







写到一半多发现github上有人有比我详细的代码注释,感觉写的好清楚,可以直接看他的SiamMask_master
我个人 get_cls_loss后面的均为直接引用。
先是全部代码:
# --------------------------------------------------------
# SiamMask
# Licensed under The MIT License
# Written by Qiang Wang (wangqiang2015 at ia.ac.cn)
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from utils.anchors import Anchors
class SiamMask(nn.Module):
def __init__(self, anchors=None, o_sz=63, g_sz=127):
super(SiamMask, self).__init__()
self.anchors = anchors # anchor_cfg
self.anchor_num = len(self.anchors["ratios"]) * len(self.anchors["scales"])
self.anchor = Anchors(anchors)
self.features = None
self.rpn_model = None
self.mask_model = None
self.o_sz = o_sz
self.g_sz = g_sz
self.upSample = nn.UpsamplingBilinear2d(size=[g_sz, g_sz])
self.all_anchors = None
def set_all_anchors(self, image_center, size):
# cx,cy,w,h
if not self.anchor.generate_all_anchors(image_center, size):
return
all_anchors = self.anchor.all_anchors[1] # cx, cy, w, h
self.all_anchors = torch.from_numpy(all_anchors).float().cuda()
self.all_anchors = [self.all_anchors[i] for i in range(4)]
def feature_extractor(self, x):
return self.features(x)
def rpn(self, template, search):
pred_cls, pred_loc = self.rpn_model(template, search)
return pred_cls, pred_loc
def mask(self, template, search):
pred_mask = self.mask_model(template, search)
return pred_mask
def _add_rpn_loss(self, label_cls, label_loc, lable_loc_weight, label_mask, label_mask_weight,
rpn_pred_cls, rpn_pred_loc, rpn_pred_mask):
rpn_loss_cls = select_cross_entropy_loss(rpn_pred_cls, label_cls)
rpn_loss_loc = weight_l1_loss(rpn_pred_loc, label_loc, lable_loc_weight)
rpn_loss_mask, iou_m, iou_5, iou_7 = select_mask_logistic_loss(rpn_pred_mask, label_mask, label_mask_weight)
return rpn_loss_cls, rpn_loss_loc, rpn_loss_mask, iou_m, iou_5, iou_7
def run(self, template, search, softmax=False):
"""
run network
"""
template_feature = self.feature_extractor(template)
search_feature = self.feature_extractor(search)
rpn_pred_cls, rpn_pred_loc = self.rpn(template_feature, search_feature)
rpn_pred_mask = self.mask(template_feature, search_feature) # (b, 63*63, w, h)
if softmax:
rpn_pred_cls = self.softmax(rpn_pred_cls)
return rpn_pred_cls, rpn_pred_loc, rpn_pred_mask, template_feature, search_feature
def softmax(self, cls):
b, a2, h, w = cls.size()
cls = cls.view(b, 2, a2//2, h, w)
cls = cls.permute(0, 2, 3, 4, 1).contiguous()
cls = F.log_softmax(cls, dim=4)
return cls
def forward(self, input):
"""
:param input: dict of input with keys of:
'template': [b, 3, h1, w1], input template image.
'search': [b, 3, h2, w2], input search image.
'label_cls':[b, max_num_gts, 5] or None(self.training==False),
each gt contains x1,y1,x2,y2,class.
:return: dict of loss, predict, accuracy
"""
template = input['template']
search = input['search']
if self.training:
label_cls = input['label_cls']
label_loc = input['label_loc']
lable_loc_weight = input['label_loc_weight']
label_mask = input['label_mask']
label_mask_weight = input['label_mask_weight']
rpn_pred_cls, rpn_pred_loc, rpn_pred_mask, template_feature, search_feature = \
self.run(template, search, softmax=self.training)
outputs = dict()
outputs['predict'] = [rpn_pred_loc, rpn_pred_cls, rpn_pred_mask, template_feature, search_feature]
if self.training:
rpn_loss_cls, rpn_loss_loc, rpn_loss_mask, iou_acc_mean, iou_acc_5, iou_acc_7 = \
self._add_rpn_loss(label_cls, label_loc, lable_loc_weight, label_mask, label_mask_weight,
rpn_pred_cls, rpn_pred_loc, rpn_pred_mask)
outputs['losses'] = [rpn_loss_cls, rpn_loss_loc, rpn_loss_mask]
outputs['accuracy'] = [iou_acc_mean, iou_acc_5, iou_acc_7]
return outputs
def template(self, z):
self.zf = self.feature_extractor(z)
cls_kernel, loc_kernel = self.rpn_model.template(self.zf)
return cls_kernel, loc_kernel
def track(self, x, cls_kernel=None, loc_kernel=None, softmax=False):
xf = self.feature_extractor(x)
rpn_pred_cls, rpn_pred_loc = self.rpn_model.track(xf, cls_kernel, loc_kernel)
if softmax:
rpn_pred_cls = self.softmax(rpn_pred_cls)
return rpn_pred_cls, rpn_pred_loc
def get_cls_loss(pred, label, select):
if select.nelement() == 0: return pred.sum()*0.
