




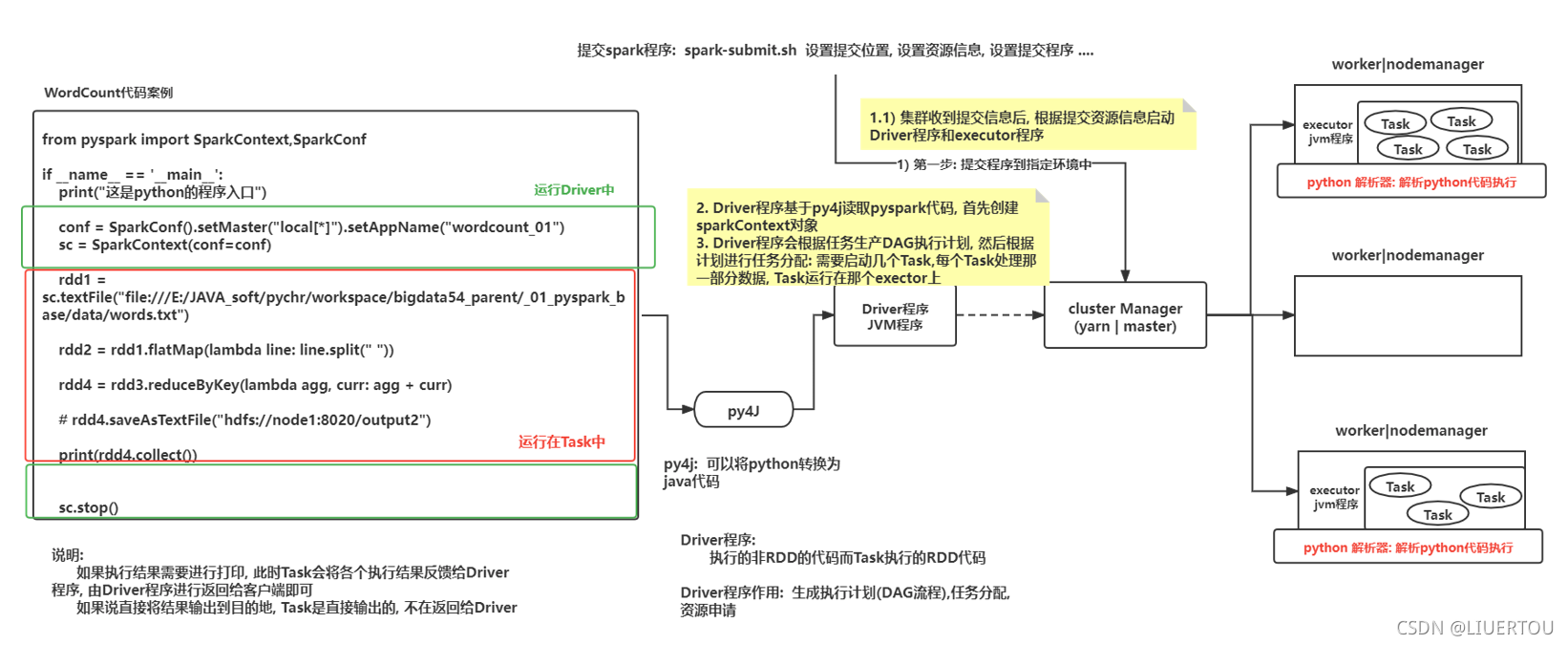
spark程序与pyspark交互流程
交互的流程图
说明
- 以提交到yarn集群为例:部署方式为 client
1- 由执行的spark-submit脚本提交任务,会在当前这个节点根据提交的信息启动一个Driver程序, 由这个Driver程序向yarn的主节点提交任务操作,yarn会认为这个任务启动一个applicationmaster程序,后续与任务相关的操作都找这个applicationmaster程序即可(任意节点的都可以启动和Driver不在一个节点)
2- applicationmaster会根据executor资源信息行yarn的主节点申请源,用于启动executor
3- 当applicationmaster拿到用于启动executor的资源后,通知相应的从节点启动executor执行器即可,当对应节点的执行器启动后,反向响应给Driver程序
4- Driver程序就会开始进行任务的执行流程图生成,此时会产生一个DAG的有向无环图,执行各个stage节点,以及划分区数的操作
4.1:先根据py4j读取spark程序中的代码,创建 sparkcontext对象
4.2:检查后续一共使用到哪些算子,再根据这些算子划分stage阶段(每个节点划分为几个区,对应有几个线程执行),并生成DAG执行流程图
4.3:通知executor进行执行对应的任务操作即可
4.4:监控各个executor执行进度,等待执行完成,关闭sparkcontext对象,释放资源,通知applicationmaster已经执行完成
5- executor接收到Driver程序分配任务后, 开始运行执行任务即可, 如果任务的结果需要返回给Driver, 此时将结果数据返回即可, 如果不需要, 直接输出操作, 那么Task程序就直接将结果输出即可
6- AppMaster收到Driver程序处理完成的信息后, 通知yarn的主节点, 任务执行完成, 回收资源并关闭整个任务
- 以提交到yarn集群为例:部署方式为 cluster
跟部署方式为 client相对比
第1- 步不同:由执行的spark-submit脚本提交的任务给 resourcemanager(yarn的主节点),yarn会为这个任务启动一个applicationMaster程序,后续与任务相关的操作都找这个applicationMaster即可 (任意某个从节点)
