






实验文本:
import warnings
warnings.filterwarnings("ignore")
import keras
keras.__version__from keras import backend as K
K.clear_session()生成图像
变分自编码器
自编码器由 Kingma 和 Welling 于 2013 年 12 月 a 与 Rezende、Mohamed 和 Wierstra 于 2014 年 1 月 同时发现,它是一种生成式模型,特别适用于利用概念向量进行图像编辑的任务。它是 一种现代化的自编码器,将深度学习的想法与贝叶斯推断结合在一起。自编码器是一种网络类型, 其目的是将输入编码到低维潜在空间,然后再解码回来。
经典的图像自编码器接收一张图像,通过一个编码器模块将其映射到潜在向量空间,然后再通过一个解码器模块将其解码为与原始图像具有相同尺寸的输出(见图)。然后,使用与输入图像相同的图像作为目标数据来训练这个自编码器,也就是说,自编码器学习对原始输入进行重新构建。通过对代码(编码器的输出)施加各种限制,我们可以让自编码器学到比较有 趣的数据潜在表示。最常见的情况是将代码限制为低维的并且是稀疏的(即大部分元素为 0),在这种情况下,编码器的作用是将输入数据压缩为更少二进制位的信息。

在实践中,这种经典的自编码器不会得到特别有用或具有良好结构的潜在空间。它们也没有对数据做多少压缩。因此,它们已经基本上过时了。但是,VAE 向自编码器添加了一点统计魔法,迫使其学习连续的、高度结构化的潜在空间。这使得 VAE 已成为图像生成的强大工具。
VAE 不是将输入图像压缩成潜在空间中的固定编码,而是将图像转换为统计分布的参数,即平均值和方差。本质上来说,这意味着我们假设输入图像是由统计过程生成的,在编码和解码过程中应该考虑这一过程的随机性。然后,VAE 使用平均值和方差这两个参数来从分布中随机采样一个元素,并将这个元素解码到原始输入(见下图)。这个过程的随机性提高了其稳健性,并迫使潜在空间的任何位置都对应有意义的表示,即潜在空间采样的每个点都能解码为有效的输出。
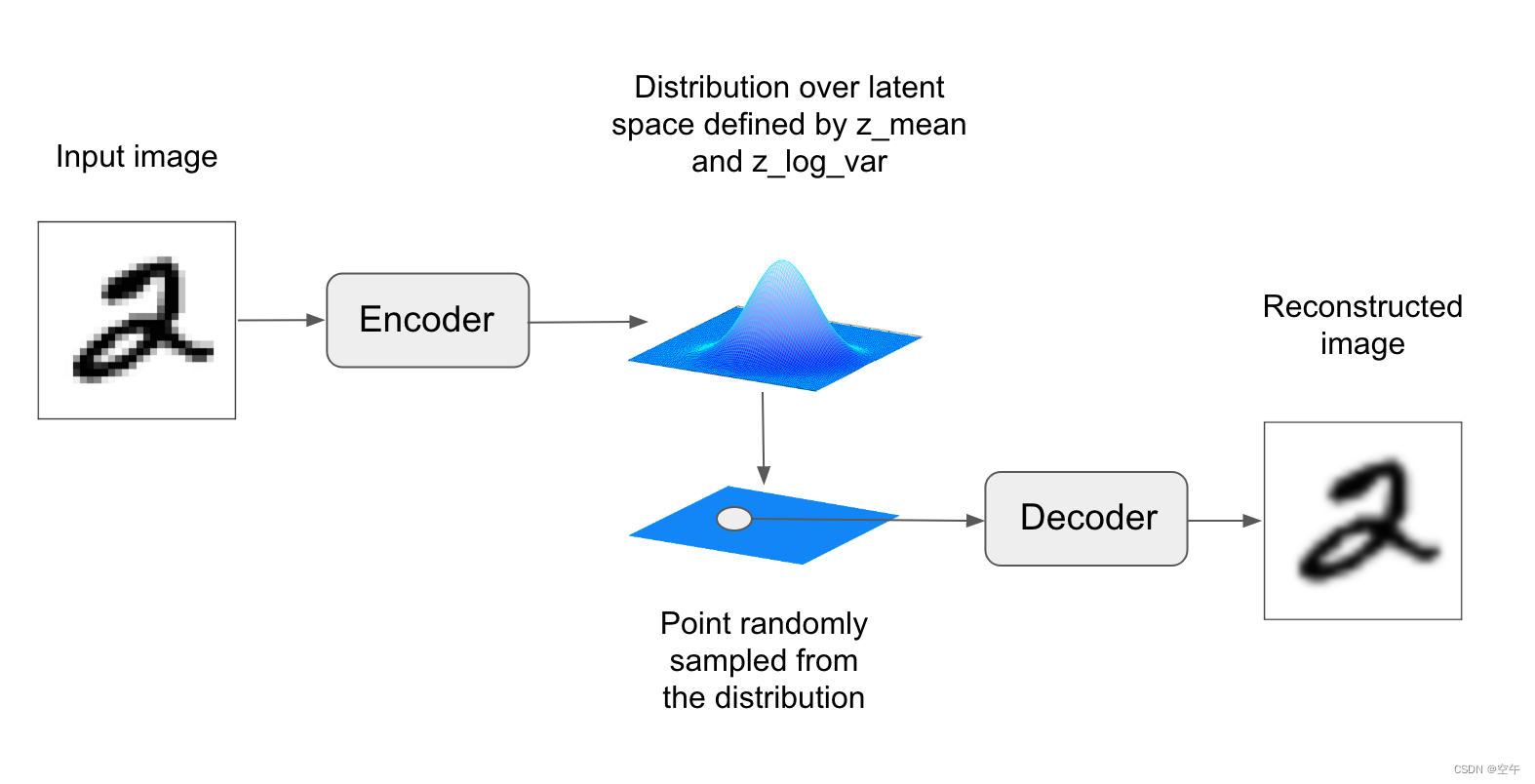
从技术角度来说,VAE 的工作原理如下。
-
一个编码器模块将输入样本 input_img 转换为表示潜在空间中的两个参数 z_mean 和z_log_variance。
-
我们假定潜在正态分布能够生成输入图像,并从这个分布中随机采样一个点 z:
其中
是取值很小的随机张量。
-
一个解码器模块将潜在空间的这个点映射回原始输入图像。
因为 epsilon 是随机的,所以这个过程可以确保,与 input_img 编码的潜在位 置(即 z-mean)靠近的每个点都能被解码为与 input_img 类似的图像,从而迫使潜在空间能够连续地有意义。潜在空间中任意两个相邻的点都会被解码为高度相似的图像。连续性以及潜在空间的低维度,将迫使潜在空间中的每个方向都表示数据中一个有意义的变化轴,这使得潜在空间具有非常良好的结构,因此非常适合通过概念向量来进行操作。
VAE 的参数通过两个损失函数来进行训练:一个是重构损失(reconstruction loss),它迫使解码后的样本匹配初始输入;另一个是正则化损失(regularization loss),它有助于学习具有良好结构的潜在空间,并可以降低在训练数据上的过拟合。我们来快速浏览一下 Keras 实现的 VAE。其大致代码如下所示。
