如果模型的性能无法达到要求,TIDL给出了如下 调优手段 :
./ti-processor-sdk-rtos-j721e-evm-08_05_00_11/tidl_j721e_08_05_00_16/ti_dl/docs/user_guide_html/md_tidl_fsg_steps_to_debug_performance.html
-
调节导入时的参数值msmcSize :该参数配置了可供模型使用的SRAM大小,该参数越小,即有越多的存储使用DDR,不利于性能表现;
-
在导入时的参数值perfSimConfig所配置的文件中,尝试调节ENABLE_PERSIT_WT_ALLOC的值;
-
检查在切换网络时是否调用TIDL_deactivate函数;
-
配置导入时的参数值numBatches,改善小分辨率网络的性能 (经TI测试,对于224x224的输入,批处理数量设置为4最优,可提升性能30%-50%)

除TIDL提供的针对性调优方法之外,还有一些通用性的调优方法:
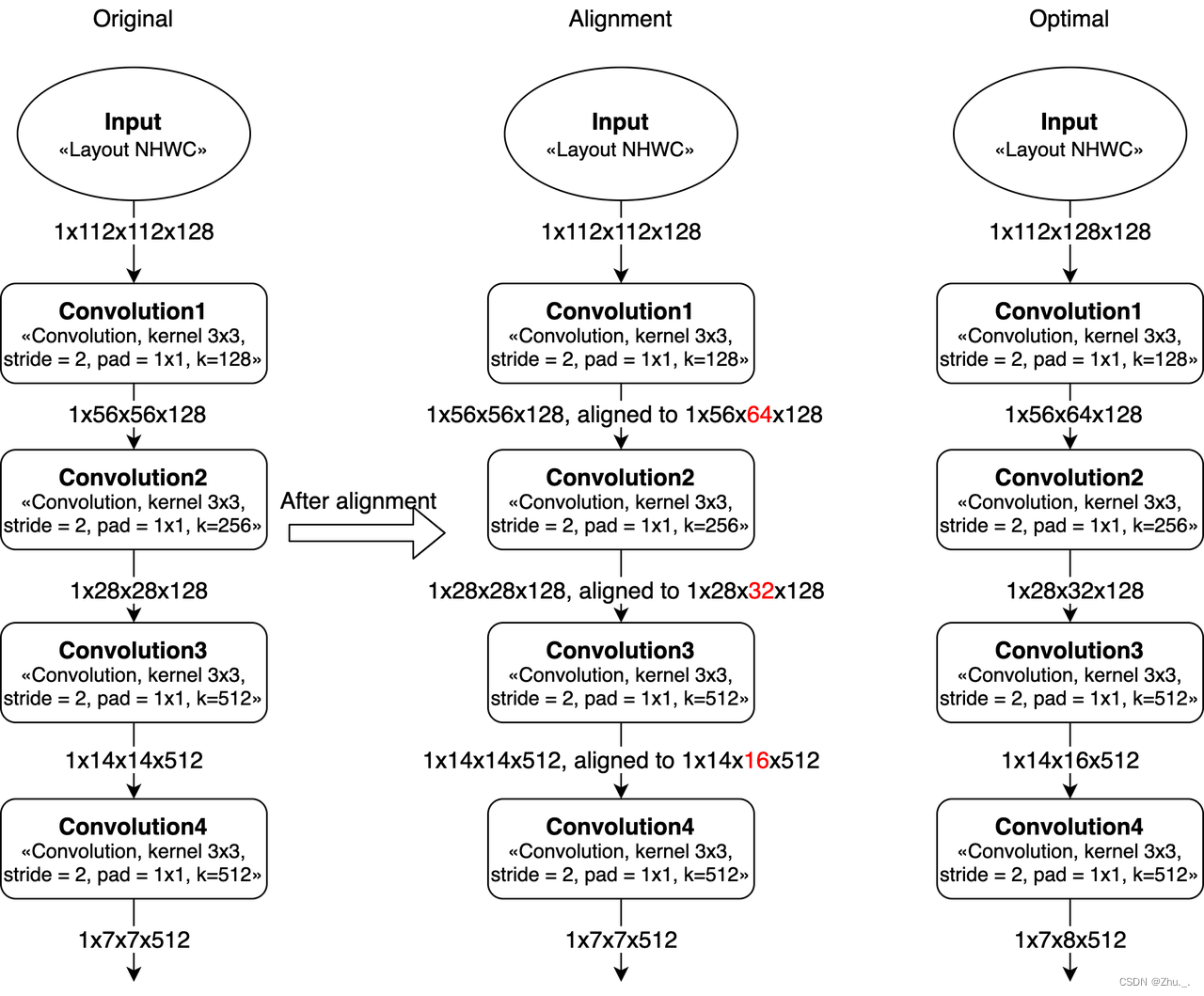
卷积的Width对齐
因为计算MAC阵列对齐要求的问题,featuremap的W在8对齐的时候效率会比较高(Convolution的stride=2时,W需要16对齐)。
如果不是8或16对齐,那么就会带来算力浪费,导致MAC利用率变低。
