







文章目录
1.STL中的容器是否是线程安全的?
不是.
STL 的设计初衷是将性能挖掘到极致, 而一旦涉及到加锁保证线程安全,,会对性能造成巨大的影响。对于不同的容器,加锁方式的不同,性能可能也不同(例如hash表的锁表和锁桶).
STL 默认不是线程安全。如果需要在多线程环境下使用,往往需要调用者自行维护线程安全。
C++标准模板库(STL)中的容器本身不是线程安全的。这意味着在没有适当的外部同步机制的情况下,从多个线程同时访问同一个STL容器可能会导致数据竞争和不可预测的行为。
如果多个线程仅仅是读取STL容器的数据,而没有任何写入操作,这通常是安全的。但是,如果至少有一个线程在修改容器(如添加、删除元素),而其他线程正在读取或写入同一个容器,则必须使用适当的同步机制(如互斥锁)来保护对容器的访问。
在某些情况下,可以使用专为并发设计的容器,如C++ 11及以上版本中的std::atomic或std::shared_mutex,或者使用其他库提供的线程安全容器。此外,程序员还可以通过在使用容器前获取锁并在操作完成后释放锁,来防止多个线程同时修改容器。
总的来说,当涉及到多线程环境中的STL容器时,程序员需要负责确保线程安全性。
2.智能指针是否是线程安全的?
unique_ptr, 由于只是在当前代码块范围内生效, 不涉及线程安全问题,但是我们使用指针通常是用来指向对象的,调用的对象的方法可能不是线程安全的。
shared_ptr, 多个对象需要共用一个引用计数变量, 所以会存在线程安全问题. 但是标准库实现的时候考虑到了这个问题, 基于原子操作(CAS)的方式保证 shared_ptr 能够高效地进行原子的操作引用计数。
**智能指针的线程安全性取决于其使用方式和上下文。**智能指针本身,如std::shared_ptr和std::unique_ptr,具体来说,对智能指针对象的多个线程同时读写操作可能会导致数据竞争和不一致的行为。
std::shared_ptr的引用计数操作是线程安全的。这意味着多个线程可以同时增加或减少同一个std::shared_ptr实例的引用计数,而不会出现竞态条件。这是因为std::shared_ptr的引用计数操作内部使用了原子操作,确保了线程安全。
线程安全并不意味着可以随意地在多线程环境中使用智能指针。即使引用计数是线程安全的,使用智能指针访问它所指向的对象或资源可能并不是线程安全的。如果多个线程同时访问或修改同一个对象,而没有适当的同步机制(如互斥锁),那么仍然可能出现数据竞争和不一致的情况。
因此,在使用智能指针时,需要谨慎考虑多线程环境下的访问和修改操作。如果需要确保线程安全,应该使用适当的同步机制来保护对共享资源的访问。
总结来说,智能指针的线程安全性是一个复杂的问题,取决于具体的使用方式和上下文。虽然std::shared_ptr的引用计数操作是线程安全的,但使用智能指针访问和修改共享资源仍然需要谨慎处理,以确保线程安全。
3.其他常见的各种锁
3.0理解为什么有这么多种锁
- 锁是为了解决【线程安全】问题的,【线程安全】问题是一个复杂的问题,他又各种各样的场景。
- 设计者为了尽可能地提升OS地效率,尽量把能优化地地方尽量优化。【这种思想是应用与任何事情的,所以经常有人惊叹计算机这个“神物”的优质设计】
- 每种锁都有其适用的场景和优缺点,使用时需要根据具体的业务需求和系统环境进行选择。
3.1悲观锁(Pessimistic Lock)
每次获取数据的时候,都会担心数据被修改,因此每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改。使用完成后,数据会被解锁。由于数据被加锁,期间对该数据进行读写的其他线程都会进行等待。悲观锁比较适合写入操作比较频繁的场景。【之前学的互斥锁/信号量都属于这个范畴,在访问临界资源前由于比较“悲观”,都先去申请锁】
3.2乐观锁(Optimistic Lock)