pred = torch.index_select(pred, 0, select)
label = torch.index_select(label, 0, select)
return F.nll_loss(pred, label)
def select_cross_entropy_loss(pred, label):
pred = pred.view(-1, 2)
label = label.view(-1)
pos = Variable(label.data.eq(1).nonzero().squeeze()).cuda()
neg = Variable(label.data.eq(0).nonzero().squeeze()).cuda()
loss_pos = get_cls_loss(pred, label, pos)
loss_neg = get_cls_loss(pred, label, neg)
return loss_pos * 0.5 + loss_neg * 0.5
def weight_l1_loss(pred_loc, label_loc, loss_weight):
"""
:param pred_loc: [b, 4k, h, w]
:param label_loc: [b, 4k, h, w]
:param loss_weight: [b, k, h, w]
:return: loc loss value
"""
b, _, sh, sw = pred_loc.size()
pred_loc = pred_loc.view(b, 4, -1, sh, sw)
diff = (pred_loc - label_loc).abs()
diff = diff.sum(dim=1).view(b, -1, sh, sw)
loss = diff * loss_weight
return loss.sum().div(b)
def select_mask_logistic_loss(p_m, mask, weight, o_sz=63, g_sz=127):
weight = weight.view(-1)
pos = Variable(weight.data.eq(1).nonzero().squeeze())
if pos.nelement() == 0: return p_m.sum() * 0, p_m.sum() * 0, p_m.sum() * 0, p_m.sum() * 0
p_m = p_m.permute(0, 2, 3, 1).contiguous().view(-1, 1, o_sz, o_sz)
p_m = torch.index_select(p_m, 0, pos)
p_m = nn.UpsamplingBilinear2d(size=[g_sz, g_sz])(p_m)
p_m = p_m.view(-1, g_sz * g_sz)
mask_uf = F.unfold(mask, (g_sz, g_sz), padding=32, stride=8)
mask_uf = torch.transpose(mask_uf, 1, 2).contiguous().view(-1, g_sz * g_sz)
mask_uf = torch.index_select(mask_uf, 0, pos)
loss = F.soft_margin_loss(p_m, mask_uf)
iou_m, iou_5, iou_7 = iou_measure(p_m, mask_uf)
return loss, iou_m, iou_5, iou_7
def iou_measure(pred, label):
pred = pred.ge(0)
mask_sum = pred.eq(1).add(label.eq(1))
intxn = torch.sum(mask_sum == 2, dim=1).float()
union = torch.sum(mask_sum > 0, dim=1).float()
iou = intxn/union
return torch.mean(iou), (torch.sum(iou > 0.5).float()/iou.shape[0]), (torch.sum(iou > 0.7).float()/iou.shape[0])
if __name__ == "__main__":
p_m = torch.randn(4, 63*63, 25, 25)
cls = torch.randn(4, 1, 25, 25) > 0.9
mask = torch.randn(4, 1, 255, 255) * 2 - 1
loss = select_mask_logistic_loss(p_m, mask, cls)
print(loss)
分行阅读:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from utils.anchors import Anchors
导入几个模块
1.torch.nn.functional
代码中用了F.log_softmax F.nll_loss F.unfold F.soft_margin_loss四个
F.log_softmax: 就是一个非线性激活函数
F.nll_loss: 是一个损失函数
torch.nn.functional.nll_loss(input, target, weight=None, size_average=True)
参数:
- input - (N,C) C 是类别的个数 。
- target - (N) 其大小是 0 <= targets[i] <= C-1
- weight (Variable, optional) –一个可手动指定每个类别的权重。如果给定的话,必须是大小为nclasses的Variable
- size_average (bool,optional) –默认情况下,是mini-batchloss的平均值,然而,如果size_average=False,则是mini-batchloss的总和。
Variables:
- weight – 对于constructor而言,每一类的权重作为输入
torch.nn.functional.unfold
def unfold(input, kernel_size, dilation=1, padding=0, stride=1):
"""
input: tensor数据,四维, Batchsize, channel, height, width