# Encode the input into a mean and variance parameter
# 将输入编码为平均值和方差两个参数
z_mean, z_log_variance = encoder(input_img)
# Draw a latent point using a small random epsilon
# 使用小随机数 epsilon 来抽取一个潜在点
z = z_mean + exp(z_log_variance) * epsilon
# Then decode z back to an image(将 z 解码为一张图像)
reconstructed_img = decoder(z)
# Instantiate a model(将自编码器模型实例化,它将一张输入图像映射为它的重构)
model = Model(input_img, reconstructed_img)
# Then train the model using 2 losses:
# a reconstruction loss and a regularization loss
# 训练模型使用了两种损失:重建损失和正则化损失
它是一个简单的卷积神经网络,将输入图像 x 映射为两个向量 z_mean 和 z_log_var。
import keras
from keras import layers
from keras import backend as K
from keras.models import Model
import numpy as np
img_shape = (28, 28, 1)
batch_size = 16
latent_dim = 2 # Dimensionality of the latent space: a plane(潜在空间的维度:一个二维平面)
input_img = keras.Input(shape=img_shape)
x = layers.Conv2D(32, 3,
padding='same', activation='relu')(input_img)
x = layers.Conv2D(64, 3,
padding='same', activation='relu',
strides=(2, 2))(x)
x = layers.Conv2D(64, 3,
padding='same', activation='relu')(x)
x = layers.Conv2D(64, 3,
padding='same', activation='relu')(x)
shape_before_flattening = K.int_shape(x)
x = layers.Flatten()(x)
x = layers.Dense(32, activation='relu')(x)
z_mean = layers.Dense(latent_dim)(x)
z_log_var = layers.Dense(latent_dim)(x)接下来的代码将使用 z_mean 和 z_log_var 来生成一个潜在空间点 z,z_mean 和 z_log_var 是统计分布的参数,我们假设这个分布能够生成 input_img。这里,我们将一些随意的代码(这些代码构建于 Keras 后端之上)包装到 Lambda 层中。在 Keras 中,任何对象都应该是一个层,所以如果代码不是内置层的一部分,我们应该将其包装到一个Lambda 层(或自定义层)中。
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim),
mean=0., stddev=1.)