持有乐观的态度,认为数据冲突发生的概率较低,允许多个任务并行地对数据进行操作,而不加锁。但是在更新数据前,会判断其他数据在更新前有没有对数据进行修改。主要采用两种方式:版本号机制和CAS操作。在乐观锁的机制下,对数据的操作不会立即进行冲突检测和加锁,而是在数据提交时通过一种机制来验证是否存在冲突。乐观锁通常通过版本号(也称为时间戳)实现。每次读取数据时,都会获取当前版本号,并将其与修改前的版本号进行比对。如果两个版本号相同,则认为数据没有被其他任务修改,允许当前任务进行修改操作并更新版本号。如果版本号不同,则表示数据已被其他任务修改,此时需要处理冲突。乐观锁有利于提高系统的吞吐量和并发性能,但在高并发的场景下可能面临挑战。
3.3CAS操作(Compare-and-Swap)
是基于内存模型,通过原子操作保证线程安全的一种机制。CAS包含三个操作数:内存值V、预期值A和新值B。当且仅当预期值A和内存值V相同时,才会将内存值修改为B,若不等则失败,失败则重试,一般是一个自旋的过程,即不断重试。CAS可以用于实现原子操作,如原子增加、原子减少等,避免多个线程同时访问和修改同一数据导致的数据不一致问题。CAS还可以用于实现分布式系统中的数据一致性。
3.4自旋锁:
是一种特殊类型的锁,当线程尝试获取锁时,如果锁已被其他线程持有,则线程不会立即阻塞,而是会“自旋”等待锁被释放。这通常用于短暂等待的情况,以避免线程上下文切换的开销。纯自旋锁通过在一个变量上自旋等待来实现锁。
引进自旋锁
多线程背景下,A线程成功申请锁,进入临界区访问临界资源,A线程访问临界资源的时间即【进临界区到出临界区的时间】是不确定的,之前讲的互斥锁,当B线程想要访问临界资源时,申请锁失败,进行阻塞等待。如果我们通过 【某种手段/或者自定义等待时间的容忍度】 获取到临界资源被访问的时间段的长短,我们就可以做出如下优化:当时间比较久,使用互斥锁,即申请不到就阻塞等待。当时间比较短,申请不到不阻塞等待而是轮询检测锁的状态,一旦可以申请就去申请。这种方案就是自旋锁。
自旋锁的接口

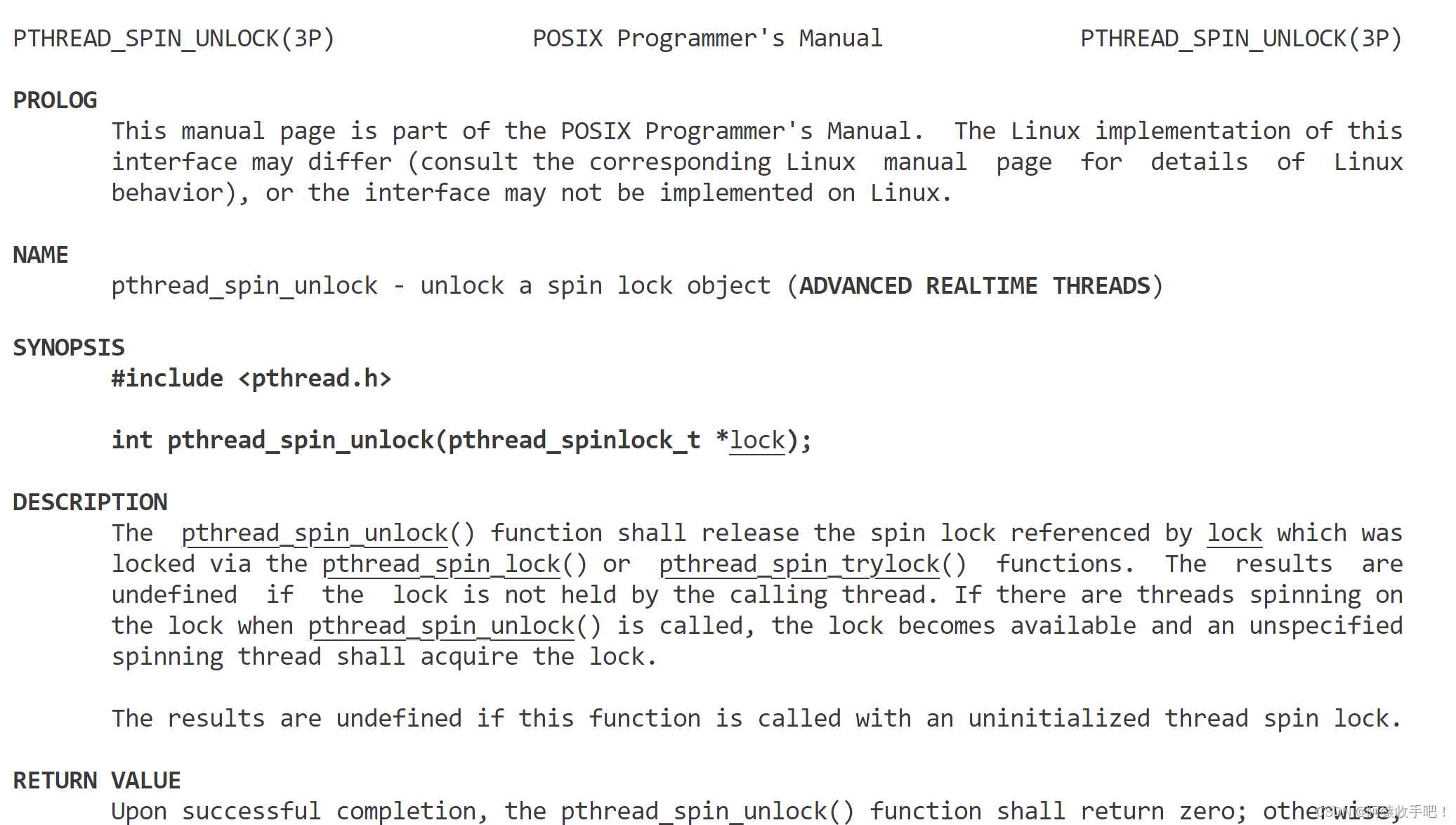
3.5公平锁:
线程在获取锁之前,会查看是否有队列在等待,如果有的话就按照顺序获取锁,先到先得。公平锁单独维护了一个队列,确保所有线程按照请求锁的顺序获取锁。虽然它保证了公平性,但可能会增加线程切换的次数,从而降低性能。
3.6非公平锁:
表示线程获取锁的顺序与线程请求锁的时间早晚无关,先来不一定先获得锁。非公平锁的性能通常比公平锁快5—10倍,因为在没有线程等待时,它允许一个线程直接获取锁,而无需检查队列。
3.7读写锁(ReadWriteLock)
1.读者写者场景
PC模型中,生产者/写者 会生产数据并发送数据到交易场所,消费者/读者 会读取数据并把数据拿走进行处理。而读者写者场景是,写者会生产数据并发送数据到交易场所,读者只读取数据不拿走数据。
2.待分析情况
- 写者在写,读者不能读,因为读到的大可能是不完整的数据,造成读到错误数据。
- 读者在读,写着不能改,如果二者都发生,会造成数据错误。
- 对于数据,可以有多个读者同时读,因为他们只读不拿。但是不能有多个写着同时写,同一时间只能有一个写者写。
- 写者写了数据,没有读者读,这部分数据从某种角度来说无意义(假设写者写的数据的意义就是被读者读)。读者要读数据,没有写者写数据,这也是不合理的。— 同步问题。
- 读者和写者:互斥与同步 读者与读者:共享关系 写者和写者:互斥
- 场景:多个读者要进入交易场所读数据,也有多个写者要进入交易场所写数据,读者优先还是写者优先?a. 读者优先。读者/写者同时到来,让读者先读,读者走完了,再让写者写。b. 写者优先,读者/写者同时到来,让正在读的人退出,让写者先写,写者写完再让读者读。pthread库中的读写锁默认是读者优先。
- 通常情况下,数据被读取的频率非常高,而被修改的频率特别低。即读操作远多于写操作。
3.读写锁的介绍
管理一组锁,一个是只读的锁(共享锁),一个是只写的锁(互斥锁)。它允许多个线程同时读数据,但在写入数据时只允许一个线程进行。这有助于提高并发性能,特别是在读操作远多于写操作的场景中。
设置读写优先
int pthread_rwlockattr_setkind_np(pthread_rwlockattr_t *attr, int pref);
pref 共有 3 种选择