第2- 步不同:appMaster会根据任务的信息分别启动Driver程序(让自己同时升级为Driver程序),然后根据executor资源信息向yarn主节点申请资源, 用于启动executor
- 以提交到spark集群为例 部署方式为 client
1- 由执行spark-submit脚本提交任务, 会在当前这个节点根据提交信息启动一个Driver程序, Driver程序会根据资源信息,向Master申请资源, 用于启动executor
2- 当Driver拿到用于启动executor的资源后, 通知相对应的从节点启动executor执行器即可, 当对应节点执行器启动后, 反向响应给Driver程序, 已经启动好了
3- Driver程序就会开始进行任务的执行流程图生成. 此时就会产生DAG执行流程图, 划分各个执行stage节点, 以及划分分区数等操作:
3.1:首先根据py4j 读取spark程序中代码,创建sparkContext对象
3.2:检查后续一共使用到那些算子, 根据这些算子划分stage阶段(每个节点划分为几个分区, 对应有几个线程执行), 并生成DAG执行流程图
3.3:通知各个executor进行执行对应任务操作即可
3.4:监控各个executor执行进度, 等待执行完成, 关闭sparkContext对象, 释放资源, 通知Master , 任务已经执行完成
4- executor接收到Driver程序分配任务后, 开始运行执行任务即可, 如果任务的结果需要返回给Driver, 此时将结果数据返回即可, 如果不需要, 直接输出操作, 那么Task程序就直接将结果输出即可
5- master收到任务处理完成的信息后, 回收资源即可
- 以提交到spark集群为例 部署方式为 cluster
与部署方式为 client对比
第1- 步不同:由执行spark-submit脚本提交任务到 spark集群的Master节点, Master会根据提交信息, 在某一个worker节点上, 启动一个Driver程序
。。。。。。。。。。
剩下的步骤相同
spark-submit想关的参数
spark-submit.sh脚本的作用
-
用于将spark程序提交到指定的资源调度平台上进行运行,并且在提交过程中,可以对资源设置相关的配置信息
-
基本参数
--master :用于指定提交到那个资源调度平台 (可选择: local| spark | yarn ....)
