







【问题描述】
编写程序统计一个英文文本文件中每个单词的出现次数(词频统计),并将统计结果按单词字典序输出到屏幕上。
要求:程序应用二叉排序树(BST)来存储和统计读入的单词。
注:在此单词为仅由字母组成的字符序列。包含大写字母的单词应将大写字母转换为小写字母后统计。在生成二叉排序树不做平衡处理。
【输入形式】
打开当前目录下文件article.txt,从中读取英文单词进行词频统计。
【输出形式】
程序应首先输出二叉排序树中根节点、根节点的右节点及根节点的右节点的右节点上的单词(即root、root->right、root->right->right节点上的单词),单词中间有一个空格分隔,最后一个单词后没有空格,直接为回车(若单词个数不足三个,则按实际数目输出)。
程序将单词统计结果按单词字典序输出到屏幕上,每行输出一个单词及其出现次数,单词和其出现次数间由一个空格分隔,出现次数后无空格,直接为回车。
【样例输入】
当前目录下文件article.txt内容如下:
"Do not take to heart every thing you hear."
"Do not spend all that you have."
"Do not sleep as long as you want;"
【样例输出】
do not take
all 1
as 2
do 3
every 1
have 1
hear 1
heart 1
long 1
not 3
sleep 1
spend 1
take 1
that 1
thing 1
to 1
want 1
you 3
【样例说明】
程序首先在屏幕上输出程序中二叉排序树上根节点、根节点的右子节点及根节点的右子节点的右子节点上的单词,分别为do not take,然后按单词字典序依次输出单词及其出现次数。
【评分标准】
通过全部测试点得满分
题解:
使用BST即可,代码如下
#include<stdio.h>
#include<stdlib.h>
#include<ctype.h>
#include<string.h>
#define ElemType char
typedef struct node{//结点,存储单词,出现频率,左右子树指针;
ElemType data[20];
struct node* left;
struct node* right;
int cnt;
}Node;
typedef struct tree{ //树根,没有数据域
Node *root;
}Tree;
FILE *in;
int read_word(char a[]){//快读
for(int i=0;i<100;i++) a[i]='\0';
int lenth = 0;
char c;
c = fgetc(in);
c = tolower(c);//大小写模糊
while(c<'a'||c>'z'){//跳过非字母字符
if((c = fgetc(in))==EOF) return 0;//注意最后跳出程序
c = tolower(c);
}
while(c>='a'&&c<='z'){
a[lenth++]=c;
c = fgetc(in);
c = tolower(c);
}
return lenth;
}
void insert(Tree *tree,ElemType item[]){//将单词插入树的操作
Node *node=(Node*)malloc(sizeof(Node));
strcpy(node->data,item);
node->left=NULL;
node->right=NULL;
node->cnt=1;
if(tree->root==NULL){
tree->root=node;
}
else{
Node *temp = tree->root;
while(temp!=NULL){
if(strcmp(item,temp->data)==0){//如果树中有这个单词:cnt++
temp->cnt++;
return ;
}
else if(strcmp(item,temp->data)<0){//如果没有这个单词,按照字典序插入到BST中
if(temp->left==NULL){
temp->left=node;
return;
}
else{
temp = temp->left;
}
}
else if(strcmp(item,temp->data)>0){
if(temp->right==NULL){
temp->right=node;
return;
}
else{
temp = temp->right;
}
}
}
}
return ;
}
void pre_order(Node *node){//先序遍历
if(node==NULL) return;
pre_order(node->left);
printf("%s %d\n",node->data,node->cnt);
pre_order(node->right);
return ;
}
int main(){
in = fopen("article.txt","r");
Tree *BSTree=(Tree*)malloc(sizeof(Tree));
BSTree->root=NULL;
char tmp_word[100];
while(read_word(tmp_word)>0){
insert(BSTree,tmp_word);
}
printf("%s",BSTree->root->data);
if(BSTree->root->right!=NULL) printf(" %s",BSTree->root->right->data);
if(BSTree->root->right!=NULL&&BSTree->root->right->right!=NULL) printf(" %s",BSTree->root->right->right->data);
puts("");
pre_order(BSTree->root);
}
除了读取文件时要注意文件末尾退出循环以外都是常规操作。
下面用字典树(Trie)(大作业中使用Trie也比BST快:
字典树也是一种树(废话),但是和BSTE:\programs\data structure\project\0.5s_trie_qsort.cpp不同,字典树是一个度为26的树,字典树的每个结点为一个字母,其孩子节点也是字母。具体例子如下图:
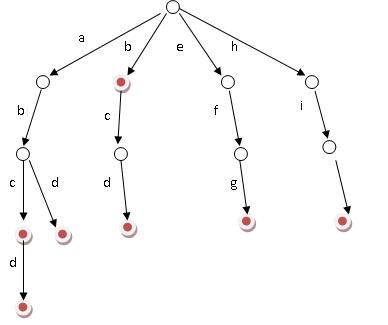
当从根遍历到叶子节点时,其路径就为单词,故一个叶子代表一个单词,再在叶子节点存储词频即可。如:左边的第一二条路径得到单词abcd和abd。但是这两个单词共用了开始重复的字母,用字典树存储效率更高。
对于字典树的实现,我们自然可以使用和上图BST差不多的形式来实现,即构建一棵树。但是我们也可以使用数组来模拟一颗字典树:
这种数组的实现有点类似在第七次作业第三题:求图的最小生成树中kruskal算法中,使用并查集查询两个顶点是否连通的方法。
其原理是:给每一个节点一个编号u,其子节点的编号就是trie[u][c],其中c表示下一个节点储存的字母;当我们插入单词的时候,先把编号给第一个节点trie[0][c],然后编号加一,继续给下一个节点trie[u][c]。
比如在开始的时候(size_trie=0)插入单词abc
设置u=0;
先插入a,得到让trie[0(u)][0(a-a)]=++size_tire=1,然后让u=trie[0][0]=1
之后插入b,trie[1][1]=2;然后u = 2;
之后插入c,trie[2][2]=3;最后u = 3;
而查找也是同理,找到最后u = 3以后,val[u]就是词频。
代码如下:
/*this is a programme demo for trie*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int trie[100][26] = {0};
int size_trie = 0;
int val[26 * 100];
void insert(char *s)
{
int u = 0, c;
for (int i = 0; i < strlen(s); i++)
{
c = s[i] - 'a';
if (!trie[u][c])
{
trie[u][c] = ++size_trie;
}
u = trie[u][c];
}
val[u]++;
}
int get_val(char *s)
{
int u = 0, c;
for (int i = 0; i < strlen(s); i++)
{
c = s[i] - 'a';
if (!trie[u][c])
{
trie[u][c] = ++size_trie;
}
u = trie[u][c];
}
return val[u];
}
int main()
{
char word[100];
int n;
scanf("%d", &n);
getchar();
while (n--)
{
scanf("%s", word);
getchar();
insert(word);
}
while (~scanf("%s", word))
{
printf("%d\n", get_val(word));
}
}















 2153
2153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