PTHREAD_RWLOCK_PREFER_READER_NP (默认设置) 读者优先,可能会导致写者饥饿情况
PTHREAD_RWLOCK_PREFER_WRITER_NP 写者优先,目前有 BUG,导致表现行为和 PTHREAD_RWLOCK_PREFER_READER_NP 一致
PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP 写者优先,但写者不能递归加锁
初始化
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,const pthread_rwlockattr_t
*restrict attr);
销毁
int pthread_rwlock_destroy(pthread rwlock t *rwlock);
加锁和解锁
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
4.读写锁的场景
在编写多线程的时候,有一种情况是十分常见的。那就是,有些公共数据修改的机会比较少。相比较改写,它们读的机会反而高的多。通常而言,在读的过程中,往往伴随着查找的操作,中间耗时很长。给这种代码段加锁,会极大地降低程序的效率。上面提到,读操作出现的频率更多,如果读者比较多,写者就要一直等吗?那么有没有一种方法,可以专门处理这种多读少写的情况呢? 有,那就是读写锁。

4.1模拟案例1
使用POSIX线程库(pthread)中的读写锁(pthread_rwlock_t)。以下展示了如何使用读写锁来同步对共享资源的访问。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
// 共享资源
int shared_resource = 0;
// 读写锁
pthread_rwlock_t rwlock;
// 读取共享资源的线程函数
void* reader(void* arg) {
while (true) {
// 加读锁
pthread_rwlock_rdlock(&rwlock);
std::cout << "Reader: shared_resource = " << shared_resource << std::endl;
// 解锁
pthread_rwlock_unlock(&rwlock);
usleep(100000); // 模拟读取操作耗时
}
return nullptr;
}
// 写入共享资源的线程函数
void* writer(void* arg) {
int value = 1;
while (true) {
// 加写锁
pthread_rwlock_wrlock(&rwlock);
shared_resource = value;
std::cout << "Writer: shared_resource set to " << shared_resource << std::endl;
value = (value == 1) ? 0 : 1; // 切换写入值
// 解锁
pthread_rwlock_unlock(&rwlock);
usleep(200000); // 模拟写入操作耗时
}
return nullptr;
}
int main() {
// 初始化读写锁
if (pthread_rwlock_init(&rwlock, nullptr) != 0) {
std::cerr << "Failed to initialize read-write lock" << std::endl;
return 1;
}
// 创建读取线程和写入线程
pthread_t reader_thread, writer_thread;
if (pthread_create(&reader_thread, nullptr, reader, nullptr) != 0 ||
pthread_create(&writer_thread, nullptr, writer, nullptr) != 0) {
