







前言
本文的主要贡献:
(1)为无人机视觉和对话导航创建了一个新的数据集和模拟器。该数据集包括超过3K个带有人机对话的空中导航轨迹;
(2)引入了ANDH和ANDH Full两种任务;
(3)提出注意力辅助Transformer(HAA-Transformer),除了预测航路点导航动作,它还学习预测人类追随者沿导航轨迹的注意力。
一、数据集收集
1.1 收集策略
采用异步数据收集方法,两位工作人员轮流工作,而不是同时工作。数据收集的过程:
(1)先在xView数据集的图片中随机采样一个目标,作为目的地,然后在1.5km之内选择一个初始导航的点;
(2)工作人员编写初始指令;
(3)另一位工作人员根据初始指令开始导航,并在找不到目的地时提问;
(4)之前编写初始指令的工作人员对问题进行说明;
(5)迭代该过程,直到代理成功到达目的地
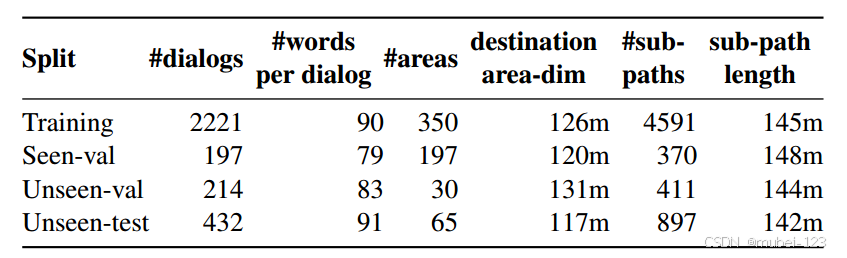
1.2 数据集结构
数据集组成:
(1)包括3064个空中导航轨迹,每个轨迹都有多轮自然语言对话,平均有两轮,轨迹和对话可以进一步分为与对话轮次对应的6269个子轨迹;
(2)轨迹中的对话轮数等于最大时间步长M;
(3)记录的AVDN轨迹路径长度平均为287m;
具体如下图所示:
分析收集到的指令,有两种描述导航方向的方法:(1)以自我为中心的方向描述,如“右转”;(2)以及以异中心的方向定义,如“向南转弯”。
由此,开发一个语言理解模块,以将以自我为中心和以异己为中心的描述与导航操作相结合,是一个方向。
二、模拟器准备
本工作所提出的模拟器具有如下特色:
(1)拟环境是一个连续的空间,因此模拟的无人机可以连续移动到环境中的任何一点;
(2)模拟器设计了界面,可以用键盘控制模拟的无人机;
(3)无人机的视觉观察将通过数字指南针实时显示;
(4)用户可以点击关注的区域,让代理关注;
(5)模拟器能够生成轨迹概览。
三、模型整体框架
3.1 任务描述
本工作引入了AN
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









