







白话解释正则化原理
为什么要正则化
我们在使用某个训练集训练机器学习模型的过程中,通常会计算在模型训练集上的损失函数来度量训练误差,损失越小,说明模型训练的越好。
但是在实际情况中,我们不仅仅是要求模型在训练集上表现好,我们更希望的是模型在未得到训练的数据集上也有良好的表现,这种在未知的数据集上表现良好的能力称为泛化。
我们当然希望泛化误差越小越好。但是在降低训练误差和测试误差的过程中,我们通常面临着机器学习的两个挑战:过拟合和欠拟合。
所谓欠拟合,是指模型不能够在训练集上获得足够低的误差;过拟合相反,是指在 训练集上表现优异,但是在测试集上表现较差。
于是我们需要解决模型的过拟合问题,提高模型的泛化能力。
正则化是解决过拟合问题的有效手段。
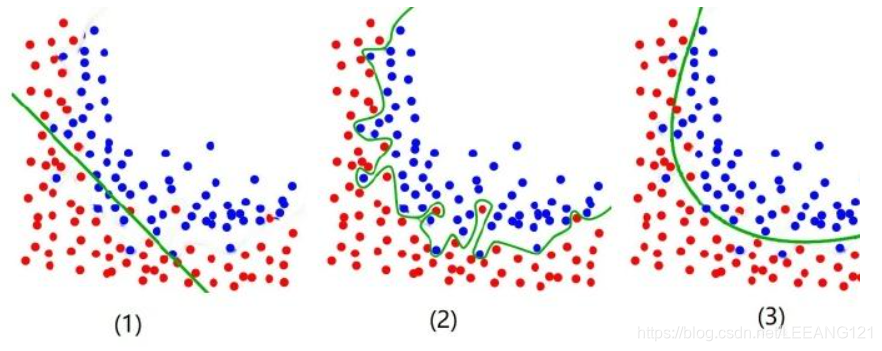
如图所示:
图一是欠拟合的表现结果:考虑的特征点较少,无法有效区分蓝色和红色
图二是过拟合的表现结果:将不必要的特征一起考虑,模型几乎没有泛化能力
图三是模型最佳的表现结果:完美。。。
如何正则化
我们先从网上搬来正则化的概念
正则化(Regularization) 是机器学习中对原始损失函数引入额外信息(注意这个额外信息,这是一个比较难理解的地方,下面会有解释),以便防止过拟合和提高模型泛化性能的一类方法的统称。也就是目标函数变成了原始损失函数+额外项,常用的额外项一般有两种,英文称作ℓ1−normℓ1−norm和ℓ2−normℓ2−norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数(实际是L2范数的平方)。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓惩罚是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
L1和L2正则化的区别如下:
L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵,可以用于特征选择。
稀疏性,说白了就是模型的很多参数是0。通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,很多参数是0,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,即使去掉对模型也没有什么影响,此时我们就可以只关注系数是非零值的特征。这相当于对模型进行了一次特征选择,只留下一些比较重要的特征,提高模型的泛化能力,降低过拟合的可能。
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
我们首先来看一下损失函数的形态
E
(
x
)
=
m
i
n
w
[
∑
i
=
1
n
(
w
T
x
i
−
y
i
)
2
]
E(x)=\underset{w}{min}[\sum_{i=1}^{n}(w^{T}x_{i}-y_{i})^{2}]
E(x)=wmin[∑i=1n(wTxi−yi)2]
其中
E
(
x
)
E(x)
E(x)称为损失函数;
w
w
w是权重,也就是机器学习需要训练的参数
w
T
x
w^{T}x
wTx是计算结果
y
i
y_{i}
yi是真实结果
我们认为这个值越小,我们的计算结果和实际结果越接近。理论上,当这个值为0时,预测结果与实际结果完全吻合。这个时候显然过拟合的情况已经发生,模型没有泛化能力。也就是说模型失去了预测新输入数据的能力。
那么我们如何解决这个问题?就像上面说的一样,我们应该给这个模型添加一个约束,限制最终参数的大小及范围。
我们把公式稍微改变一下:
E
(
x
)
=
m
i
n
w
[
∑
i
=
1
n
(
w
T
x
i
−
y
i
)
2
]
+
λ
∥
w
∥
2
2
E(x)=\underset{w}{min}[\sum_{i=1}^{n}(w^{T}x_{i}-y_{i})^{2}]+\lambda\left \| w \right \|_{2}^{2}
E(x)=wmin[∑i=1n(wTxi−yi)2]+λ∥w∥22
这里我们直接在原有的损失函数里面添加L2范数(L2范数可以有效的防止过拟合)
那么问题来了,为什么L2范数可以有效防止过拟合?
