









STRING OPERATION SUMMARY
1. 左右移位的区别:

1.1.先左移后右移(左移一位后会直接截断)
在未指定长度的情况下输出值总会占满其定义时的位数
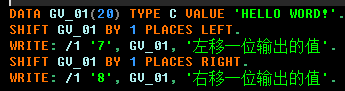

1.2.先右移后左移
1.2.1.设定位数足够大 > 赋值的位数加移动位数时:
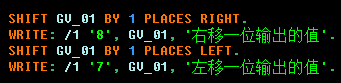

1.2.2.设定位数 < 赋值的位数加移动位数时:
总:CAHR左移必定截断
右移位是否截断,要看定义长度是否够。
特别注意:STRIGN类型可以自动扩展长度—只有左移位才会出现截断
WRITE: /1 ‘-------------------------- STRING 先左移后右移’.
DATA STRING_SHFIT_01 TYPE STRING VALUE HELLO_WORD.
SHIFT STRING_SHFIT_01 BY 3 PLACES LEFT.
WRITE: /1 STRING_SHFIT_01, ‘左移3位输出的值’.
SHIFT STRING_SHFIT_01 BY 3 PLACES RIGHT.
WRITE: /1 STRING_SHFIT_01, ‘右移3位输出的值’.
WRITE: /1 ‘-------------------------- STRING 先右移后左移’.
DATA STRING_SHFIT_02 TYPE STRING VALUE HELLO_WORD.
SHIFT STRING_SHFIT_02 BY 3 PLACES RIGHT.
WRITE: /1 STRING_SHFIT_02, ‘右移3位输出的值’.
SHIFT STRING_SHFIT_02 BY 3 PLACES LEFT.
WRITE: /1 STRING_SHFIT_02, ‘左移3位输出的值’.
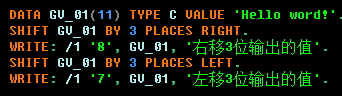




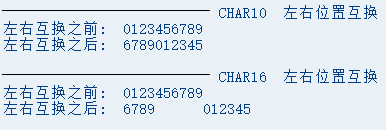
2. 左右互换:


特别注意(对于CHAR类型来讲:左右分割的中间位置是按照定义的长度计算的)
(找到中间的位置,然后以此中心,分割为左右并将左右并进行互换,注意:左/右是一个整体)

2.1. 赋值的位数 = 定义中的位数时:


2.2. 特别注意:(对于CHAR类型来说中间位置是按照定义的长度计算的)
对比:设定位数 > 赋值的位数加移动位数 CHAR16 :
设定位数 = 赋值的位数加移动位数 CHAR10 :

3. 拼接字符串— CONCATENATE 和 &&
注意:拼接的变量只能是字符型:C、N、D、T、STRING ,不可以是I、P、F类型。
CONCATENATE lv_01 lv_02 … lv_n INTO lv_m SEPARATED BY ‘,’.

3.1. 拼接的方式—SEPARATED BY:
- ‘,’ (用逗号拼接)
- ’ ’ (用空格拼接)
- ‘A’(用任意字符拼接)
3.2. 要拼接的变量类型:
- STRING、CHAR 不影响拼接结果
Eg:CONCATENATE A01 A02 TO A03 BY ‘,’.目标变量与拼接变量可以相同. - NUM类型:拼接结果会带有前导零
3.3. 拼接结果的截断:拼接的结果超出目标变量的定义位数直接截断然后存入目标变量中.
1. 不截断:SY-SUBRC = 0.
2. 截 断:SY-SUBRC = 4.
为了避免截断:可以将目标变量定义为STRING类型(在操作过程中可以自动调整长度适应需要).
示例程序:
DATA STR_CON_00 TYPE STRING.
DATA STR_CON_01 TYPE STRING.
DATA CHAR_CON_RESULT TYPE CHAR10.
DATA STRI_CON_RESULT TYPE STRING.

STR_CON_00 = ‘ABCDEF’.
STR_CON_01 = ‘123456’.
SKIP.
WRITE: / ‘********* 拼接结果放在CAHR10类型变量中—长度不足截断 ’.
CONCATENATE STR_CON_00 STR_CON_01 INTO CHAR_CON_RESULT SEPARATED BY ‘,’.
WRITE: / ‘用逗号连接’,AT 12 CHAR_CON_RESULT, AT 36 ‘SY-SUBRC =’, SY-SUBRC.
SKIP.
WRITE: / '******** 拼接结果放在STRING类型变量中 ******************’.
CONCATENATE STR_CON_00 STR_CON_01 INTO STRI_CON_RESULT SEPARATED BY ‘,’.
WRITE: / ‘用逗号连接’, AT 12 STRI_CON_RESULT, AT 36 ‘SY-SUBRC =’, SY-SUBRC.
** 直接拼接:
CONCATENATE STR_CON_00 STR_CON_01 INTO STRI_CON_RESULT.
WRITE: / ‘直接相连’, AT 12 STRI_CON_RESULT, AT 36 ‘SY-SUBRC =’, SY-SUBRC.
总图对比:




3.4. CHAR的循环拼接 : (会根据定义的长度拼接加空格)
???空格是如何来的???为什么空格加文字总比定义长度少一位???
DATA L_MOD_01 TYPE CHAR3.
DATA L_DIV_01 TYPE CHAR3.
DATA BINARY_01 TYPE STRING.
L_DIV_01 = 25.
WHILE L_DIV_01 >< 0.
L_MOD_01 = L_DIV_01 MOD 2.
L_DIV_01 = L_DIV_01 DIV 2.
BINARY_01 = L_MOD_01 && BINARY_01.
ENDWHILE.
DATA L_MOD_01 TYPE CHAR6.
DATA L_DIV_01 TYPE CHAR6.
DATA BINARY_01 TYPE STRING.