kernel_size: 核大小,决定输出tensor的数目。稍微详细讲
dilation: 输出形式是否有间隔,稍后详细讲。
padding:一般是没有用的必要
stride: 核的滑动步长。稍后详细讲
"""
参考:PyTorch中torch.nn.functional.unfold函数使用详解
F.soft_margin_loss: 一个loss函数
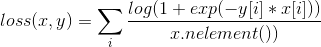 ,
, 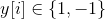
具体可见:pytorch中的loss函数(2):SoftMarginLoss
2.Variable
torch.autograd提供了类和函数用来对任意标量函数进行求导。要想使用自动求导,只需要对已有的代码进行微小的改变。只需要将所有的tensor包含进Variable对象中即可。
参考:PyTorch中文文档中的Autograd
三个属性:
- data (any tensor class) – 被包含的Tensor
- requires_grad (bool) –requires_grad标记. 只能通过keyword传入.
- volatile (bool) – volatile标记.只能通过keyword传入.
下面具体看代码
class SiamMask(nn.Module):
下面一大段是siammask的结构:
def __init__(self, anchors=None, o_sz=63, g_sz=127):
super(SiamMask, self).__init__()
self.anchors = anchors # anchor_cfg
self.anchor_num = len(self.anchors["ratios"]) * len(self.anchors["scales"])
self.anchor = Anchors(anchors)
self.features = None
self.rpn_model = None
self.mask_model = None
self.o_sz = o_sz
self.g_sz = g_sz
self.upSample = nn.UpsamplingBilinear2d(size=[g_sz, g_sz])
self.all_anchors = None
self.anchors = anchors # anchor_cfg是从 SiamMask/experiments/siammask_base/config.json里面来导入anchors的
具体参数设置为:
"anchors": {
"stride": 8,
"ratios": [0.33, 0.5, 1, 2, 3],
"scales": [8],
"round_dight": 0
}
self.anchor_num = len(self.anchors["ratios"]) * len(self.anchors["scales"])anchor的数量为尺度个数乘以比例个数
下面其它也是一些参数之类的:
self.features = None 是特征提取网络模型
self.rpn_model = None 是rpn网络模型
self.mask_model = None 是进行图像分割的网络模型
self.o_sz = o_sz 是输入尺寸
self.g_sz = g_sz 是输出尺寸
有一个函数需要注意:torch.nn.UpsamplingBilinear2d专门用于2D数据的双线性插值算法
pytorch torch.nn 实现上采样——nn.Upsample
def set_all_anchors(self, image_center, size):
# cx,cy,w,h
if not self.anchor.generate_all_anchors(image_center, size):
return
all_anchors = self.anchor.all_anchors[1] # cx, cy, w, h
self.all_anchors = torch.from_numpy(all_anchors).float().cuda()
self.all_anchors = [self.all_anchors[i] for i in range(4)]
这个函数输入两个参数,一个图像中心,一个图像大小。可能是为了得到所有anchors?不太懂
def feature_extractor(self, x):
return self.features(x)
这个函数是用来提取特征的,x输入,self.features(x)输出特征。
def rpn(self, template, search):
pred_cls, pred_loc = self.rpn_model(template, search)
return pred_cls, pred_loc
这个函数是rpn网络模型,template: 模板, search: 搜索图像,返回值是预测的分类结果以及位置结果。
def mask(self, template, search):
pred_mask = self.mask_model(template, search)
return pred_mask
template:模板,search:待搜索的图像,返回结果:掩膜mask结果。
def _add_rpn_loss(self, label_cls, label_loc, lable_loc_weight, label_mask, label_mask_weight,
rpn_pred_cls, rpn_pred_loc, rpn_pred_mask):
rpn_loss_cls = select_cross_entropy_loss(rpn_pred_cls, label_cls)
rpn_loss_loc = weight_l1_loss(rpn_pred_loc, label_loc, lable_loc_weight)
rpn_loss_mask, iou_m, iou_5, iou_7 = select_mask_logistic_loss(rpn_pred_mask, label_mask, label_mask_weight)
return rpn_loss_cls, rpn_loss_loc, rpn_loss_mask, iou_m, iou_5, iou_7
这个是rpn损失函数:分类损失和回归损失
