







文章目录
Introduction
之前所使用的算法一般都是使用字典或者查表的方法才存储价值函数。
- 每一个状态都有一个V(s)
- 每一个状态行为价值对都有一个Q(s,a)
在处理大规模的MDPs问题时,有很多状态或者行为需要存储在内存中,去查找和存储的开销特别大。
如何解决这种大规模的MDPs问题呢?如果有一个估计价值的函数,那么就用存储了,现用现算
- 使用Estimate value function 来估计状态价值。
v ^ ( s , w ) ≈ v π ( s ) o r q ^ ( s , a , w ) ≈ q π ( s , a ) \hat v (s,w) \approx v_\pi(s) \\ or \quad \hat q(s,a,w) \approx q_\pi(s,a) v^(s,w)≈vπ(s)orq^(s,a,w)≈qπ(s,a)
w是一个参数,通过MC或者TD学习来更新它。通过调整w,使得估计出来的和实际的近似。
从可见的状态可以推广到不可见的状态。
通过Estimate value function , 那么强化学习的任务就转变成了求解近似参数w的问题了。
如何选择Function Approximator?
有许多function approximators, 例如:
- Linear combination of features;
- Neural network;
- Decision tree;
- Nearest neighbour;
- Fourier / wavelet bases;
- …
Incremental Methods
我们问题转化成了求解进近似参数w。
Gradient Descent
设
J
(
w
)
J(w)
J(w)是w的cost function,代表w和最理想的值之间的差距。使用梯度下降的方法逼近最优w。
J
(
w
)
=
1
2
E
π
[
(
v
π
(
s
)
−
v
^
(
s
,
w
)
)
2
]
=
1
2
n
∑
i
=
1
n
(
v
π
(
s
)
(
i
)
−
v
^
(
s
,
w
)
(
i
)
)
2
i
代
表
第
i
个
e
x
a
m
p
l
e
\begin{aligned} J(w) &= \frac{1}{2}\mathbb E_{\pi}[(v_\pi(s) - \hat v(s,w))^2] \\ &= \frac{1}{2n} \sum_{i=1}^{n}(v_\pi(s)^{(i)} - \hat v(s,w)^{(i)})^2 \quad i代表第i个example \end{aligned}
J(w)=21Eπ[(vπ(s)−v^(s,w))2]=2n1i=1∑n(vπ(s)(i)−v^(s,w)(i))2i代表第i个example
v π ( s ) v_\pi (s) vπ(s)是实际的值
v ^ ( s , w ) \hat v (s,w) v^(s,w)是估计的值
J(w)是实际的值与估计值偏差平方 的数学期望。 (最小二乘法)
乘以1/2是为了求偏导消去产生的2
梯度的方向是 J ( w ) J(w) J(w)上升速度最快的方向。(其实是把上升速度最快的方向定义成了梯度)
J(w)的梯度:就是对w里的每个维度都求偏导。
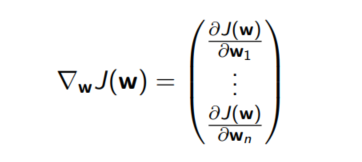
我们想让J(w)不断迭代变小,就需要使用梯度的反方向,也就是下降最快的方向。
每次w更新的大小(
w
←
w
+
△
w
w \leftarrow w + \triangle w
w←w+△w):
△
w
=
α
∇
w
J
(
w
)
=
α
E
π
[
(
v
π
(
S
)
−
v
^
(
S
,
w
)
)
∇
w
v
^
(
S
,
w
)
]
=
α
1
n
∑
i
=
1
n
(
v
π
(
S
)
(
i
)
−
v
^
(
S
,
w
)
(
i
)
)
∇
w
v
^
(
S
,
w
)
(
i
)
\triangle w = \alpha \nabla_w J(w) \\ = \alpha \mathbb E_\pi [(v_{\pi}(S) - \hat v (S,w)) \nabla_w \hat v(S,w)]\\ = \alpha \frac {1}{n} \sum_{i=1}^n (v_{\pi}(S)^{(i)} - \hat v (S,w)^{(i)}) \nabla_w \hat v(S,w)^{(i)}
△w=α∇wJ(w)=αEπ[(vπ(S)−v^(S,w))∇wv^(S,w)]=αn1i=1∑n(vπ(S)(i)−v^(S,w)(i))∇wv^(S,w)(i)
