







链接
基础代码
自注意力机制网络结构
自注意力机制的网络结构如下:
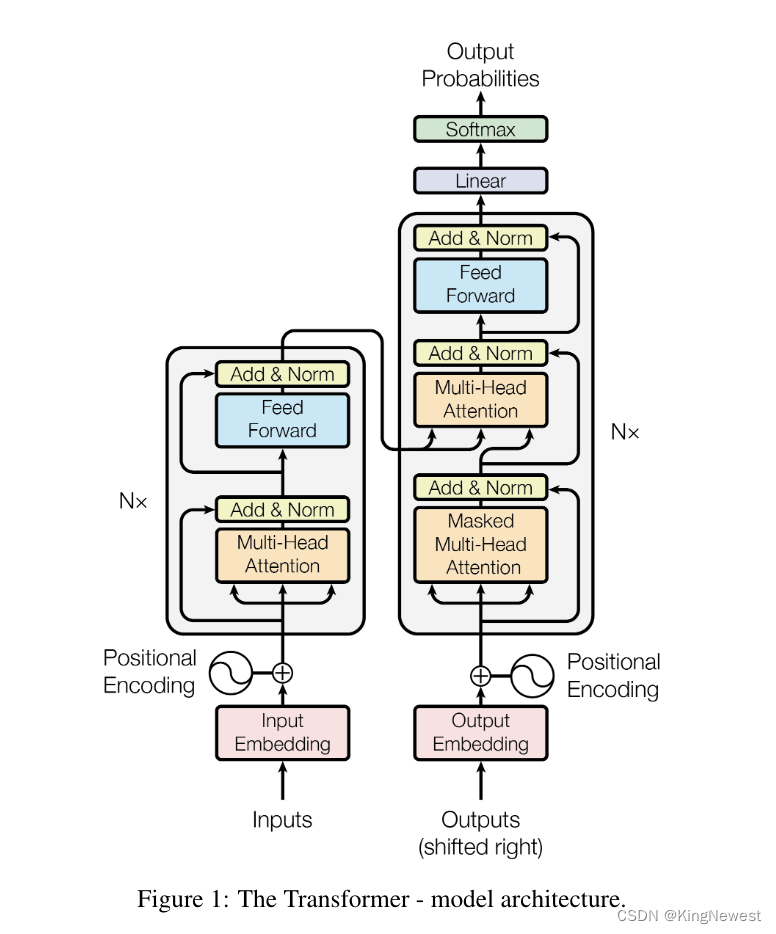
左侧为编码器,有六个相同的层组成,每层有两个子层;右侧为解码器,也由 N=6 个相同的层组成,每层包含三个子层。
编码器负责处理输入序列。它逐层转换输入数据,每一层都通过自注意力机制捕捉序列中不同位置间的关系。这样,编码器产生的最终输出包含了输入序列的全面表示,这些表示随后传递给解码器。
解码器负责生成输出序列。它逐层生成输出,同时利用编码器的输出来捕捉输入序列的相关信息。在序列生成过程中,解码器的自注意力层被修改以防止未来位置的信息泄露,确保每个位置的输出只依赖于之前的输出。
在训练过程中,首先将整个输入序列提供给编码器,编码器逐层处理序列并生成表示。然后,这些表示被传递给解码器。解码器根据编码器的输出以及到目前为止已生成的输出序列的信息,逐步生成输出序列
如果是分类任务,只用编码器就行
自注意力机制应用方法
torch.nn.TransformerEncoderLayer
编码器的最小单元(上面左图),一定需要定义
- d_model: 输入张量特征数(required).
- nhead: 多头自注意力机制的头数(required).
- dim_feedforward:全连接层的维数 (default=2048).
- dropout: the dropout value (default=0.1).
- activation: 激活函数 relu or gelu (default=relu).
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, dim_feedforward=256, nhead=2
)
torch.nn.TransformerEncoder:
上一个的升级版本,可以不定义,它包含了N个transformer encoder layers
- encoder_layer: 要用的layer(required).