std::cerr << "Failed to create threads" << std::endl;
return 1;
}
// 等待线程结束(这里只是示例,实际应用中可能需要更复杂的线程管理)
pthread_join(reader_thread, nullptr);
pthread_join(writer_thread, nullptr);
// 销毁读写锁
pthread_rwlock_destroy(&rwlock);
return 0;
}
这个示例中,我们定义了一个共享资源shared_resource和一个读写锁rwlock。我们创建了两个线程函数:reader用于读取共享资源,writer用于写入共享资源。在读取和写入共享资源之前,线程会先获取相应的锁(读锁或写锁),操作完成后释放锁。这样,多个读取线程可以同时访问共享资源,但写入线程在修改共享资源时会阻止其他线程(无论是读取还是写入)访问。
g++ -o readwrite_lock_example readwrite_lock_example.cpp -lpthread
4.2模拟案例2【看一下即可】

#include <vector>
#include <sstream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <unistd.h>
#include <pthread.h>
// 线程属性
struct ThreadAttr
{
pthread_t tid;
std::string threadName;
};
volatile int ticket = 1000;
pthread_rwlock_t rwlock;
volatile int g_readerNum = 0;
/*
lock();
readerNum++;
unlock();
$$读数据$$
lock();
readerNum--;
unlock();
*/
// 读者读票数 不对ticket做操作
void *reader_startRoutine(void *arg)
{
char *readerName = (char *)arg;
while (true)
{
pthread_rwlock_rdlock(&rwlock);
if (ticket <= 0)
{
pthread_rwlock_unlock(&rwlock);
break;
}
g_readerNum++;
sleep(1);
printf("%s: remain tickets:%d readerNum:%d\n", readerName, ticket,g_readerNum);
sleep(1);
g_readerNum--;
pthread_rwlock_unlock(&rwlock);
usleep(1);
}
return nullptr;
}
/*
lock();
if(readerNum > 0)
{
unlock();
return;
}
$$写数据$$
unlock();
*/
// 写者对ticket做操作
void *writer_startRoutine(void *arg)
{
char *writerName = (char *)arg;
while (true)
{
pthread_rwlock_wrlock(&rwlock);
if (g_readerNum > 0)
{
pthread_rwlock_unlock(&rwlock);
return nullptr;
}
if (ticket <= 0)
{
pthread_rwlock_unlock(&rwlock);
break;
}
sleep(1);
printf("%s: reduced tickets:%d\n", writerName, --ticket);
sleep(1);
pthread_rwlock_unlock(&rwlock);
usleep(1);
}
return nullptr;
}
// 拼接读者名称
std::string create_readerName(std::size_t index)
{
// static const std::ios_base::openmode
