






2018.3.1
爬虫的框架总共有3中常用的分别是: Scrapy,PySpider,Selenium
而Selenium 是一款自动测试的框架。
常用的是scrapy,scrapy 是python一种爬虫框架,采用的是多线程爬虫的方式,是普通爬虫的方法的5到6倍的速度
安装 scrapy 例如:

首先第一步:先想好吧爬虫程序放在那里,我们放在桌面以方便管理

第二步:通过cmd命令来创建一个爬虫程序
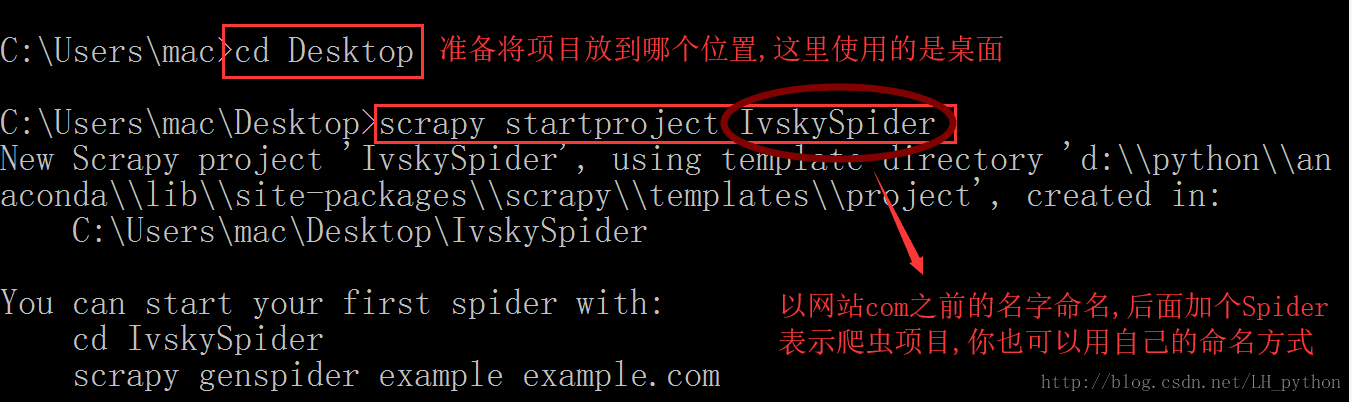
这样 通过cmd命令行所做的事情就完成了桌面上就会出现创建好的项目模板。

然后把这个文件放到pycharm中打开
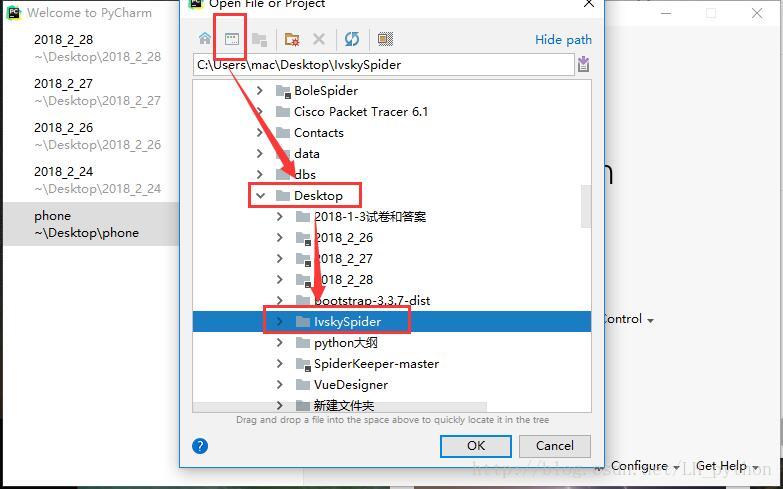
这样就打开了一个最基本的爬虫模板。

然后 通过pycharm的cmd命令来创建爬虫文件
scrapy genspider ivsky ivsky.com

之后打开文件 会在spiders文件目录下出现一个 ivsky.py的文件

下面开始配置settings 文件
1.robots_obey协议,scrapy自动遵循robots协议,所以好多网站都不能爬取,一个改为False
2.修改download_delay配置,scrapy默认中间间隔时间为0,防止被反爬虫发现,所以改为0.5以上。
3.cookie_enable也设置为False,来禁用cookie追踪。
4.自定义UserAgentMiddleWare以此来实现修改爬虫的ueser-agent.这个步骤可以粘贴现成的也可以通过自己研究源码来实现。
5.在setting中配置一下