- num_layers :sub-encoder-layers的数目(required).
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)
网络结构代码
class Classifier(nn.Module):
def __init__(self, d_model=80, n_spks=600, dropout=0.1):
super().__init__()
# 输入处理:输入特征数到自注意力模型要求的输入特征数
self.prenet = nn.Linear(40, d_model)
# 自注意力层:定义编码器的结构
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, dim_feedforward=256, nhead=2
)
# 输出处理:将自注意力机制的输出转化为分类数量
self.pred_layer = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2)
# 编码器期待 (length, batch size, d_model)格式的输入
# out: (length, batch size, d_model)
out = self.encoder_layer(out)
# out: (batch size, length, d_model)
out = out.transpose(0, 1)
# 沿着 length 维度的平均池化操作,所以后续的向量就少了一个维度
stats = out.mean(dim=1)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out
其余值得学习的东西
动态学习率及余弦退火算法
warm up
先采用这个算法,初期学习率是线性增长的
余弦退火算法
初期过后,学习率需要衰减
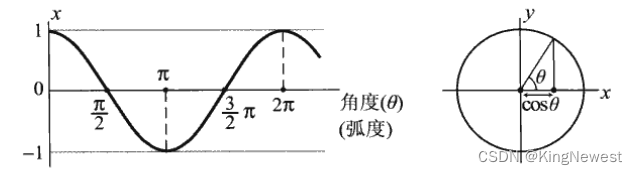
取了余弦函数中0~pi/2,实现学习率的衰减
代码
def get_cosine_schedule_with_warmup(
optimizer: Optimizer,
num_warmup_steps: int,
num_training_steps: int,
num_cycles: float = 0.5,
last_epoch: int = -1,
):
"""
用于调整学习率的函数,它创建了一个结合了warmup阶段和余弦退火调度的学习率调度器
Args:
num_warmup_steps:warm_up的步骤
num_training_steps:训练的步骤
num_cycles (defaults to 0.5):在余弦调度中的波形数量
last_epoch (defaults to -1):The index of the last epoch when resuming training.