分类损失:rpn_loss_cls = select_cross_entropy_loss(rpn_pred_cls, label_cls)这个看名字明显是交叉熵损失。
回归损失:rpn_loss_loc = weight_l1_loss(rpn_pred_loc, label_loc, lable_loc_weight)看下面的具体实现。
下面这个rpn_loss_mask, iou_m, iou_5, iou_7 = select_mask_logistic_loss(rpn_pred_mask, label_mask, label_mask_weight)返回的是损失结果以及准确率。
def run(self, template, search, softmax=False):
"""
run network
"""
# 提取模板特征
template_feature = self.feature_extractor(template)
# 提取图像特征
search_feature = self.feature_extractor(search)
# 预测结果
rpn_pred_cls, rpn_pred_loc = self.rpn(template_feature, search_feature)
rpn_pred_mask = self.mask(template_feature, search_feature) # (b, 63*63, w, h)
if softmax:
rpn_pred_cls = self.softmax(rpn_pred_cls)
return rpn_pred_cls, rpn_pred_loc, rpn_pred_mask, template_feature, search_feature
对网络进行构建,先提取模板特征,然后提取图像特征,然后预测结果并生成mask掩码( rpn_pred_cls, rpn_pred_loc),最后进行softmax分类
def softmax(self, cls):
b, a2, h, w = cls.size()
cls = cls.view(b, 2, a2//2, h, w)
cls = cls.permute(0, 2, 3, 4, 1).contiguous()
cls = F.log_softmax(cls, dim=4)
return cls
第一行是为了获取cls对应的anchor的大小;然后用view函数进行纬度重构,多出了一个2;接着进行纬度变换;最后对softmax结果求以4为底的对数并return。
def forward(self, input):
#2个参数设置:输入的模板图像、待搜索图像
template = input['template']
search = input['search']
if self.training:
label_cls = input['label_cls']
label_loc = input['label_loc']
lable_loc_weight = input['label_loc_weight']
label_mask = input['label_mask']
label_mask_weight = input['label_mask_weight']
rpn_pred_cls, rpn_pred_loc, rpn_pred_mask, template_feature, search_feature = \
self.run(template, search, softmax=self.training)
# 这个符号\(处于行尾位置)作用是续行符
outputs = dict()
# 输出预测的结果
outputs['predict'] = [rpn_pred_loc, rpn_pred_cls, rpn_pred_mask, template_feature, search_feature]
if self.training:
# 损失函数
rpn_loss_cls, rpn_loss_loc, rpn_loss_mask, iou_acc_mean, iou_acc_5, iou_acc_7 = \
self._add_rpn_loss(label_cls, label_loc, lable_loc_weight, label_mask, label_mask_weight, rpn_pred_cls, rpn_pred_loc, rpn_pred_mask)
# 输出损失函数和精度结果
outputs['losses'] = [rpn_loss_cls, rpn_loss_loc, rpn_loss_mask]
outputs['accuracy'] = [iou_acc_mean, iou_acc_5, iou_acc_7]
return outputs
def template(self, z):
self.zf = self.feature_extractor(z)
cls_kernel, loc_kernel = self.rpn_model.template(self.zf)
return cls_kernel, loc_kernel
这个函数是用来处理模块图像的,输入z是跟踪目标的模块,输出的是模板z的分类以及回归的结果。
def track(self, x, cls_kernel=None, loc_kernel=None, softmax=False):
#提取输入的x的特征
xf = self.feature_extractor(x)
#给出跟踪的结果 rpn_pred_cls, rpn_pred_loc
rpn_pred_cls, rpn_pred_loc = self.rpn_model.track(xf, cls_kernel, loc_kernel)
if softmax:
rpn_pred_cls = self.softmax(rpn_pred_cls)
return rpn_pred_cls, rpn_pred_loc
这个是进行目标跟踪的,返回目标跟踪的位置和分类结果 rpn_pred_cls, rpn_pred_loc
def get_cls_loss(pred, label, select):
"""
计算分类的损失
:param pred: 预测结果
:param label: 真实结果
:param select: 预测位置
:return:
"""
# 预测位置为0个,返回0
if select.nelement() == 0: return pred.sum()*0.