比如,如果convolution的输入feature大小是 1x8x9x32 (NHWC),那么在实际计算时,W会被padding到16(即feature大小变为1x8x16x32),会造成计算资源浪费。
在设计网络的时候,如果可以改变整个神经网络的输入大小(向上或向下对齐),那么模型的MAC利用率会直接提高。
卷积的Channel对齐
Channel在硬件上是需要8对齐的,在算法设计的时候最好将kernel num调整为8的倍数。
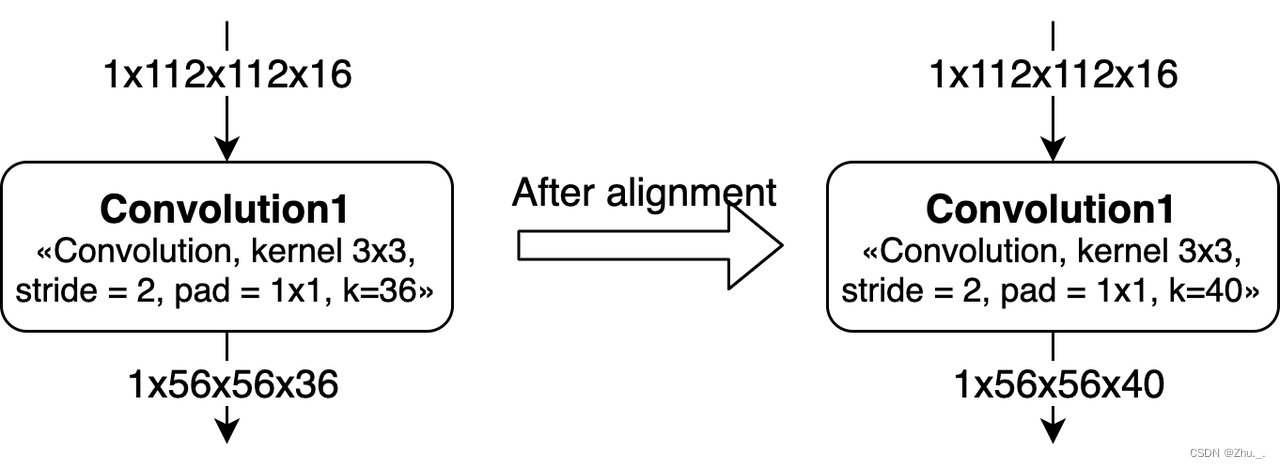
对于Group Convolution,channel的对齐情况会更加复杂一些。
如果Kernel不是8的整数倍,那么每个group的kernel num需要对齐到8。 而且,由于这个对齐,会导致之后的convolution也产生算力浪费。
模型调整
如经过性能调优后仍不能满足要求,则需要进行模型调整;
模型调整可通过以下两种途径进行:
-
更换骨干网络,选用轻量化模型;
-
进行模型压缩。
模型压缩除量化外还有如下方式:
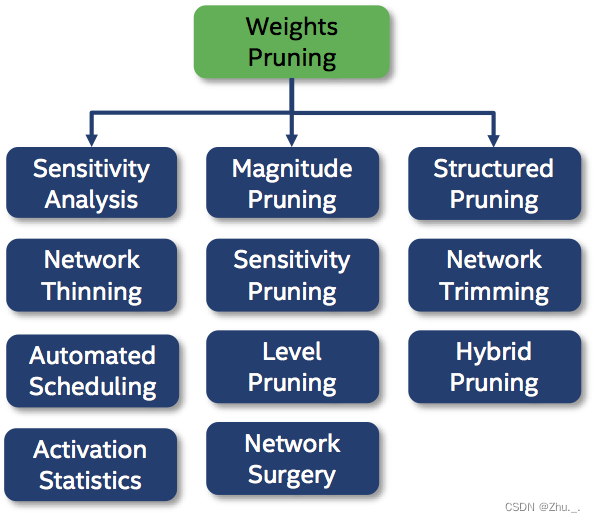
剪枝(Pruning)
剪枝涉及从训练网络中移除神经元或整个神经元、通道或过滤器之间的连接,这是通过将其权重矩阵中的值清零或完全移除权重组来完成的
非结构化剪枝涉及移除单个权重或神经元,而结构化剪枝涉及移除整个通道或过滤器
知识蒸馏(Knowledge Distillation)
