









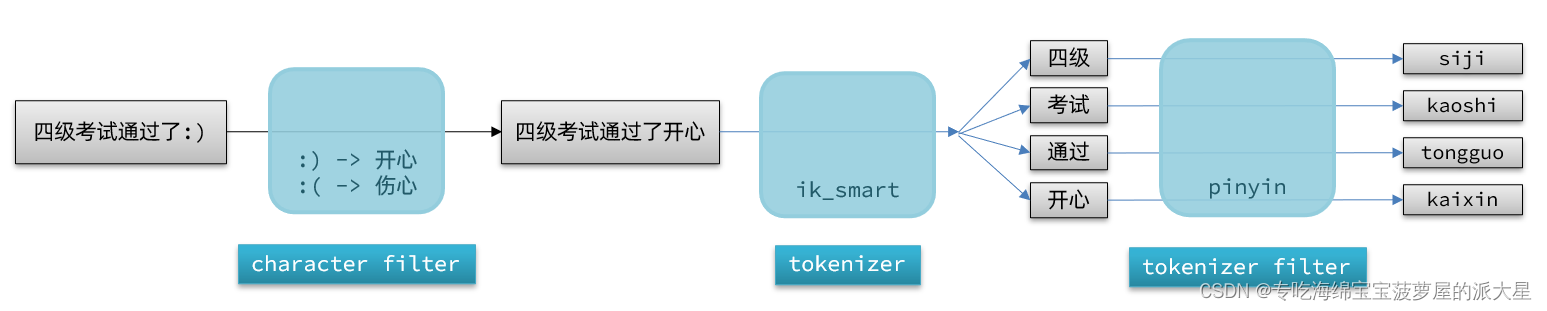
elasticsearch中分词器(analyzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理(预处理)。例如删除字符、替换字符
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart,可以指定分词器进行分词
tokenizer filter:将tokenizer输出的词条做进一步处理(对分词的结果进行处理)。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
自定义分词器的语法:
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这个自定义的过滤器使用的是pinyin分词器
"keep_full_pinyin": false,//不要把单个字ch
"keep_joined_full_pinyin": true,//把词语转成全拼
"keep_original": true,//转完之后的中文保留
"limit_first_letter_length": 16,//转成的拼音首字母不能超过16个
"remove_duplicated_term": true,//转成的拼音不能有重复的,重复的删掉
"none_chinese_pinyin_tokenize": false
}
}
}
}示例:
# 自定义拼音分词器
# 创建两个字段,其中name使用自定义的分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings":{
"properties":{
"id":{
"type":"keyword"
},
"name":{
"type":"text",
"analyzer":"my_analyzer"
}
}
}
}测试:
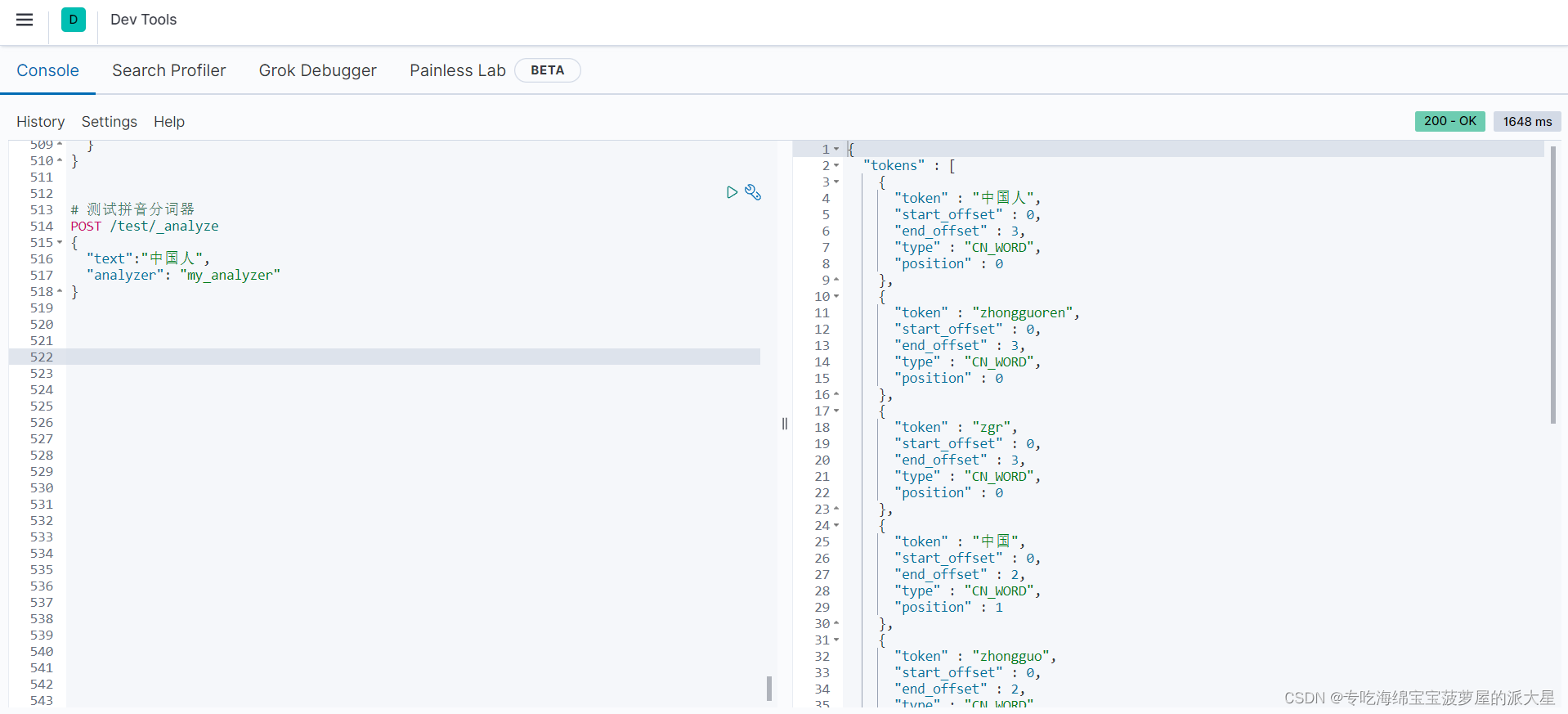
# 测试拼音分词器
POST /test/_analyze
{
"text":"中国人",
"analyzer": "my_analyzer"
}
注:自定义的分词器,只在定义的索引库有用,不能随便使用
问题:
同音字问题!
原因:
1.因为在存数据时(狮子,虱子),会把(狮子①,虱子②,shizi①、②,sz①、②),一起存入倒排索引
2.而在搜索数据时(狮子),因为使用的是自定义的分词器,会先由ik拆词,再由Pinyin转成(狮子①,shizi①、②,sz①、②),在去倒排索引查找时,shizi①、②,会查到同音的词,一起返回
解决方法:
指定字段在创建倒排索引时应该用my_analyzer分词器;字段在搜索时应该使用ik_smart分词器;
代码:
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这个自定义的过滤器使用的是pinyin分词器
"keep_full_pinyin": false,//不要把单个字ch
"keep_joined_full_pinyin": true,//把词语转成全拼
"keep_original": true,//转完之后的中文保留
"limit_first_letter_length": 16,//转成的拼音首字母不能超过16个
"remove_duplicated_term": true,//转成的拼音不能有重复的,重复的删掉
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"//指定搜索时,使用ik分词器
}
}
}
}
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