# 获取预测结果和真实结果
pred = torch.index_select(pred, 0, select)
label = torch.index_select(label, 0, select)
# 计算最大似然函数
return F.nll_loss(pred, label)
def select_cross_entropy_loss(pred, label):
"""
交叉熵损失
:param pred: 预测值
:param label: 标签值(真实值)
:return: 返回正负类的损失值
"""
# 将预测数据展成...*2的形式
pred = pred.view(-1, 2)
# 将标签值展成一维形式
label = label.view(-1)
# 指明标签值
# GPU
# pos = Variable(label.data.eq(1).nonzero().squeeze()).cuda()
# neg = Variable(label.data.eq(0).nonzero().squeeze()).cuda()
pos = Variable(label.data.eq(1).nonzero().squeeze())
neg = Variable(label.data.eq(0).nonzero().squeeze())
# 计算正负样本的分类损失
loss_pos = get_cls_loss(pred, label, pos)
loss_neg = get_cls_loss(pred, label, neg)
return loss_pos * 0.5 + loss_neg * 0.5
上面两个函数要一块看,就是为了实现交叉熵损失的计算。
def weight_l1_loss(pred_loc, label_loc, loss_weight):
"""
smooth L1 损失
:param pred_loc: [b, 4k, h, w]
:param label_loc: [b, 4k, h, w]
:param loss_weight: [b, k, h, w]
:return: loc loss value
"""
# 预测位置的中心坐标和大小
b, _, sh, sw = pred_loc.size()
# 变换维度:
pred_loc = pred_loc.view(b, 4, -1, sh, sw)
# 计算预测与真实值之间的差值
diff = (pred_loc - label_loc).abs()
# 计算梯度
diff = diff.sum(dim=1).view(b, -1, sh, sw)
# 损失
loss = diff * loss_weight
return loss.sum().div(b)
def select_mask_logistic_loss(p_m, mask, weight, o_sz=63, g_sz=127):
"""
计算图像分割分支的损失函数及精度信息
:param p_m:预测的分割结果
:param mask: 掩膜真实结果
:param weight:
:param o_sz:模板的大小
:param g_sz:图像的大小
:return:
"""
weight = weight.view(-1)
pos = Variable(weight.data.eq(1).nonzero().squeeze())
if pos.nelement() == 0: return p_m.sum() * 0, p_m.sum() * 0, p_m.sum() * 0, p_m.sum() * 0
# 维度转换
p_m = p_m.permute(0, 2, 3, 1).contiguous().view(-1, 1, o_sz, o_sz)
p_m = torch.index_select(p_m, 0, pos)
# 2d升采样
p_m = nn.UpsamplingBilinear2d(size=[g_sz, g_sz])(p_m)
p_m = p_m.view(-1, g_sz * g_sz)
# 对掩膜的真实结果进行处理
mask_uf = F.unfold(mask, (g_sz, g_sz), padding=32, stride=8)
mask_uf = torch.transpose(mask_uf, 1, 2).contiguous().view(-1, g_sz * g_sz)
mask_uf = torch.index_select(mask_uf, 0, pos)
# 计算损失函数
loss = F.soft_margin_loss(p_m, mask_uf)
# 计算精度
iou_m, iou_5, iou_7 = iou_measure(p_m, mask_uf)
# 返回结果
return loss, iou_m, iou_5, iou_7
def iou_measure(pred, label):
"""
iou计算
:param pred: 预测值
:param label: 真实值
:return: iou平均值,iou>0.5的比例,iou>0.7的比例
"""
# pred中大于0的置为1
pred = pred.ge(0)
# 将pred中等于1的与label中为1的相加
mask_sum = pred.eq(1).add(label.eq(1))
# mask_sum中为2的表示交
intxn = torch.sum(mask_sum == 2, dim=1).float()
# mask_sum中大于0的表示并
union = torch.sum(mask_sum > 0, dim=1).float()
# 交并比
iou = intxn/union
return torch.mean(iou), (torch.sum(iou > 0.5).float()/iou.shape[0]), (torch.sum(iou > 0.7).float()/iou.shape[0])















 2538
2538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









