







用s2s来完成机器翻译的工作。
这个代码要安装的库fairseq由于年代久远,有点兼容性问题,所以实际并没有跑代码,记录一下学习过程。
不涉及具体的代码,整理了一下encoder和decoder框架,结合了自注意力机制
基础代码
基础代码采用的是RNN的网络架构,它采用了双向RNN网络,结合了自注意力机制。
RNN
基本网络结构
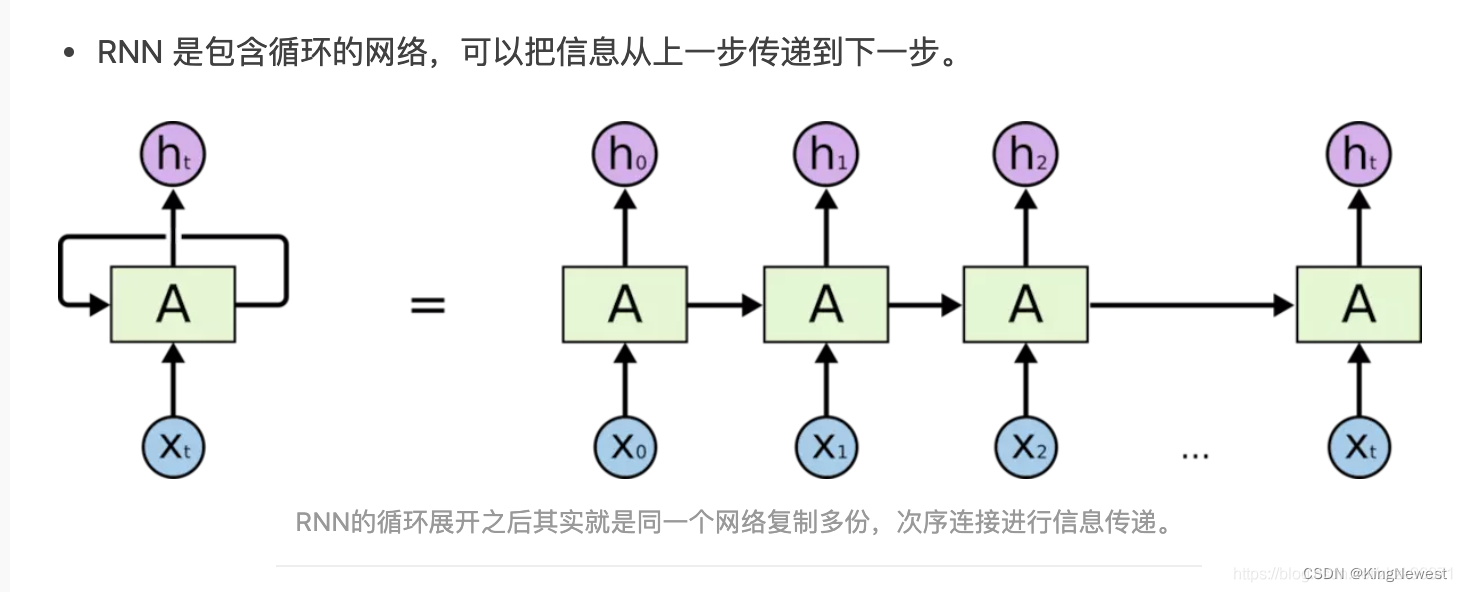
RNN的基本网络结构如下:
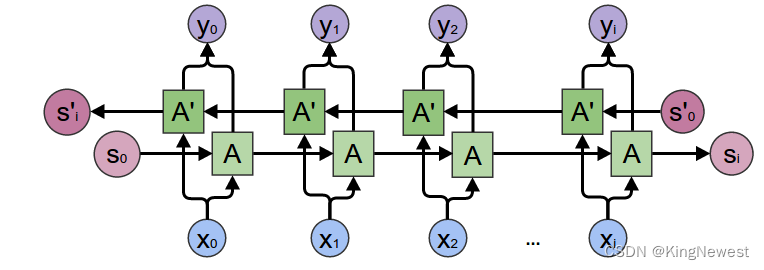
双向的RNN结构如下:
代码
Pytorch中有写好的RNN的代码,设置好参数就能直接调用:
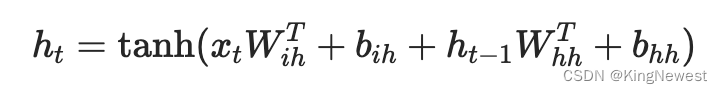
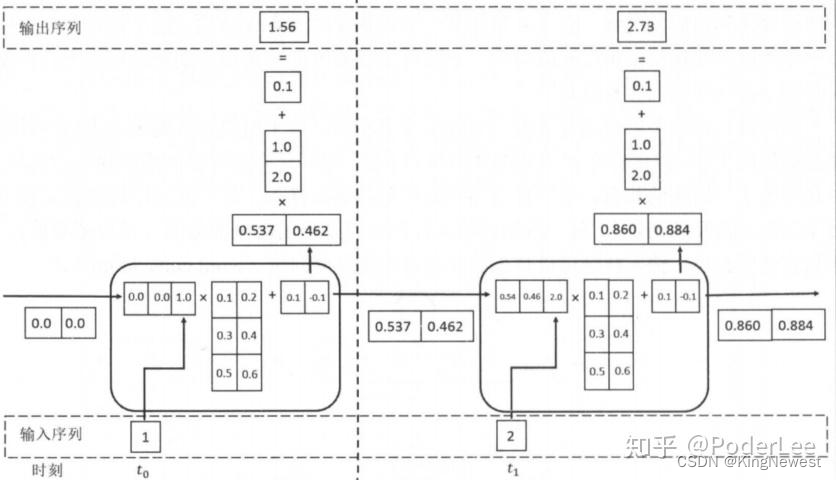
需要设置的参数及含义如下:
- input_size – input x 的特征数,RNN接收一个形状为(batch, input_size)的输入张量x
- hidden_size – 隐藏状态h的特征数量
- num_layers – 循环层的数量. Default: 1
- nonlinearity – 非线性激活函数的选择, ‘tanh’ or ‘relu’. Default: ‘tanh’
- bias – 是否使用偏置项。如果为False,RNN层将不使用偏置权重b_ih和b_hh 。Default: True
- batch_first –是否将输入和输出张量设置为(batch, seq, feature)的形式,而不是传统的(seq, batch, feature)形式。.Default: False
- dropout – Default: 0
- bidirectional – 是否使用双向RNN。Default: False
输入相关:
- input:输入序列的张量,其形状为(batch, seq, feature)或(seq, batch, feature)。其中,batch表示批次大小,seq表示时间步数,feature表示输入特征的数量。当使用可变长度序列时,输入可以是一个打包的变长序列。
- h_0:初始隐藏状态的张量,其形状为(Dnum_layers, batch, hidden_size)或(Dnum_layers, seq, batch, hidden_size)。其中,D表示双向RNN的方向数(如果是双向RNN),num_layers表示循环层的数量,hidden_size表示隐藏状态的特征数量。初始隐藏状态用于指定RNN在开始处理输入序列之前的初始状态值,默认为全零张量。
输出相关:
- output:RNN模型的输出张量,形状为(batch, seq, Dhidden_size)或(seq, batch, Dhidden_size)或(seq, batch, D*hidden_size)。其中,batch表示批次大小,seq表示时间步数,D表示双向RNN的方向数(如果是双向RNN),hidden_size表示隐藏状态的特征数量。输出包含了RNN最后一层的所有时间步的隐藏状态h_t。
- h_n:最终的隐藏状态张量,形状为(Dnum_layers, batch, hidden_size)或(Dnum_layers, seq, batch, hidden_size)。其中,D表示双向RNN的方向数(如果是双向RNN),num_layers表示循环层的数量,hidden_size表示隐藏状态的特征数量。h_n包含了每个输入元素的最终隐藏状态。