α \alpha α是步长
i是第i个example
以上的公式由于需要求数学期望,在内存中,在更新某一个维度的信息时,需要存储所有的n个example的信息。
数学期望= 试验中每次可能结果的概率乘以其结果的总和。
随机梯度下降(Stochastic gradient)解决了每次迭代需要存储所有example的信息的问题。为大规模的高纬度训练提供了可能。每次迭代只使用一个example。
△
w
=
α
(
v
π
(
S
)
−
v
^
(
S
,
w
)
)
∇
w
v
^
(
S
,
w
)
\triangle \bf w = \alpha(v_\pi (S) - \hat v(S,w)) \nabla_w \hat v(S,w)
△w=α(vπ(S)−v^(S,w))∇wv^(S,w)
还有介于两者之间的批量梯度下降。batch- gradient
特征向量的形式
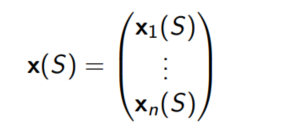
Linear Value Function Approximation线性价值估计函数
使用线性函数来估计价值:
v
^
(
S
,
w
)
=
x
(
S
)
T
w
=
∑
j
=
1
n
x
j
(
S
)
w
j
\hat v(S,w) = \bf x(S)^T \mathbb w = \sum_{j=1}^n \bf x_j(S)w_j
v^(S,w)=x(S)Tw=j=1∑nxj(S)wj
以w为参数变量的目标函数(此处可以乘1/2)
J
(
w
)
=
E
π
[
(
v
π
(
S
)
−
x
(
S
)
T
w
)
2
]
J(\bf w) = \mathbb E_{\pi} [(v_\pi(S) - x(S)^T \bf w)^2]
J(w)=Eπ[(vπ(S)−x(S)Tw)2]
根据随机前面梯度下降(Stochastic gradient descent)更新规则:
△ w = α ( v π ( S ) − v ^ ( S , w ) ) ∇ w v ^ ( S , w ) \triangle w = \alpha(v_\pi (S) - \hat v(S,w)) \nabla_w \hat v(S,w) △w=α(vπ(S)−v^(S,w))∇wv^(S,w)
-
v ^ \hat v v^的梯度: ∇ w v ^ ( S , w ) = x ( S ) \nabla_{\bf w } \hat v(S,\bf w) = \bf x(S) ∇wv^(S,w)=x(S)
-
w的更新量: △ w = α ( v π ( S ) − v ^ ( S , w ) ) ∗ x ( S ) \triangle \bf w = \alpha(v_\pi(S) - \hat v(S,\bf w)) *\bf x(S) △w=α(vπ(S)−v^(S,w))∗x(S)
正确结果
使用supervised learning方法来近似,然而我们并不知道target: v π ( S ) v_\pi(S) vπ(S)。在RL中只有奖励。
在实际应用中,我们使用其他来代替target。
△
w
=
α
(
t
a
r
g
e
t
−
v
^
(
S
t
,
w
)
)
∇
w
v
^
(
S
t
,
w
)
\triangle \bf{w} = \alpha(target - \hat v(S_t, \bf {w})) \nabla_w \hat v(S_t, \bf {w})
△w=α(target−v^(St,w))∇wv^(St,w)
-
对于MC类,target是return(收获) G t G_t Gt
- MC算法收敛到局部最优解。即使使用非线性的估计函数
- G t G_t Gt是无偏差的
-
对于TD(0),target是TD target: R t + 1 + γ v ^ ( S t + 1 , w ) R_{t+1} +\gamma \hat v(S_{t+1}, \bf{w}) Rt+1+γv^(St+1,w)
- TD-target 和最优价值函数$v_\pi(S) $是有偏差的,但应用在此处效果也很好。
- TD(0)收敛于(接近)全局最优
-
对于 T D ( λ ) TD(\lambda) TD(λ), target是 λ \lambda λ-return(收获) G t λ G_t^\lambda Gtλ
-
λ
−
r
e
t
u
r
n
\lambda-return
λ−return
G
t
λ
G_t^\lambda
Gtλ也是和真正的
v
π
(
S
)
v_\pi(S)
vπ(S)有偏差,可以应用于训练数据

