







要用到的链接
基础代码说明
基础代码应该是pdf中提到的“Medium baseline”,增加了几个层,考虑了n frame
它采用的Adam优化器可以自动调整学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
网络结构修改
主要修改
- 将激活函数改成了ReLU,效果会比Sigmod好很多
- 修改后,收敛太快,训练集正确率增长但是验证集正确率很快停止变化,因此添加了BatchNorm和Dropout,并将训练轮数改成了40轮
修改后的网络结构如下:
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.layer1 = nn.Linear(429, 1024)
self.bn1 = nn.BatchNorm1d(1024)
self.layer2 = nn.Linear(1024, 512)
self.bn2 = nn.BatchNorm1d(512)
self.layer3 = nn.Linear(512, 128)
self.bn3 = nn.BatchNorm1d(128)
self.out = nn.Linear(128, 39)
self.act_fn = nn.ReLU()
self.dropout = nn.Dropout(p=0.3)
def forward(self, x):
x = self.layer1(x)
x = self.bn1(x)
x = self.act_fn(x)
x = self.dropout(x)
x = self.layer2(x)
x = self.bn2(x)
x = self.act_fn(x)
x = self.dropout(x)
x = self.layer3(x)
x = self.bn3(x)
x = self.act_fn(x)
x = self.dropout(x)
x = self.out(x)
return x
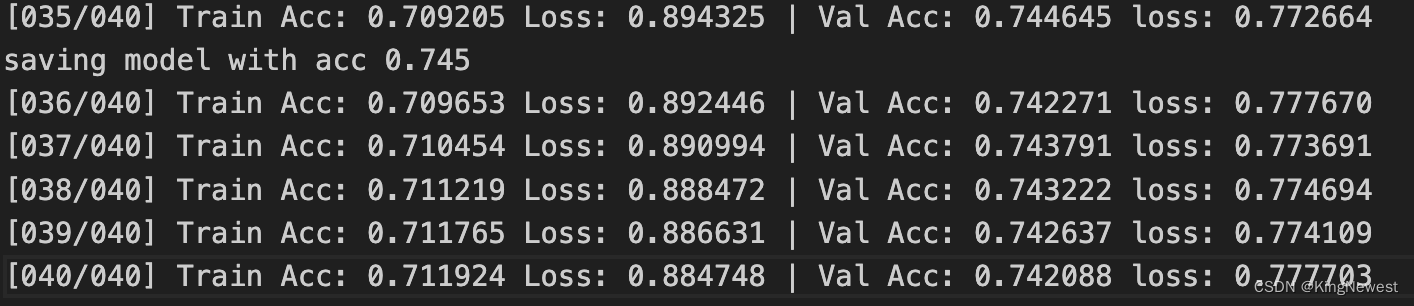
训练效果
40轮训练后在验证集上的正确率在0.745左右,对比发现,训练集的正确率依然在缓慢上升,但验证集的正确率开始波动
在平台上提交,结果如下:
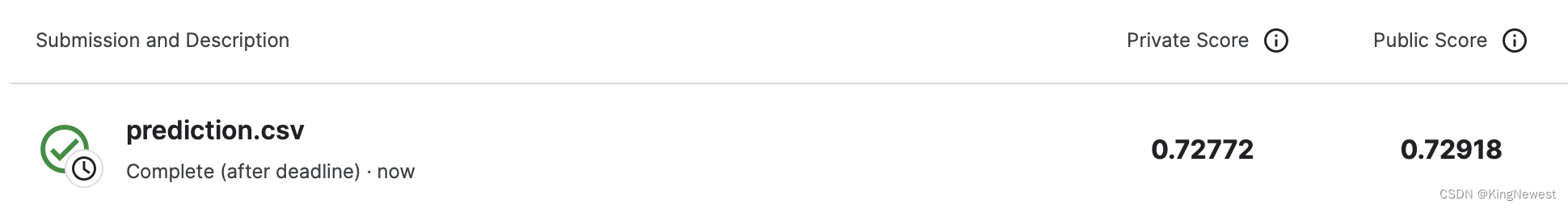
进一步尝试
最后模型应该出现了过拟合,尝试调整dropout的概率为0.5,增加训练轮数为80,结果好不来一点。光影响我吃中饭了
















 4036
4036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