return z_mean + K.exp(z_log_var) * epsilon
z = layers.Lambda(sampling)([z_mean, z_log_var])下列代码给出了解码器的实现。我们将向量 z 的尺寸调整为图像大小,然后使用几个卷积层来得到最终的图像输出,它和原始图像 input_img 具有相同的大小。
# This is the input where we will feed `z`.(需要将 z 输入到这里)
decoder_input = layers.Input(K.int_shape(z)[1:])
# Upsample to the correct number of units(对输入进行上采样)
x = layers.Dense(np.prod(shape_before_flattening[1:]),
activation='relu')(decoder_input)
# Reshape into an image of the same shape as before our last `Flatten` layer
# 将 z 转换为特征图,使其形状与编码 器模型最后一个 Flatten 层之前的特征图的形状相同
x = layers.Reshape(shape_before_flattening[1:])(x)
# We then apply then reverse operation to the initial
# stack of convolution layers: a `Conv2DTranspose` layers
# with corresponding parameters.
# 使用一个 Conv2DTranspose 层和一个Conv2D 层,将 z 解码为与原始输入图像具有相同尺寸的特征图
x = layers.Conv2DTranspose(32, 3,
padding='same', activation='relu',
strides=(2, 2))(x)
x = layers.Conv2D(1, 3,
padding='same', activation='sigmoid')(x)
# We end up with a feature map of the same size as the original input.
# 我们最终获得了与原始输入相同大小的特征映射。
# This is our decoder model.将解码器模型实例化,它将 decoder_input转换为解码后的图像
decoder = Model(decoder_input, x)
# We then apply it to `z` to recover the decoded `z`.
# 将这个实例应用于 z,以得到解码后的 z
z_decoded = decoder(z)我们一般认为采样函数的形式为 loss(input, target),VAE 的双重损失不符合这种形式。因此,损失的设置方法为:编写一个自定义层,并在其内部使用内置的 add_loss 层方法来创建一个你想要的损失。
class CustomVariationalLayer(keras.layers.Layer):
def vae_loss(self, x, z_decoded):
x = K.flatten(x)
z_decoded = K.flatten(z_decoded)
xent_loss = keras.metrics.binary_crossentropy(x, z_decoded)
kl_loss = -5e-4 * K.mean(
1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
return K.mean(xent_loss + kl_loss)
def call(self, inputs):
x = inputs[0]
z_decoded = inputs[1]
loss = self.vae_loss(x, z_decoded)
self.add_loss(loss, inputs=inputs)
# We don't use this output.(我们不使用这个输出, 但层必须要有返回值)
return x
# to obtain the final model output.(对输入和解码后的输出调用自定义层,以得到最终的模型输出)
y = CustomVariationalLayer()([input_img, z_decoded])最后,将模型实例化并开始训练。因为损失包含在自定义层中,所以在编译时无须指定外部损失(即 loss=None),这意味着在训练过程中不需要传入目标数据。(如你所见,我们在调用 fit 时只向模型传入了 x_train。)
from keras.datasets import mnist
vae = Model(input_img, y)
vae.compile(optimizer='rmsprop', loss=None)
vae.summary()
# Train the VAE on MNIST digits
(x_train, _), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_train = x_train.reshape(x_train.shape + (1,))
x_test = x_test.astype('float32') / 255.