背景:在训练期间,模型不必实时运行,也不一定面临计算资源的限制,因为其主要目标只是从给定数据中提取尽可能多的结构,但如果将其部署用于推理时,我们确实需要关注延迟和资源消耗
先训练大型“教师”网络,然后定义一个小型的“学生”网络;
小型“学生”网络通过最小化损失函数来学习模仿大型“教师”网络,其中目标基于教师的 softmax 函数输出的类概率分布
模型部署对视频切片的要求
对模型的性能评估可以得到模型的FPS参数,即目标网络每秒可以处理(检测)多少帧,输入视频的切片频率不得大于模型的FPS,如两者发生冲突,应尝试对模型进行性能调优。
精度评估
原始模型经算子匹配与量化后,会有一定的精度损失,在得到导入模型后可以运行该模型进行测试集识别,观察识别结果的精度是否满足需求;
精度评估的指标与对应的感知算法一致。
精度调优
如果精度评估结果无法满足要求,则需要进行 精度调优 。
针对TIDL,可按照如下流程:
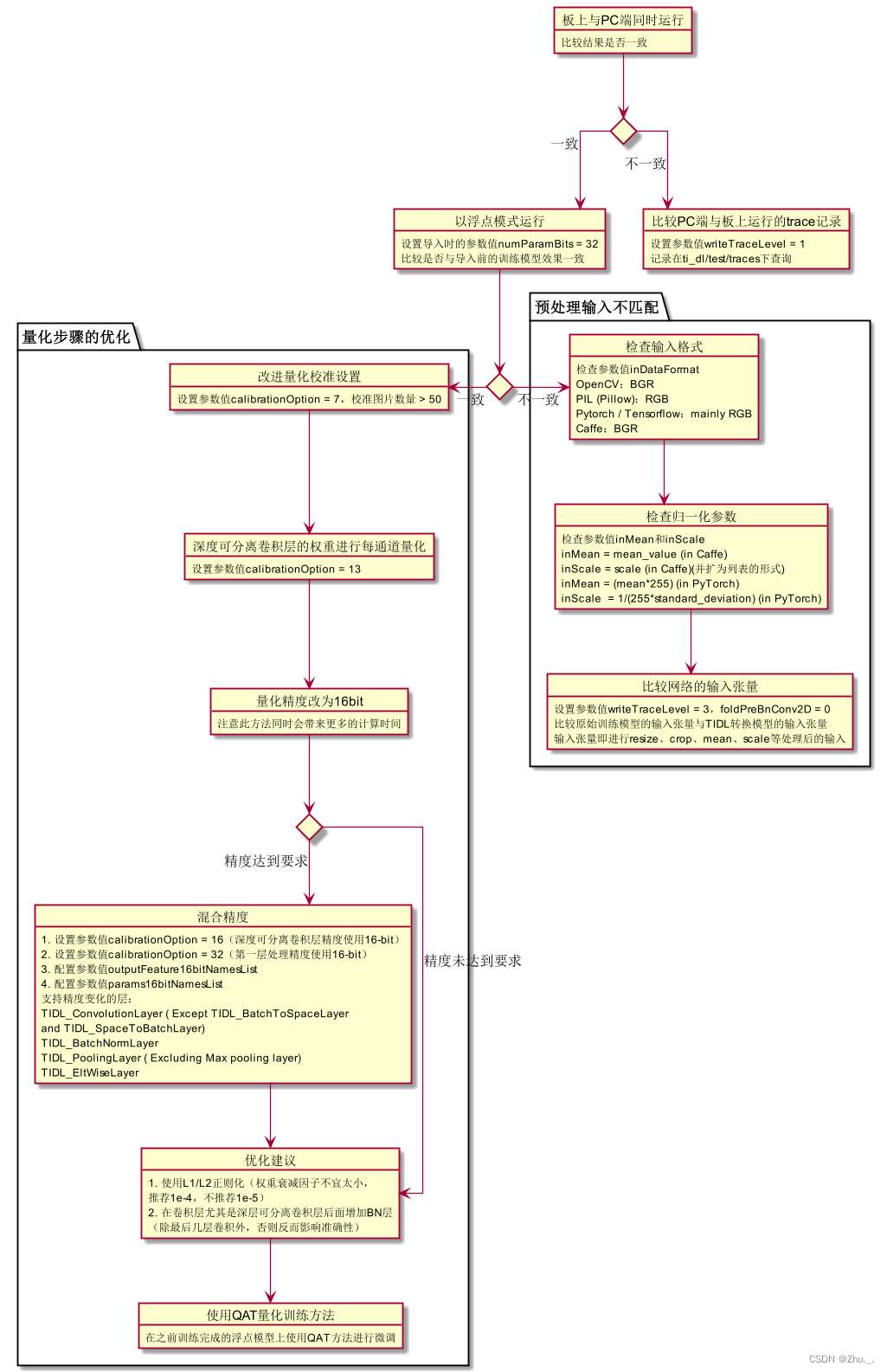
TI针对精度调优的文档详见sdk:
./ti-processor-sdk-rtos-j721e-evm-08_05_00_11/tidl_j721e_08_05_00_16/ti_dl/docs/user_guide_html/md_tidl_fsg_steps_to_debug_mismatch.html















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