从源码中粘贴过来修改之后的代码,可以实现z
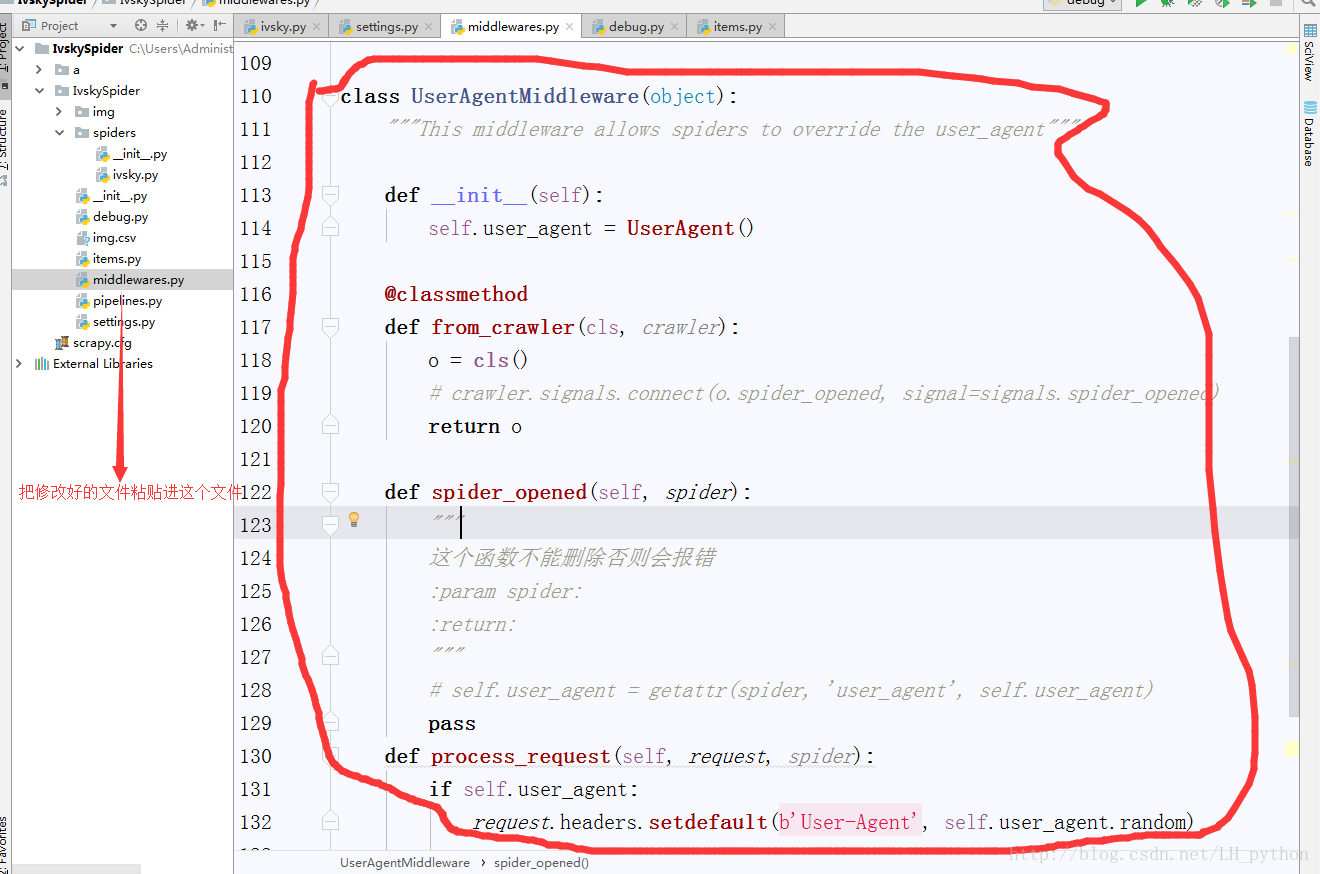

6.开始解析数据
1)首先大致规划一下需要几个函数还进行解析,以便达到清晰明白的看到过程

scrapy 默认只启动parse 函数。所以用yield 关键字来进行函数之间的调用。
yield的用法 类似于return,确有区别与return,return不执行之后的代码,而yield还会执行之后的代码

如果想要把文件下载下来,scrapy 默认支持4种数据格式,分别是:.json,.csv等等
修改 item.py文件 已达到数据的处理。
把要下载的数据放到item进行处理例如

操作是把 debug文件修改一下

这是关于进程和线程的一些知识
















 2632
2632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