x_test = x_test.reshape(x_test.shape + (1,))
vae.fit(x=x_train, y=None,
shuffle=True,
epochs=10,
batch_size=batch_size,
validation_data=(x_test, None))一旦训练好了这样的模型(本例中是在 MNIST 上训练),我们就可以使用 decoder 网络将任意潜在空间向量转换为图像。
import matplotlib.pyplot as plt
from scipy.stats import norm
# Display a 2D manifold of the digits
n = 15 # figure with 15x15 digits(我们将显示 15×15 的数字网格(共 255 个数字))
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
# 使用 SciPy 的 ppf 函数对线性分隔的坐标进行变换,
# 以生成潜在变量 z 的值(因 为潜在空间的先验分布是高斯分布)
grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.array([[xi, yi]])
z_sample = np.tile(z_sample, batch_size).reshape(batch_size, 2)
#将 z 多次重复,以构建一个完整的批量
x_decoded = decoder.predict(z_sample, batch_size=batch_size)
# 将批量解码为数字图像
digit = x_decoded[0].reshape(digit_size, digit_size)
#将批量第一个数字的 形状从 28×28×1 转 变为 28×28
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
plt.imshow(figure, cmap='Greys_r')
plt.show()
采样数字的网格(见上图)展示了不同数字类别的完全连续分布:当你沿着潜在空间的一条路径观察时,你会观察到一个数字逐渐变形为另一个数字。这个空间的特定方向具有一定的意义,比如,有一个方向表示“逐渐变为 4”、有一个方向表示“逐渐变为 1”等。
环境配置:
CPU版本和20系等较旧显卡:
由于该课程叫“原始”人工智能,使用的代码过于古老,我们不能用2024年的python环境去运行。首先需要安装anaconda,安装完成之后添加环境变量,环境变量只用这一个就行了。需要跟你自己的匹配
![]()
然后需要创建一个新的python 3.6的环境,在cmd中输入一下内容:
conda create -n py36 python=3.6py36就是这个新环境的名称,可以根据自己的需要修改
初次创建环境后还需要输入初始化代码,然后重启cmd,之后再次进入环境就不需要了
conda init输入以下命令进入python 3.6环境,注意名字要换成自己的
conda activate py36如果出现前面的括号就说明成功了
然后安装jupyter notebook