"""
def lr_lambda(current_step):
# Warmup:如果当前步数小于warmup步数,学习率线性增加
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
# decadence 衰减
progress = float(current_step - num_warmup_steps) / float(
max(1, num_training_steps - num_warmup_steps)
)
# (math.cos(math.pi * float(num_cycles) * 2.0 * progress)) 根据训练进度计算一个介于-1到1之间的值,然后调整到0到1之间,乘以0.5以使最大学习率减半
return max(
0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress))
)
# 需要一个传入一个lambda函数,学习率等于初始学习率乘该函数的返回值
return LambdaLR(optimizer, lr_lambda, last_epoch)
调用
optimizer = AdamW(model.parameters(), lr=1e-3)
scheduler = get_cosine_schedule_with_warmup(optimizer, warmup_steps, total_steps)
# Updata model
# 学习率调度器 (scheduler) 负责根据预设的规则调整优化器 (optimizer) 中的学习率
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
Medium
主要涉及到几个参数的调整
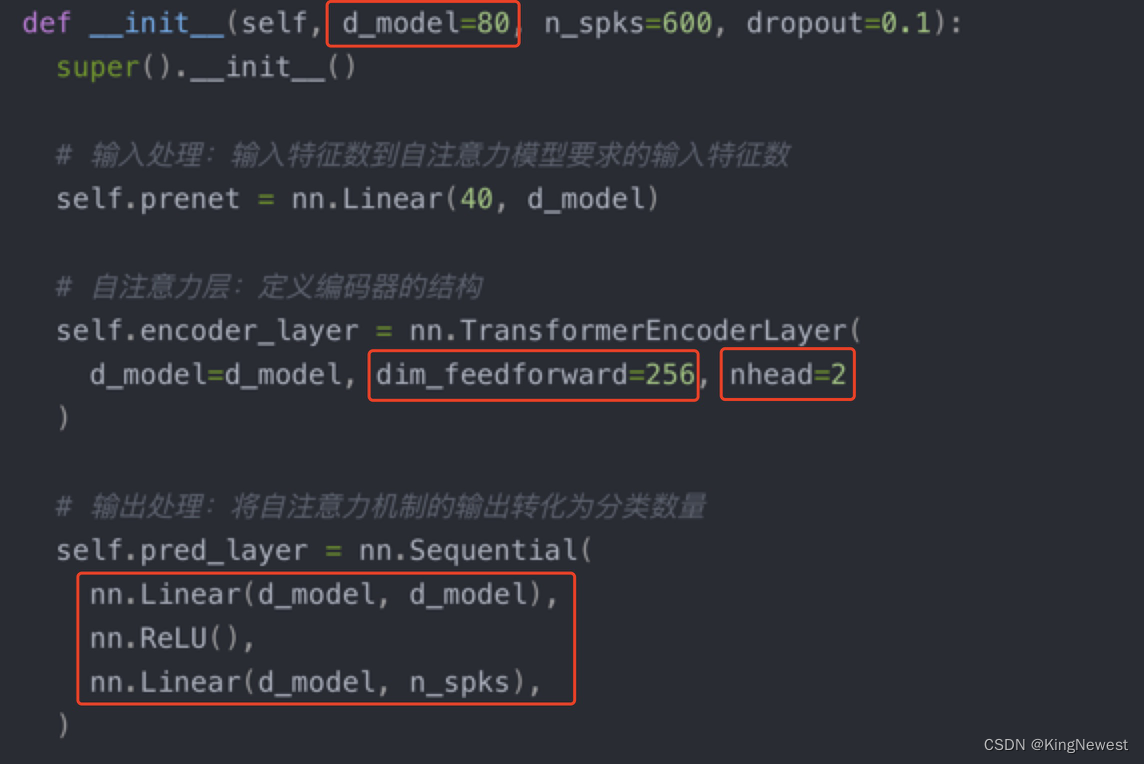
除此之外,可以多放几个自注意力层
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)
最后应用的模型
import torch
import torch.nn as nn
import torch.nn.functional as F
class Classifier(nn.Module):
def __init__(self, d_model=80, n_spks=600, dropout=0.1):
super().__init__()
# 输入处理:输入特征数到自注意力模型要求的输入特征数
self.prenet = nn.Linear(40, d_model)
# 自注意力层:定义编码器的结构
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, dim_feedforward=512, nhead=1
)
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)