- weight_ih_l[k]:第k层的输入到隐藏状态的权重,形状为(hidden_size, input_size)。当k=0时,input_size表示输入特征的数量,否则(input_size, num_directions * hidden_size)。这些权重是可学习的参数。
- weight_hh_l[k]:第k层的隐藏状态到隐藏状态的权重,形状为(hidden_size, hidden_size)。这些权重是可学习的参数。
- bias_ih_l[k]:第k层的输入到隐藏状态的偏置项,形状为(hidden_size)。这些偏置项是可学习的参数。
- bias_hh_l[k]:第k层的隐藏状态到隐藏状态的偏置项,形状为(hidden_size)。这些偏置项是可学习的参数。
应用实例如下:
#########定义模型和输入#########
# (input_size, hidden_size, num_layers)
rnn = nn.RNN(10, 20, 1)
# (seq_len, batch_size, input_size)
input = torch.randn(5, 3, 10)
# (num_layers, batch_size, hidden_size)
h0 = torch.randn(1, 3, 20)
# 获取输出
output, hn = rnn(input, h0)
Encoder-Decoder框架
Seq2Seq模型的基本思想非常简单一一使用一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度(注意是固定维度,下文的注意力集中机制将在此做文章)的编码中;再使用另一个循环神经网络读取这个编码,将其“解压”为目标语言的一个句子。这两个循环神经网络分别称为编码器(Encoder)和解码器(Decoder)
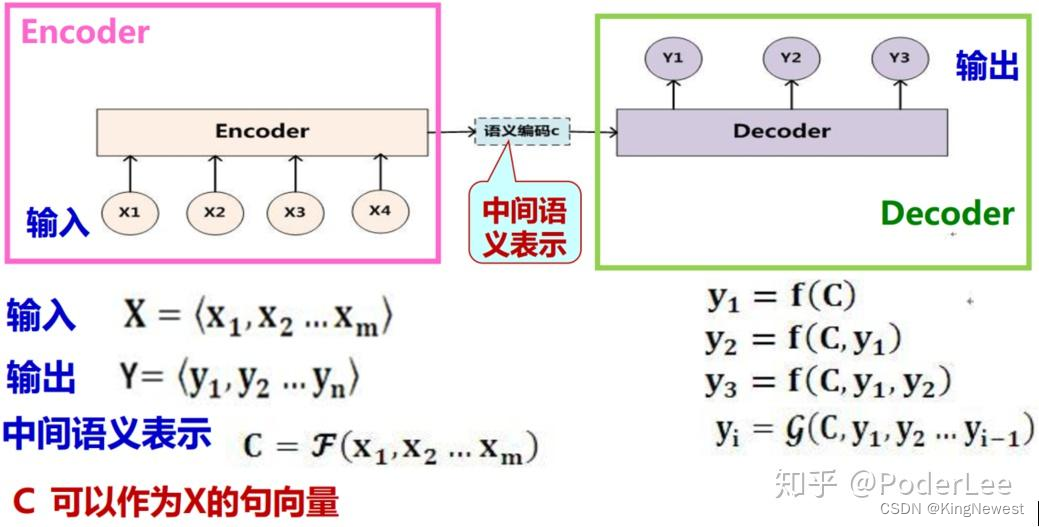
Decoder:根据x的中间语义表示和已经生成的y1~yi-1 来生成 i 时刻的 yi。解码器部分的结构与一般的语言模型几乎完全相同:输入为单词的词向量,输出为softmax层产生的单词概率,损失函数为log perplexity。事实上,解码器可以理解为一个以输入编码为前提的语言模型。语言模型中使用的一些技巧,如共享softmax层和词向量的参数,均可以直接应用到 Seq2Seq模型的解码器中。
Encoder:对输入序列
进行编码,通过非线性变换转化为中间语义表示
。编码器部分网络结构则更为简单。它与解码器一样拥有词向量层和循环神经网络,但是由于在编码阶段并未输出最终结果,因此不需要softmax层。
用GPT给的代码理解一下。
Encoder 类
class Encoder(nn.Module):
def __init__(self, input_size, embed_size, hidden_size, num_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(input_size, embed_size)
self.rnn = nn.GRU(embed_size, hidden_size, num_layers, dropout=dropout, batch_first=True)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, hidden = self.rnn(embedded)