conda install jupyter安装matplotlib
conda install matplotlib接下需要安装tensorflow 1.15,下图是不同tensorflow版本对应的python版本要求,这也是开始我为什么选择python 3.6

这里我们先以CPU为例子,输入命令安装tensorflow
conda install tensorflow==1.15.0注意:GPU版本不能和CPU版本共存,要想两个都试试,需要两个不同的环境
conda install tensorflow-gpu==1.15.0实际测试MX250这种轻薄本显卡也能跑。
接下来需要安装对应版本的Keras,如图所示,应该安装2.3.1版本
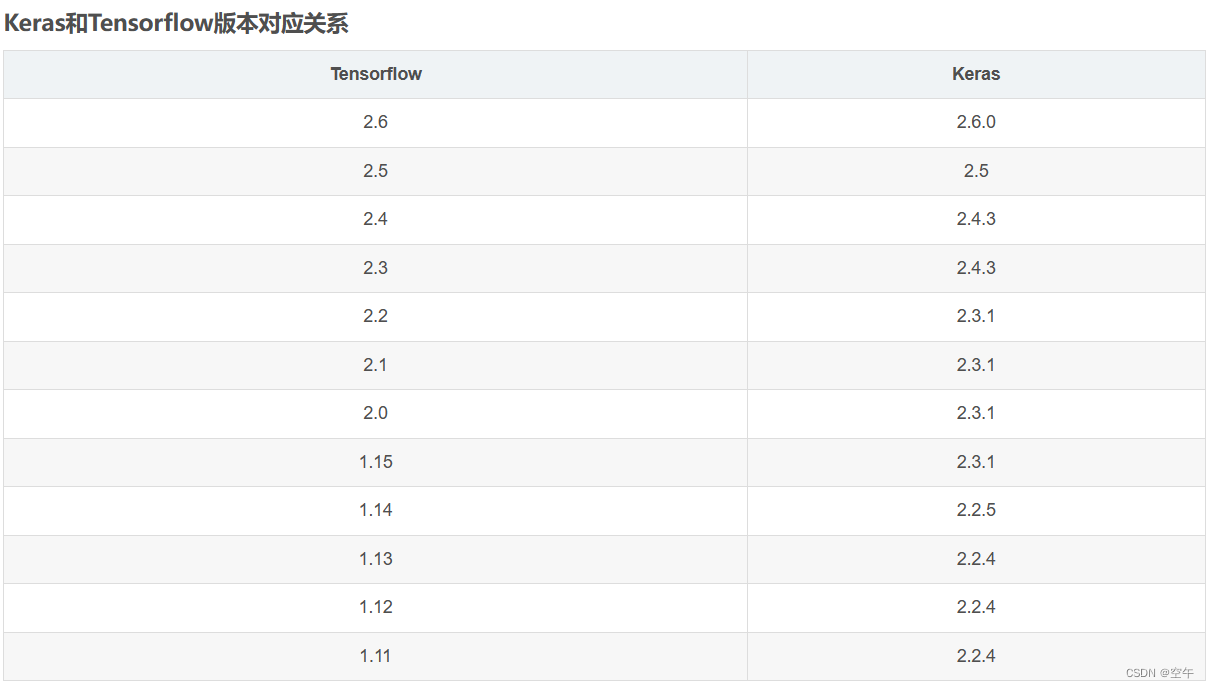
conda install keras==2.3.130系和40系显卡:
用前面的方法,我的RTX4060并不能跑起来,从网上查询原因得知是tensorflow 1.15对30系和40系不兼容。所以就有了下面的方法。
与前面不同,这里的原理是安装tensorflow 2.6版本,然后在代码最前面添加一下内容,在2的版本中使用1的环境
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()网上有很多让下载cuda安装包的,其实不用,只需要在conda中安装tensorflow的gpu版本,它会自己帮你装上的,节省不少精力。
首先需要的是python 3.9的环境
conda create -n py39 python=3.9然后激活一下:
conda activate py39安装tensorflow 2.6的GPU版本
conda install tensorflow-gpu安装jupyter
conda install jupyter安装keras
conda install keras==2.6.0我建议在运行之前首先测试一下你的GPU是否运行,但numpy的版本需要降级
import tensorflow as tf
if tf.test.is_gpu_available():
print("GPU 可用")
else:
print("GPU 不可用")conda install numpy==1.20.0之后安装matplotlib
conda install matplotlibcolab运行:
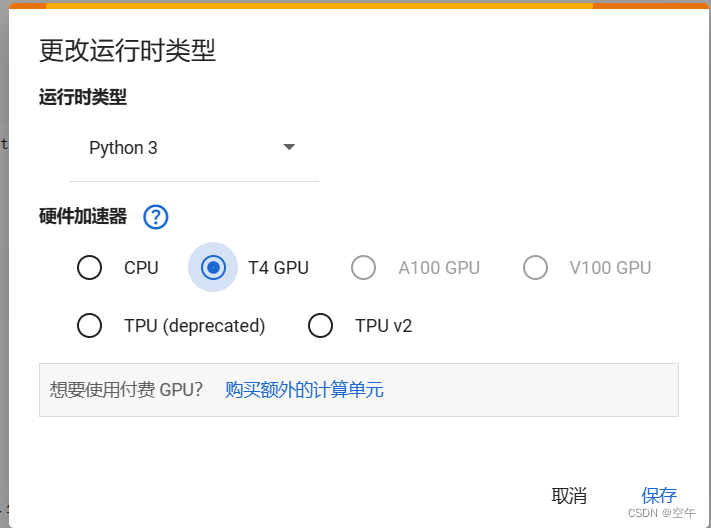
google提供了可以运行的notebook环境,不过它的版本很信,也需要添加前面的更改环境的代码
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()注意选择的时候要选择T4的GPU
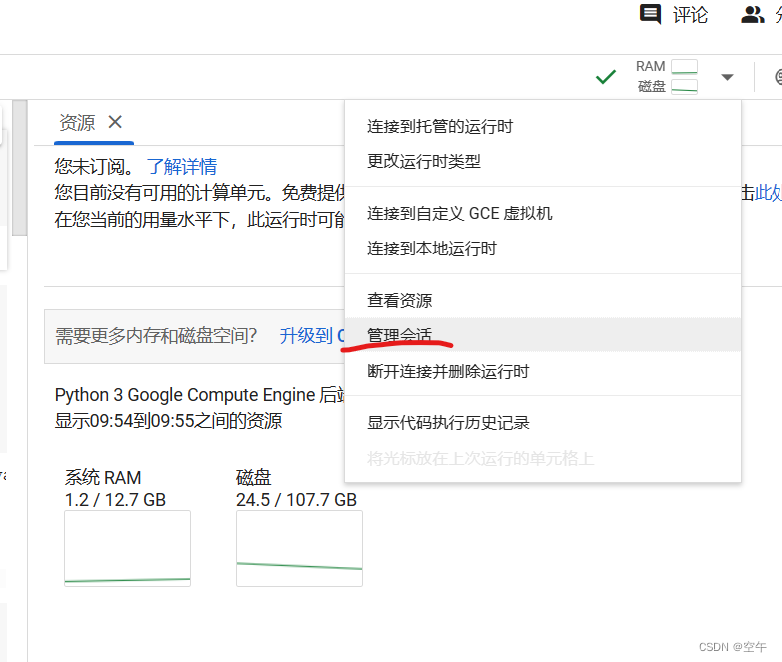
不用的时候记得要断开会话,不然免费的额度就用完了
现在你已经具备运行的环境,相信一定比实验课提供的那个环境强。
作者:henu 21级 计算机与信息工程学院 空午















 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









