




 这篇博客详细介绍了传统神经网络,从线性回归的梯度下降法开始,探讨了非线性激励的重要性,包括sigmoid、tanh、ReLU和Leaky ReLU函数。接着,讲解了神经网络中的损失函数、学习速率和动量等关键概念,以及防止过拟合的策略,如正则化和dropout。最后,提到了在Mnist数据集上实现神经网络模型进行手写数字识别的例子。
这篇博客详细介绍了传统神经网络,从线性回归的梯度下降法开始,探讨了非线性激励的重要性,包括sigmoid、tanh、ReLU和Leaky ReLU函数。接着,讲解了神经网络中的损失函数、学习速率和动量等关键概念,以及防止过拟合的策略,如正则化和dropout。最后,提到了在Mnist数据集上实现神经网络模型进行手写数字识别的例子。
传统神经网络
1. 线性回归
梯度下降法
- 总结:
随机初始化参数;
开启循环:t = 0, 1, 2 …
带入数据求出结果: y^t
与真值作比较得到: loss=y−y^t
对各个变量求导得到 Δm
Δm=[x1,t,x2,t,x3,t,1]
更新变量 m :m:=m−ηΔm
如果 loss足够小或 t$循环结束,则停止
2. 线性到非线性
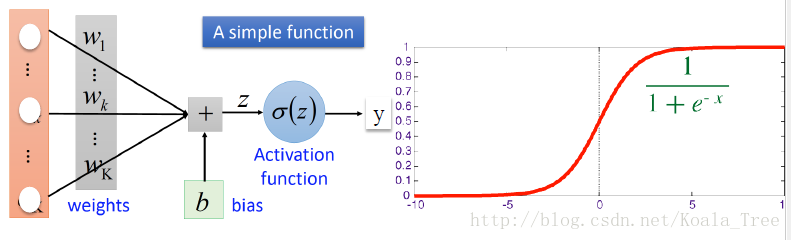
评价非线性激励的两个标准
- 正向对输入的调整
- 反向梯度损失
常用的非线性激励函数
sigmoid函数
y(x)=sigmoid(x)=11+e−xy(x)′=y(x)(1−y(x))
由图可以知道,当导数最大时, x=0 ,此时 y(x)=0.5 , y(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