# 输出处理:将自注意力机制的输出转化为分类数量
self.pred_layer = nn.Sequential(
# nn.Linear(d_model, d_model),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2)
# The encoder layer expect features in the shape of (length, batch size, d_model).
out = self.encoder(out)
# out: (batch size, length, d_model)
out = out.transpose(0, 1)
# mean pooling
stats = out.mean(dim=1)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out
结果

后来把d_models改成224,得到了更好的结果
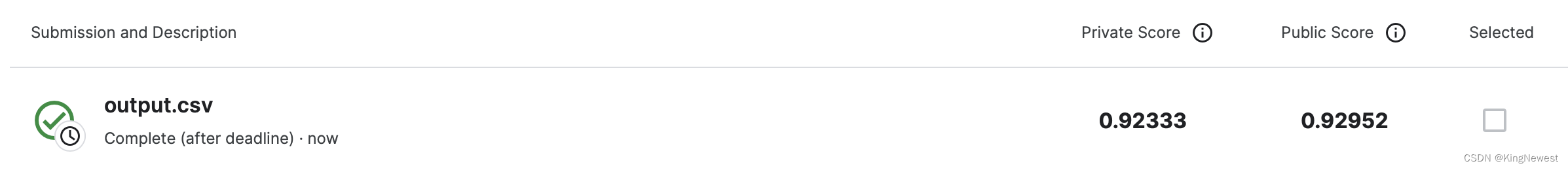
Hard
这里需要改变整个模型的结构,conformer
图示
网络的结构如下:
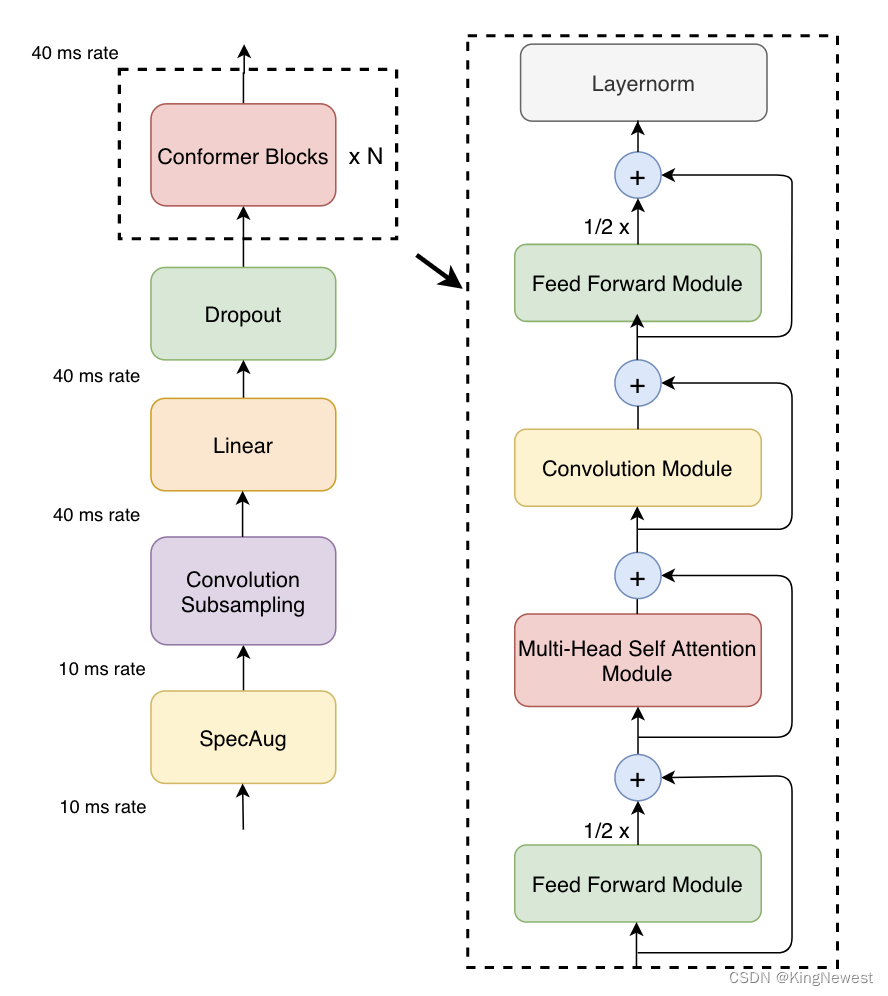
相比于之前使用的网络,其主要变化是 conformer blocks中增加了convolution module,它长下面这样:

当然,它给我们打包好了,知道怎么用就行
使用
首先要安装库
$ pip install conformer
然后直接用它里面的conformer block模块就可以了
import torch
import conformer
from conformer import Conformer
conformer = Conformer(
dim = 512, # 模型中每个层的输出特征数
depth = 12, # 模型中Conformer块的数量
dim_head = 64, # 自注意力机制中每个头的维度
heads = 8, # 头的数目
ff_mult = 4, # 前馈层中隐藏层大小相对于模型维度dim的倍数
conv_expansion_factor = 2, # 卷积层扩张因子,影响卷积层中间隐藏层的大小
conv_kernel_size = 31, # 卷积层的核大小
attn_dropout = 0.,
ff_dropout = 0.,
conv_dropout = 0., # 自注意力层、前馈网络层和卷积层中的dropout率
)
x = torch.randn(1, 1024, 512) # 对于上面的block块,期待的输入
conformer(x) # (1, 1024, 512)
效果不如之前















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