return outputs, hidden
torch.nn.GRU
参数:
- input_dim 表示输入的特征维度
- hidden_dim 表示输出的特征维度,如果没有特殊变化,相当于out
- num_layers 表示网络的层数
- nonlinearity 表示选用的非线性**函数,默认是 ‘tanh’
- bias 表示是否使用偏置,默认使用
- batch_first 表示输入数据的形式,默认是 False,[即(序列长度seq,批大小batch,特征维度feature)];若True则(batch,seq,feature)
- dropout 缺省值为0,表示不使用dropout层;若为1,则除最后一层外,其它层的输出都会加dropout层
- bidirectional 表示是否使用双向的 rnn,默认是 False
输出:
out:[seq_len,batch_size,output_dim],所有输出
ht:[num_layers * num_directions, batch_size, hidden_size],num_directions=1,单向,取值2时为双向,num_layers为层数,最后一个输出
Attention
class Attention(nn.Module):
def __init__(self, hidden_size, num_heads, dropout):
super().__init__()
self.attention = nn.MultiheadAttention(hidden_size, num_heads, dropout=dropout)
def forward(self, query, key, value, mask):
attn_output, _ = self.attention(query, key, value, attn_mask=mask)
return attn_output
Decoder 类
class Decoder(nn.Module):
def __init__(self, output_size, embed_size, hidden_size, num_layers, dropout, num_heads):
super().__init__()
# 嵌入层将目标语言的单词索引转换为向量
self.embedding = nn.Embedding(output_size, embed_size)
# RNN处理拼接的嵌入向量和注意力上下文向量
self.rnn = nn.GRU(hidden_size + embed_size, hidden_size, num_layers, dropout=dropout, batch_first=True)
# 注意力层计算当前解码器隐藏状态和所有编码器输出之间的注意力
self.attention = Attention(hidden_size, num_heads, dropout)
# 线性层将RNN的输出映射到输出词汇表的大小
self.fc_out = nn.Linear(hidden_size, output_size)
# dropout用于正则化
self.dropout = nn.Dropout(dropout)
def forward(self, trg, hidden, encoder_outputs, src_mask):