L_DIV_01 = P_DEC.
WHILE L_DIV_01 >< 0.
L_MOD_01 = L_DIV_01 MOD 2.
L_DIV_01 = L_DIV_01 DIV 2.
BINARY_01 = L_MOD_01 && BINARY_01.
ENDWHILE.
解决方法:
在拼接之前为要拼接的CHAR变量去除左侧空格。
WHILE L_DIV_01 >< 0.
L_MOD_01 = L_DIV_01 MOD 2.
L_DIV_01 = L_DIV_01 DIV 2.
SHIFT L_MOD_01 LEFT DELETING LEADING SPACE. "连接前—去除CHAR6变量左边所有的空格
CONCATENATE L_MOD_01 BINARY_01 INTO BINARY_01.
ENDWHILE.



3.5. STRING的循环拼接: (不知道空格是咋安排的)
单个变量(string类型,每次长度为1)的循环拼接,拼接结果中每位之后都有一空格。
Eg:
** 十进制 —> 二进制
DATA L_MOD TYPE STRING.
DATA L_DIV TYPE STRING VALUE 25.
DATA BINARY TYPE STRING.
** 将每次的计算的余数L_MOD与结果BINARY作拼接:
WHILE L_DIV >< 0.
L_MOD = L_DIV MOD 2.
L_DIV = L_DIV DIV 2.
CONCATENATE L_MOD BINARY INTO BINARY.
ENDWHILE.
解决方法:
WHILE L_DIV >< 0.
L_MOD = L_DIV MOD 2.
L_DIV = L_DIV DIV 2.
SHIFT L_MOD RIGHT DELETING TRAILING SPACE. "连接前—去除其后面的所有空格
CONCATENATE L_MOD BINARY INTO BINARY.
SHIFT BINARY LEFT DELETING LEADING SPACE. "连接后—去除其前面的所有空格
ENDWHILE.


3.6.NUMC的循环拼接:
DATA L_MOD_02 TYPE NUMC3.
DATA L_DIV_02 TYPE NUMC3.
DATA BINARY_02 TYPE STRING.
L_DIV_02 = P_DEC.
WHILE L_DIV_02 >< 0.
L_MOD_02 = L_DIV_02 MOD 2.
L_DIV_02 = L_DIV_02 DIV 2.
BINARY_02 = L_MOD_02 && BINARY_02. “等效:CONCATENATE L_MOD_02 BINARY_02 INTO BINARY_02.
ENDWHILE.
解决方法:去除前导零??????

总图对比:

4. 添加或去除空格:
去除左边所有空格:SHIFT str_00 LEFT DELETING LEADING SPACE.
去除右边所有空格:SHIFT str_01 RIGHT DELETING TRAILING SPACE.
去除左边第一个空格:SHIFT str_02.
压缩字符串 — 删除字符串中所有多余空格:CONDENSE TEXT.
压缩字符串 — 删除字符串中所有空格:CONDENSE TEXT NO-GAPS.
"注意:NO-GAPS 而不是 NO-GAP.
添加空格 : CONCATENATE SPACE LV_name1 INTO LV_name1.
5.拆分字符串



6.查找字符
search c for str.
在变量C中查找字符串str:
找到:sy-subrc = 0,
sy-fdpos返回变量C中改字符串的位置(从左算起的字符偏移量)。
否则:sy-subrc = 4.
通配符:
- str : 搜索str并忽略尾部的空格
- .str : 搜索str但不忽略尾部的空格
- *str : 搜索以str结尾的单词
- str* : 搜索以str开头的单词
查找时(即使是在‘’中也)不区分大小写
under正下方对齐
7.替换字符串内容:
注意:第一个(在搜索中也是如此)
8.字符串长度:
注意:长度计算的两种方法(注意:存放计算结果的变量类型对最终计算结果的影响)
9.大小写转换:
10.搜索字符串:
11.压缩字符串
12.字符数据的比较:
*-----------------------------------------------------------------------
字符的包含关系:
注意:比较时要区分大小写,并且尾部空格也在比较的范围之内
比较结束后如果逻辑表达式结果为真,系统字段SY-FDPOS将给出S2在S1中的偏移量信息
CO: 如果S1仅包含S2中的字符,则逻辑表达为真
CN: 如果S1包含S2之外的其他字符,则逻辑表达为真
CA: 如果S1包含S2中的任何字符,则逻辑表达为真
NA: 如果S1不包含S2中的任何字符,则逻辑表达为真
*----------------------------------------------------------------------
字符串的包含关系:
注意:比较时不区分大小写,并且忽略尾部空格
比较结束后如果逻辑表达式结果为真,系统字段SY-FDPOS将给出S2在S1中的偏移量信息
** CS: 如果S1包含字符串S2,则逻辑表达为真
** NS: 如果S1不包含字符串S2,则逻辑表达为真
*-----------------------------------------------------------------------
模式比较逻辑表达式:
注意:比较时不区分大小写,并且忽略尾部空格
比较结束后如果逻辑表达式结果为真,系统字段SY-FDPOS将给出S2在S1中的偏移量信息
特别之处:比较时可以使用通配符‘’,‘+’:
‘’:用来替代任何—字符串
‘+’:用于替代任何—单个字符
‘#’:需要对大小写、尾部空格、特殊字符(‘*’,‘+’)进行比较和区分:
需要将换吗字符‘#’放到S2相应字符的前面
** CP: 如果S1包含模式S2,则逻辑表达为真
** NP: 如果S1不包含模式S2,则逻辑表达为真















 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