// std::ios_base::ate = (std::ios_base::openmode)2
// Open and seek to end immediately after opening.
std::ostringstream oss("thread reader ", std::ios_base::ate);
oss << index;
return oss.str();
}
// 拼接写者名称
std::string create_writerName(std::size_t index)
{
std::ostringstream oss("thread writer ", std::ios_base::ate);
oss << index;
return oss.str();
}
// 创建读者线程
void create_readers(std::vector<ThreadAttr> &vec)
{
for (std::size_t i = 0; i < vec.size(); ++i)
{
vec[i].threadName = create_readerName(i);
pthread_create(&vec[i].tid, nullptr, reader_startRoutine, (void *)vec[i].threadName.c_str());
}
}
// 创建写者线程
void create_writers(std::vector<ThreadAttr> &vec)
{
for (std::size_t i = 0; i < vec.size(); ++i)
{
vec[i].threadName = create_writerName(i);
pthread_create(&vec[i].tid, nullptr, writer_startRoutine, (void *)vec[i].threadName.c_str());
}
}
// 逆序回收线程
void join_threads(std::vector<ThreadAttr> const &vec)
{
for (std::vector<ThreadAttr>::const_reverse_iterator it = vec.rbegin();
it != vec.rend(); ++it)
{
pthread_t const &tid = it->tid;
pthread_join(tid, nullptr);
}
}
// 设置读写优先级
void init_rwlock()
{
#ifdef WriteFirst // 写优先
pthread_rwlockattr_t attr;
pthread_rwlockattr_init(&attr);
pthread_rwlockattr_setkind_np(&attr, PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP);
pthread_rwlock_init(&rwlock, &attr);
pthread_rwlockattr_destroy(&attr);
#else // 读优先 会造成写饥饿
pthread_rwlock_init(&rwlock, nullptr);
#endif
}
int main()
{
const std::size_t readerNum = 10;
const std::size_t writerNum = 2;
std::vector<ThreadAttr> readers(readerNum);
std::vector<ThreadAttr> writers(writerNum);
init_rwlock();
create_readers(readers);
sleep(1);
create_writers(writers);
join_threads(writers);
join_threads(readers);
pthread_rwlock_destroy(&rwlock);
}
5.死锁
死锁的处理都有哪些方法?