-
λ
−
r
e
t
u
r
n
\lambda-return
λ−return
G
t
λ
G_t^\lambda
Gtλ也是和真正的
v
π
(
S
)
v_\pi(S)
vπ(S)有偏差,可以应用于训练数据
Batch Methods
- 梯度下降简单易用,但是没有充分利用采样
- Batch Methods为了根据所给的agent的经验,从而找到最适合的value function
Least Squares Prediction

Experience Replay
给出一些列的状态价值对:
D
=
{
<
s
1
,
v
1
>
,
.
.
.
.
<
s
T
,
v
T
>
}
\mathcal D = \{<s_1, v_1>, .... <s_T,v_T>\}
D={<s1,v1>,....<sT,vT>}
重复以下步骤:
-
选取从经验中选取一定数量的 <state,value>
-
使用随机梯度算法来更新参数
△ w = α ( v π ( S ) − v ^ ( S , w ) ) ∇ w v ^ ( S , w ) \triangle \bf w = \alpha(v_\pi (S) - \hat v(S,w)) \nabla_w \hat v(S,w) △w=α(vπ(S)−v^(S,w))∇wv^(S,w)
可以收敛到最小二乘法的解
w
π
=
arg
m
i
n
w
L
S
(
w
)
{\bf w}^\pi = \arg min_{\bf w} LS({\bf w})
wπ=argminwLS(w)
DQN (Deep Q-Networks)
Q-learning更新公式:
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
(
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
′
)
−
Q
(
S
t
,
A
t
)
)
Q(S_t, A_t) \leftarrow Q(S_t,A_t) + \alpha (R_{t+1} + \gamma Q(S_{t+1}, A') - Q(S_t,A_t))
Q(St,At)←Q(St,At)+α(Rt+1+γQ(St+1,A′)−Q(St,At))
A’是根据借鉴策略来的。
借鉴策略如果是贪婪策略,那么可化简:
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
(
R
t
+
1
+
γ
max
a
′
Q
(
S
s
+
1
,
a
′
)
−
Q
(
S
t
,
A
t
)
)
Q(S_t, A_t) \leftarrow Q(S_t,A_t) + \alpha (R_{t+1} + \gamma\max_{a'} Q(S_{s+1}, a') - Q(S_t,A_t))
Q(St,At)←Q(St,At)+α(Rt+1+γa′maxQ(Ss+1,a′)−Q(St,At))
α \alpha α: 学习率,决定每次的更新量。 α \alpha α过小,会导致过于注重之前的知识,导致学习的太慢。过大,则会导致过于在乎新的学习,忘记之前的经验积累。
γ \gamma γ:预测出来的下一个状态Q值对当前的影响。范围(0,1)
如果 $ \alpha = 1$ ,那么上式(这一步的推导和贝尔曼方程有关)
Q
(
S
t
,
A
t
)
←
R
t
+
1
+
γ
max
a
′
Q
(
S
s
+
1
,
a
′
)
Q(S_t, A_t) \leftarrow R_{t+1} + \gamma\max_{a'} Q(S_{s+1}, a')
Q(St,At)←Rt+1+γa′maxQ(Ss+1,a′)
这就是我们每次的Q值更新公式。我们的需要一个网络能够拟合出这个Q值的计算过程。这个网络的输入参数为state,输出参数为每个action在该状态下的Q值。这个网络就是Q网络。
当然,我们在训练时,每次的迭代目标target就是通过上式计算出来的。我们希望网络产生的数据和我们target相同
t
a
r
g
e
t
=
R
t
+
1
+
γ
arg
max
Q
(
S
t
+
1
,
a
)
target = R_{t+1} + \gamma \arg \max Q(S_{t+1},a)
target=Rt+1+γargmaxQ(St+1,a)

一些DQN的升级
Nature DQN
可以理解成两个网络Q和Q‘
Q负责产生动作。Q’负责在训练(replay)Q时,计算target值。Q’ 的权重是直接从Q中复制过来的。自己本省不进行训练。
Double DQN
为了解决Over Estimate问题。这个问题的根源是因为使用贪婪算法。
有两个Q网络。一个立刻更新,一个延迟更新。
Dueling DQN
相比Double DQN,后面多了两个子网络,分别对应价值函数部分和优势函数部分。然后累加得到输出层。
使用Huber loss
是一个带参数的损失函数,和之前的用的均方误差损失函数(MSE, mean square error)相比,对于噪声(离群点)不敏感。所以有很好的适应性。
计算公式
L
δ
=
{
1
2
e
2
,
∣
e
∣
≤
δ
δ
(
∣
e
∣
−
1
2
δ
)
,
o
t
h
e
r
w
i
s
e
L_\delta = \begin{cases} \frac{1}{2} e^2 , |e| \leq \delta \\ \delta(|e| - \frac{1}{2}\delta), otherwise \end{cases}
Lδ={21e2,∣e∣≤δδ(∣e∣−21δ),otherwise
e是预测值与target之间的偏差。
δ \delta δ是一个界限














 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