我们为了提高模型的泛化能力,拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是抗扰动能力强。
注意:这里关于让权值尽可能小这一点,之前楼主一直不能理解原因,甚至以为是让权值数量尽可能减少。这里说明一下,L1范数可以减少权值数量,L2范数就是让系数变小而已。
没听懂不要紧,我们有图有真相

注意看上面这幅图,我们从左往右说:
1,最左边这幅图像,明显欠拟合。我们可以看这条蓝色的线(计算机计算出来的曲线),这几乎是一条直线,如果对这条线求导,导数几乎是一个常量,也就是说这条线在感受野内,任你输入如何变化,它就是没反应。。。
2,中间这幅图像,拟合度刚好,我们可以发现中间这条蓝色线条变化很平缓,我们对这条线进行求导,可以想象在感受野内,导数的的变化很平缓
3,最右边这幅图像,蓝色的线条和原图匹配程度最高,但是很显然,线条抖动的非常剧烈,这种情况下,我们的输入数值发生微小的变化,曲线都会发生剧烈的抖动。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
最右边的这种情况也很好的提示了我们防止过拟合的主要方法,就是抑制权重参数过大。加入惩罚项后, 只要控制λ的大小,当λ很大时, w 1 w_{1} w1到 w n w_{n} wn就会很小,即达到了约束数量庞大的特征的目的。
数学公式的解释
(1) 以线性回归中的梯度下降法为例。假设要求的参数为θθ,hθ(x)hθ(x)是我们的假设函数,那么线性回归的代价函数如下:
J θ = 1 2 n ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) 2 J_{\theta }=\frac{1}{2n}\sum_{i=1}^{n}(h\theta (x^{(i)})-y^{(i)})^{2} Jθ=2n1∑i=1n(hθ(x(i))−y(i))2
(2)在梯度下降中θθ的迭代公式为:
θ j = θ j − α 1 n ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta _{j}=\theta _{j}-\alpha \frac{1}{n}\sum_{i=1}^{n}(h\theta (x^{(i)})-y^{(i)})x_{j}^{(i)} θj=θj−αn1∑i=1n(hθ(x(i))−y(i))xj(i)
(3) 其中 α α α是learning rate。 上式是没有添加L2正则化项的迭代公式,如果在原始代价函数之后添加L2正则化,则迭代公式为:
θ j = θ j ( 1 − α λ n ) − α 1 n ∑ i = 1 n ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \theta _{j}=\theta _{j}(1-\alpha \frac{\lambda }{n})-\alpha \frac{1}{n}\sum_{i=1}^{n}(h\theta (x^{(i)})-y^{(i)})x_{j}^{(i)} θj=θj(1−αnλ)−αn1∑i=1n(hθ(x(i))−y(i))xj(i)
其中
λ
λ
λ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代,
θ
j
\theta _{j}
θj都要先乘以一个小于1的因子,从而使得
θ
j
\theta _{j}
θj不断减小,因此总得来看,
θ
j
\theta _{j}
θj是不断减小的。
最开始也提到L1正则化一定程度上也可以防止过拟合。之前做了解释,当L1的正则化系数很小时,得到的最优解会很小,可以达到和L2正则化类似的效果。
L1与L2正则化的区别
前面说过,L1正则化可以使得参数变得稀疏,L2正则化可以防止过拟合。同时,一定程度上,L1也可以防止过拟合。
那么这是为什么呢?
这里我们可以图形化形象的说明这一点。为了便于图形化显示,同时为了方便理解,我们假定输入参数是仅包含2个特征,即权重只有2个
w
1
w_{1}
w1和
w
2
w_{2}
w2,我们设
w
1
w_{1}
w1为横坐标,
w
2
w_{2}
w2为纵坐标。分别表示出损失函数和范数的等值线图。
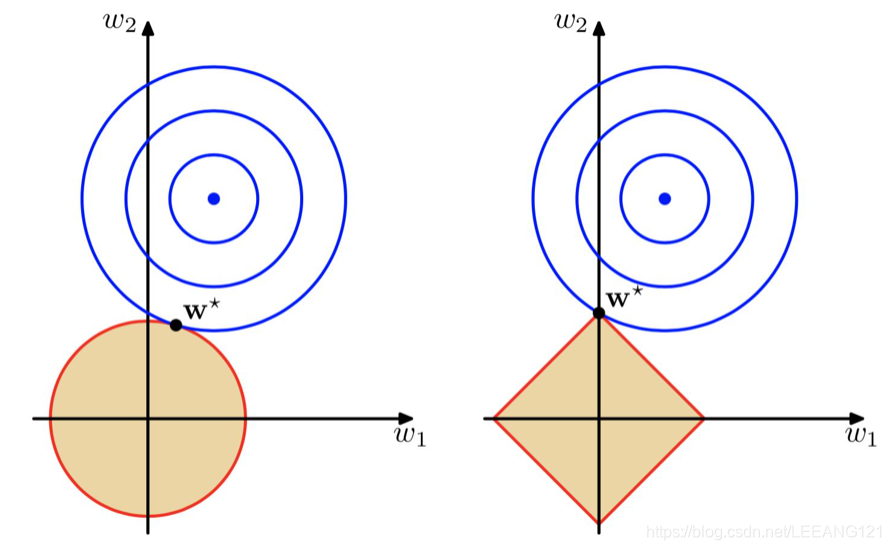
如上图所示,蓝色的圆圈代表损失函数的等值线图,红色代表范数的等值线图。其中红色圆圈代表L2范数,红色菱形代表L1范数。
等值线图就是输出值相等的情况下,
w
1
w_{1}
w1和
w
2
w_{2}
w2的取值在平面内的投影组成的图像。
从上图很容易发现,对于L1范数,损失函数和范数首次相交的点(这些也是最优解所在的点)很容易落在坐标轴上,此时的权值参数取值为零,这就是L1范数可以稀疏化矩阵的原因。
L2范数与损失模型首次相交的点则很难有机会落在坐标轴上,因此L2范数很难对矩阵系数化。
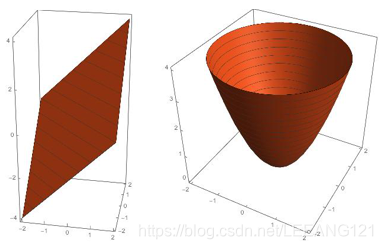
可能很多人想象不出来,为什么L1范数是正方形、L2范数是圆形。首先说一下,我们现在看到的图是投影,那么我们现在看一下他们实际的图的形状。
参考文献:
https://www.cnblogs.com/zingp/p/10375691.html
http://www.pianshen.com/article/466177633/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