鸵鸟策略 对可能出现的问题采取无视态度,前提是出现概率很低
预防策略 破坏死锁产生的必要条件
避免策略 银行家算法,分配资源前进行风险判断,避免风险的发生
检测与解除死锁 分配资源时不采取措施,但是必须提供死锁的检测与解除手段
关于死锁的说法正确的有?
死锁产生的必要条件:互斥,不可剥夺,请求与保持,环路等待
竞争可剥夺资源会产生死锁:错误!破坏了不可剥夺条件,因此不会产生死锁
竞争临时资源有可能会产生死锁;这里的临时资源指的是(硬件中断,信号,消息…等),通常顺序不定,因此有可能会产生死锁
在发生死锁时,必然存在一个进程—资源的环形链;环形链也即是环路等待,这是死锁的必要条件
如果进程在一次性申请其所需的全部资源成功后才运行,就不会发生死锁。资源一次性分配,也就不存在请求与保持的情况以及环路等待情况了。
采用“按序分配”策略可以尽可能的破坏产生死锁的环路等待条件;环路等待条件的产生,很大原因是因为所资源分配顺序不一致导致的
产生死锁的现象是每个进程等待某一个不能得到且不可释放的资源;死锁的产生就是因为程序因为获取资源而不可得的情况下程序卡死的情况。
在资源动态分配过程中,防止系统进入不安全状态,可避免发生死锁
银行家算法是最有代表性的死锁死锁避免而并非解除算法。
银行家算法
当系统处于安全状态时, 系统中一定无死锁进程
银行家算法的思想在于将系统运行分为两种状态:安全/非安全,有可能出现风险的都属于非安全。
银行家算法是避免出现死锁的一种算法(并非预防的方法)。
当系统处于不安全状态时, 系统中一定会出现死锁进程–错误!处于不安全状态只是表示有风险,不代表一定发生。
银行家算法的思想是为了避免出现“环路等待”条件
简述线程池的作用与实现原理
线程池通过一个线程安全的阻塞任务队列加上一个或一个以上的线程实现,线程池中的线程可以从阻塞队列中获取任务进行任务处理,当线程都处于繁忙状态时可以将任务加入阻塞队列中,等到其它的线程空闲后进行处理。
避免大量线程频繁创建或销毁所带来的时间成本,也可以避免在峰值压力下,系统资源耗尽的风险;并且可以统一对线程池中的线程进行管理,调度监控。
线程池的关键参数
线程池中线程最大数量:防止资源耗尽,或线程过多性能降低
线程安全的阻塞队列:用于任务排队缓冲
线程池中线程的存活时间:长时间空闲则退出线程节省资源
线程池中阻塞队列的最大节点数量:防止任务过多,资源耗尽
线程池都有什么作用
降低资源消耗:通过重用已经创建的线程来降低线程创建和销毁的消耗。线程池中更多是对已经创建的线程循环利用,因此节省了新的线程的创建与销毁的时间成本
提高线程的可管理性:线程池可以统一管理、分配、调优和监控。线程池是一个模块化的处理思想,具有统一管理,资源分配,调整优化,监控的优点
降低程序的耦合程度: 提高程序的运行效率。线程池模块与任务的产生分离,可以动态的根据性能及任务数量调整线程的数量,提高程序的运行效率
多线程程序的运行效率, 是一个正态分布的结果, 线程数量从1开始增加, 随着线程数量的增加, 程序的运行效率逐渐变高, 直到线程数量达到一个临界值, 当在增加线程数量时, 程序的运行效率会减小(主要是由于频繁线程切换影响线程运行效率)
5.原子性
所谓原语的原子性操作是指一个操作中的所有动作,要么成功完成,要么全不做。也就是说,原语操作是一个不可分割的整体。为了保证原语操作的正确性,必须保证原语具有原子性。在单机环境下,操作的原子性一般是通过关闭中断来实现的。由于中断是计算机与外设通信的重要手段,关闭中断会对系统产生很大的影响,所以在实现时一定要避免原语操作花费时间过长,绝对不允许原语中出现死循环。
