







Trie树简介
Trie树,也叫前缀字典树,是一种较常用的数据结构。常用于词频统计,
字符串的快速查找,最长前缀匹配等问题以及相关变种问题。
数据结构表现形式如下图所示:
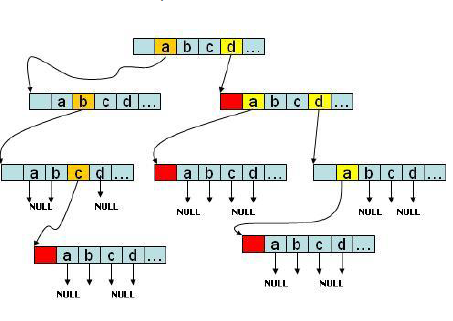
Trie树的根为空节点,不存放数据。每个节点包含了一个指针数组,数组大小通常为26,即保存26个英文字母(如果要区分大小则数组大小为52,如果要包括数字,则要加上0-9,数组大小为62)。
可以想象它是一棵分支很庞大的树,会占用不少内存空间;不过它的树高不会唱过最长的字符串长度,所以查找十分快捷。典型的用空间换取时间。
全英圣经词频统计
全英圣经TXT文件大小有4m,若要对它进行词频统计等相关操作,可以有许多方法解决。
我觉得可以用如下方式:
- pthon字典数据结构解决
- 在linux下利用sed & awk 文本处理程序解决
- C++ STL map解决
- Trie树解决
前三种实现比较简单快捷,不过通过自己封装Trie树可以练习一下数据结构!感受一下数据结构带来的效率提升,何乐而不为。
下面则是我的具体实现,如有纰漏,敬请指正!
1)自定义头文件
WordHash用来记录不重复的单词及其出现次数
TrieTree类封装得不太好,偷懒把很多属性如行数,单词总数等都放在public域
#ifndef _WORD_COUNT_H
#define _WORD_COUNT_H
#include<stdio.h>
#include<string.h>
#include<string>
#include<fstream>
#include<sstream>
#include<vector>
#include<iterator>
#include<algorithm>
#include<iostream>
using std::string;
using std::vector;
typedef struct tag {
char word[50]; //单个单nt show_times; //出现次数
int show_times; //出现次数
}WordHash;
const int child_num = 26;
//字典树节点
typedef struct Trie {
int count;
struct Trie *next_char[child_num];
bool is_word;
//节点构造函数
Trie(): is_word( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2339
2339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