# trg:当前的目标词索引
# hidden:解码器的上一个隐藏状态
# encoder_outputs:编码器的所有输出
# src_mask:源序列的掩码,用于注意力计算中忽略<pad> token
# trg增加一个维度,以符合RNN的输入要求
trg = trg.unsqueeze(1)
# 对目标词进行嵌入
embedded = self.dropout(self.embedding(trg))
# 计算注意力
attn_output = self.attention(embedded, encoder_outputs, encoder_outputs, src_mask)
# 将注意力输出和嵌入向量拼接作为RNN的输入
rnn_input = torch.cat((embedded, attn_output), dim=2)
# 通过RNN
output, hidden = self.rnn(rnn_input, hidden)
# 预测下一个词
prediction = self.fc_out(output.squeeze(1))
# 返回预测和新的隐藏状态
return prediction, hidden
Seq2Seq 类
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, src_pad_idx, device):
super().__init__()
# 初始化编码器和解码器
self.encoder = encoder
self.decoder = decoder
# 源序列中的<pad> token的索引
self.src_pad_idx = src_pad_idx
# 设备(CPU或GPU)
self.device = device
def create_mask(self, src):
# 创建掩码以忽略<pad> token
mask = (src != self.src_pad_idx).permute(1, 0)
return mask
def forward(self, src, trg):
# src:源序列
# trg:目标序列
# 对源序列进行编码
encoder_outputs, hidden = self.encoder(src)
# 为源序列创建掩码
src_mask = self.create_mask(src)
trg_len = trg.shape[1]
batch_size = trg.shape[0]
trg_vocab_size = self.decoder.embedding.num_embeddings
# 初始化一个存储预测结果的tensor
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size).to(self.device)
# 解码器的初始输入是目标序列的第一个词
input = trg[:, 0]
for t in range(1, trg_len):
# 对每个时间步进行解码
output, hidden = self.decoder(input, hidden, encoder_outputs, src_mask)
# 存储预测结果
outputs[:, t] = output
# 获取概率最高的词作为下一个输入
top1 = output.argmax(1)
input = top1
# 返回所有时间步的预测结果
return outputs
写到这里还是云里雾里,打算先放一放















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