-- deploy-mode: 用于指定提交部署方式(可选择: client 和 cluster)
--conf : 用于设置相关配置信息
python-file : 指定spark的python脚本
args: 添加程序入口参数, 如果没有参数是可以不配置的
spark-core的内容(核心部分)
RDD的基本介绍
-
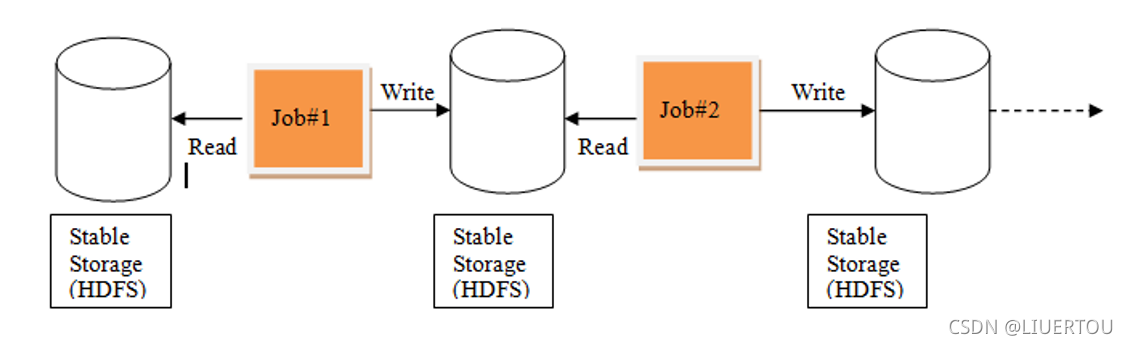
MR的计算过程
-
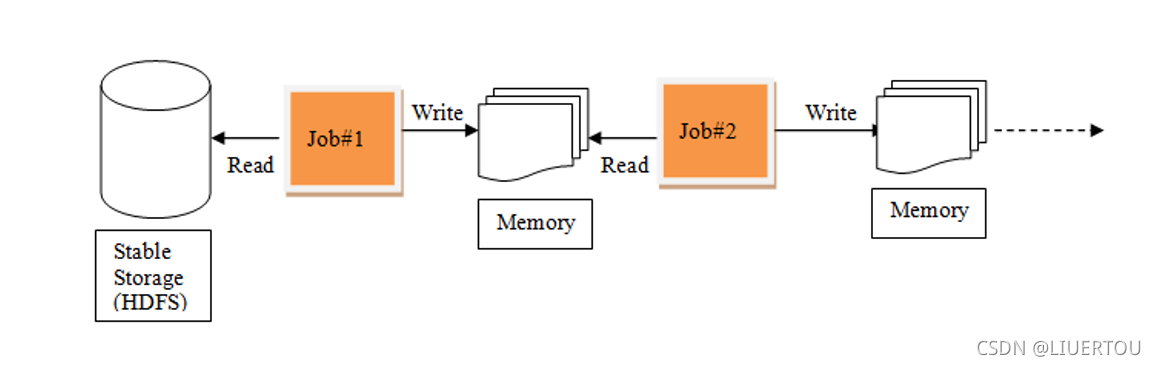
RDD的计算过程
-
背景说明
1)在早期的计算模型: 单机模型
比如: pandas , mysql
依赖于单个节点的性能
适用于: 少量数据集统计分析的处理
在计算过程中,数据都是在一个进程中的,不断地进行迭代计算操作
2)当数据量大了以后, 单机的这种计算的模式就无法支撑了,此时需要分布式的计算的模型
核心:让多个节点参与计算, 将计算任务进行划分, 将这个部分交给各个节点进行运行, 运算后, 将结果进行汇总
比如:MapReduce, spark
MapReduce计算的模型:
在计算过程中, 每一个MR都是有两部分组成: map 和 reduce,在计算过程中, 需要将数据从磁盘读取内存中, 从内存落入磁盘, 再从磁盘读取到内存中, 这样导致整个IO变大, 不断的与磁盘进行交互, 整个执行效率 也是比较低的
由于一个MR只有map和reduce节点, map进行分布式计算, 计算reduce汇总统计, 如果需要进行多次的分布式计算和多次聚合统计(迭代计算), 对于MR来说, 必须使用多个MR进行串行执行了,而这样的执行导致每一个MR都需要重新申请资源, 回收资源, 大量的时候都消耗在了资源申请和回收上, 而且这种操作中间结果只能保存在磁盘中, 导致效率比较低
正因为有了这个MR问题后, 此时想办法解决问题,解决问题思路:
1) 是否可以让中间结果都保存在内存中, 这样效率是不是就比较高了
2) 是否可以在一个程序中完成多次的不断迭代计算操作
什么是RDD
RDD:弹性的分布式数据集
RDD的目的:主要用于支持更加高效的迭代计算
- RDD的五大特性
注:1,2,3是必须有的 4,5可选
1- 可以分区的:每一个分区对应了一个task线程
2-< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









