






#示例2:将示例1读取的 Excel 文件内容,写入到另一个Excel中,对学校所在省份进行简单判断。第一行合并单元格显示标题。
#(1)导入模块:xlwt
import xlrd
import xlwt
#(2)读取文件内容
def read_excel(file_name): #定义读取文件函数
wb = xlrd.open_workbook(file_name) #创建读取文件的对象wb
sheet = wb.sheet_by_index(0)
schools = []
for row in range(sheet.nrows):
school = []
for col in range(sheet.ncols):
content = sheet.cell_value(row,col)
school.append(content)
schools.append(school)
return schools #提供返回值
#(3)写入文件内容
def write_excel(schools): #定义写入文件函数
#(2)构造工作簿:Workbook
wb = xlwt.Workbook(encoding = 'utf-8') #创建写入文件的对象wb
#(3)为工作簿添加表单:Worksheet
s = wb.add_sheet('上海市高校信息表') #创建一个表单
#(4)根据行列序号写入内容
#添加文本的样式(字体和对齐)
font = xlwt.Font() #字体
font.bold = True
font.height = 400
font.underline = True
font.colour_index = 6 #0:黑,1:白,2:红,3:绿,4:蓝,5:黄,6:紫
align = xlwt.Alignment() #对齐
align.horz = 2 #水平居中 1:左,2:中,3:右
align.vert = 1 #垂直居中 0:上,1:中,2:下
style = xlwt.XFStyle() #样式
style.font = font
style.alignment = align
s.write_merge(0,0,0,6,'上海市高校信息表',style) #写表标题并合并单元格(A1:A7)
for col in range(7): #写表列表名称
s.write(1,col,schools[0][col]) #第2行第1列开始写内容school[0][col]
row_num = 2 #从第3行开始写数据
for school in schools: #一行一行写数据内容
if school[2] == '上海市':
for col in range(7):
s.write(row_num,col,school[col])
row_num = row_num + 1
#(5)保存文件内容
wb.save('../R&Q_pic/上海市高校信息表.xls')
school_list = read_excel('../Stu_pack/wordcloud/school.xls') #调用读取函数,将素材里的文件school.xls作为实参传递给形参
write_excel(school_list) #调用写入函数,将读取的数据作为实参传递给形参写入到文件"上海市高校信息表.xls"里保存
schools_list = read_excel('../R&Q_pic/上海市高校信息表.xls')
i=1
for school in schools_list:
if i<13:
print(school)
i+=1
['上海市高校信息表', '', '', '', '', '', ''] ['招生单位代码', '招生单位名称', '所在省份', '是否985', '是否211', '是否自主划线', '学校类型'] ['10246', '复旦大学', '上海市', '是', '是', '是', '综合类'] ['10247', '同济大学', '上海市', '是', '是', '是', '理工类'] ['10248', '上海交通大学', '上海市', '是', '是', '是', '综合类'] ['10251', '华东理工大学', '上海市', '否', '是', '否', '理工类'] ['10252', '上海理工大学', '上海市', '否', '否', '否', '理工类'] ['10254', '上海海事大学', '上海市', '否', '否', '否', '理工类'] ['10255', '东华大学', '上海市', '否', '是', '否', '理工类'] ['10256', '上海电力学院', '上海市', '否', '否', '否', '理工类'] ['10259', '上海应用技术大学', '上海市', '否', '否', '否', '理工类'] ['10264', '上海海洋大学', '上海市', '否', '否', '否', '农林类']
一、用pandas读写excel文件
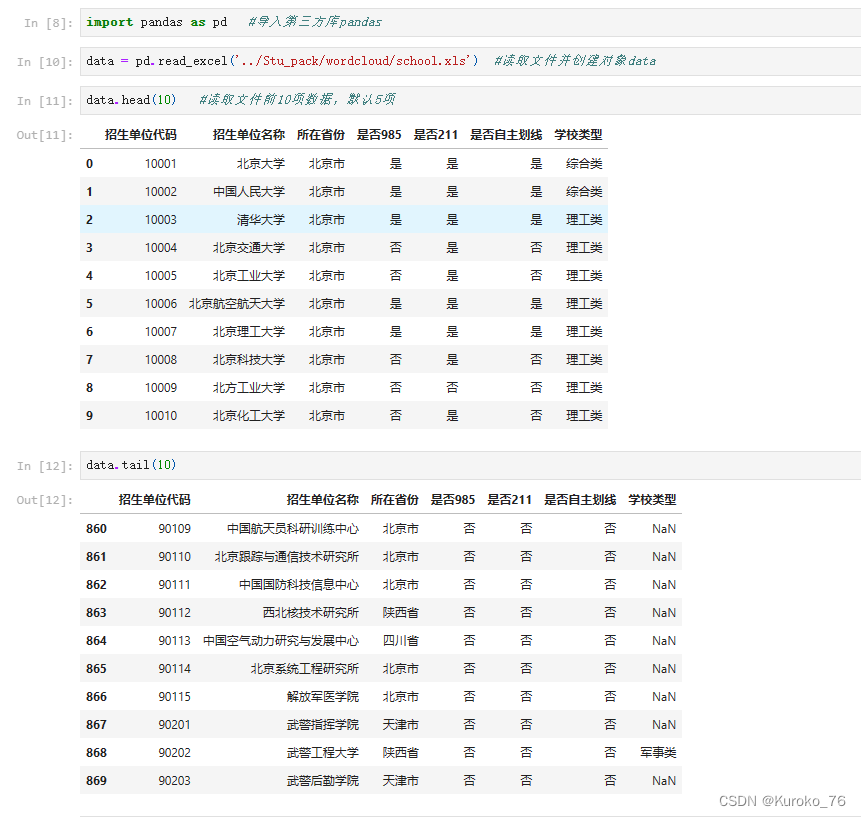
#读取所在省份为上海市的数据
data=data[data['所在省份']=='上海市']
#将上面的数据写入到‘R&Q_pic’文件夹,文件名为‘上海市高校信息.xls’
data.to_excel('../R&Q_pic/上海市高校信息.xls')
二、词云库wordcloud的安装与应用
1、安装
pip install wordcloud #网络安装
python -m pip install 本地路径 #本地安装
2、应用
生成步骤:
创建云对象-->加载词云文本-->输出词云图片(文件)
(1)默认的矩形词云图片
(2)提供的图形词云图片#示例1:生成默认的矩形词云图(原文件为英文)
import wordcloud #(1)导入词云库
from PIL import Image #导入图片库
with open('../Stu_pack/wordcloud/万疆.txt',encoding = 'utf-8') as file: #读取词云文本文件
fr = file.read()
fr=jieba.lcut(fr) #将文本内容进行词语分割并用空格分隔开来
fr=' '.join(fr)
wc = wordcloud.WordCloud(font_path = '../Stu_pack/wordcloud/simhei.ttf') #(2)创建词云对象
wc.generate(fr) #(3)加载词云文本
wc.to_file('../R&Q_pic/test.jpg') #(4)输出词云图片(文件)
Image.open('../R&Q_pic/test.jpg')
Out[15]:


#示例2:生成默认的矩形词云图(原文件为英文或中文)
import wordcloud #(1)导入词云库
from PIL import Image #导入图片库
from imageio import imread #导入读取遮罩图片库
with open('../Stu_pack/wordcloud/万疆.txt',encoding = 'utf-8') as file: #读取词云文本文件
fr = file.read()
fr=jieba.lcut(fr) #将文本内容进行词语分割并用空格分隔开来
fr=' '.join(fr)
#im = Image.open('../Stu_pack/Wordcloud/Love_Star.PNG') #读取遮罩图片并创建对象im,用这种方式打开无效
im = imread('../Stu_pack/wordcloud/Five_Star.PNG') #读取遮罩图片并创建对象im
wc = wordcloud.WordCloud(mask=im,font_path = '../Stu_pack/wordcloud/simhei.ttf',background_color='#ffaa00')
#(2)创建词云对象
wc.generate(fr) #(3)加载词云文本
wc.to_file('../R&Q_pic/test.jpg') #(4)输出词云图片(文件)
Image.open('../R&Q_pic/test.jpg')
C:\Users\Administrator\AppData\Local\Temp\ipykernel_10372\288491622.py:13: DeprecationWarning: Starting with ImageIO v3 the behavior of this function will switch to that of iio.v3.imread. To keep the current behavior (and make this warning dissapear) use `import imageio.v2 as imageio` or call `imageio.v2.imread` directly.
im = imread('../Stu_pack/wordcloud/Five_Star.PNG') #读取遮罩图片并创建对象im
Out[24]:
















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