CAS(CompareAndSwap),是用来实现lock-free编程的重要手段之一,多数处理器都支持这一原子操作,其用伪代码描述如下,请完成填空,实现全局计数器的原子递增操作。
template bool CAS(T *addr, T expected, T value)
{
if (*addr == expected)
{
*addr = value;
return true;
}
return false;
}
int count = 0;
void count_atomic_inc(int *addr)
{
int oldval = 0;
int newval = 0;
do
{
oldval = *addr;
newval = oldval + 1;
}
until CAS(addr, oldval, newval)
}
CAS(Compare-and-Swap):比较后,数据若无改变,则交换数据的一种无锁操作(乐观锁),这个题注意各个参数是否使用指针。
CAS比较与交换的伪代码可以表示为:
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 ))
下列操作中,需要执行加锁的操作是()[多选]
- 常量的直接赋值是一个原子操作
- 涉及到了数据的运算,则涉及从内存加载数据到寄存器,在寄存器中运算,将寄存器中数据交还内存的过程,需要加锁保护。

并发编程中通常会遇到三个问题 : 原子性问题,可见性问题,有序性问题,java/C/C++中volatile关键字可以保证并发编程中的可见性,有序性。
原子性:一个操作不会被打断,要么一次完成,要么不做。
可见性:一个资源被修改后,是否对其他线程是立即可见的(一个变量的修改存在一个过程,将数据从内存加载的cpu寄存器,进行运算,完毕后交还内存,但是这个过程在代码优化中可能会被编译器优化,将数据放入寄存器,则后续运算只从寄存器取数据,就节省了从内存获取数据的时间)
有序性:简单理解,程序按照写代码的先后顺序执行,就是有序的。(编译器有时候会为了提高程序效率进行代码优化,进行指令重排,来提高效率,而有序性就是禁止指令重排)
而volatile关键字的作用是,防止编译器过度优化,因此具备 可见性与有序性 功能
无锁化编程有哪些常见方法?
针对计数器,可以使用原子操作,原子操作不涉及线程安全问题,不需要锁。
只有一个生产者和一个消费者,那么就可以做到免锁访问环形缓冲区(Ring Buffer),环形队列本身具有同步的功能,在一对一的情况下,这种同步侧面的实现了互斥的效果。
RCU(Read-Copy-Update),新旧副本切换机制,对于旧副本可以采用延迟释放的做法。RCU锁机制-对读写锁的一种优化,读-拷贝-更新,读者可以同时读取数据,写者更新数据前先复制一份数据出来,对副本进行修改,修改完毕后更新数据,而旧版本数据等所有读者不再访问时释放。
CAS(Compare-and-Swap),如无锁栈,无锁队列等待,CAS-比较并交换,是一种乐观锁,认为在使用数据的过程中其它线程不会修改这个数据,故不加锁直接访问。

















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











