









python 3.6 正则表达式的应用
正则表达式用于搜索、替换和解析字符串。正则表达式遵循一定的语法规则,使用非常灵活,功能强大。使用正则表达式编写一些逻辑验证非常方便,例如电子邮件地址格式的验证。Python提供了re模块实现正则表达式的验证。
正则表达式简介
正则表达式是用于文本匹配的工具,它在源字符串中查找与给定的正则表达式相匹配的部分。一个正则表达式是由字母、数字和特殊字符(括号、星号、问号等)组成。正则表达式中有许多特殊的字符,这些特殊字符是构成正则表达式的要素。
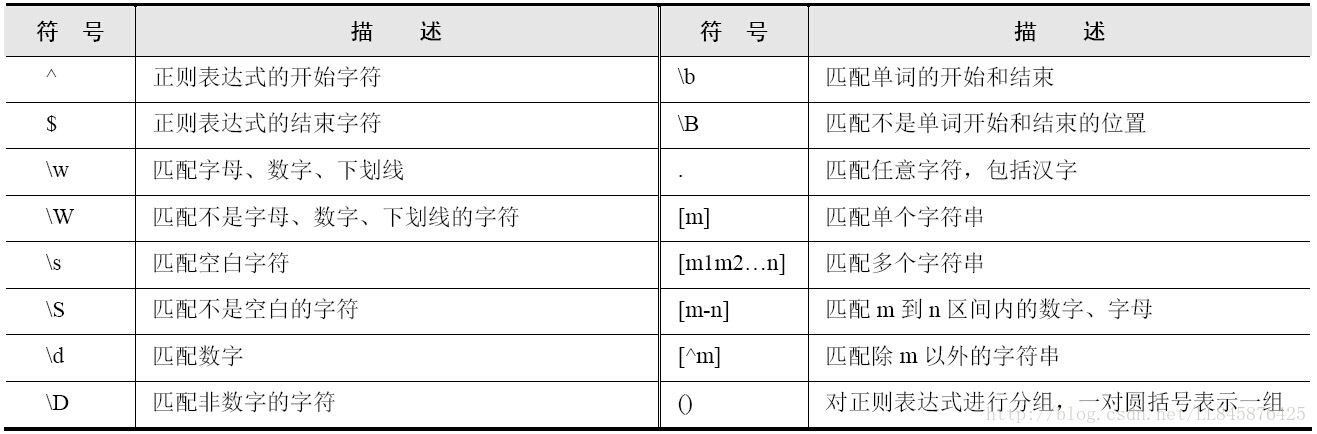
其中,匹配符“[]”可以指定一个匹配范围,
例如“[ok]”将匹配包含“o”或“k”的字符。同时“[]”可以与\w、\s、\d等标记等价。例如,[0-9a-zA-Z_]等价于\w,[^0-9]等价于\D。注意 \^与[\^m]中的“\^”的含义并不相同,后者的“\^”表示“除了……”的意思。
如果要匹配电话号码,需要形如“\d\d\d\d-\d\d\d\d\d\d\d”这样的正则表达式。其中出现了11次“\d”,表达方式烦琐。而且某些地区的电话号码是8位数字,区号也有可能是3位或4位数字,因此这个正则表达式就不能满足要求了。
正则表达式作为一门小型的语言,还提供了对表达式的一部分进行重复处理的功能。例如,“*”可以对正则表达式的某个部分重复匹配多次。这种匹配符号称为限定符。
下表列出了正则表达式中常用的限定符:

利用{}可以控制字符重复的次数。例如,\d{1,4}表示1~3位数字。前面提到的电话号码,可以采用如下的正则表达式。

\d{3}-\d{8} | \d{4}-\d{7}
【代码说明】该表达式匹配区号为3位的8位数电话号码或区号为4位的7位数电话号码。
注意 “(”和“)”是正则表达式中的特殊字符,如果要把它们作为普通字符处理,需要在前面添加转义字符“\”。

注意 表中的(?P…)和(?P=name)是Python中的写法,其他的符号在各种编程语言中都是通用的。
使用re模块处理正则表达式
Python的re模块具有正则表达式匹配的功能。re模块提供了一些根据正则表达式进行查找、替换、分隔字符串的函数,这些函数使用一个正则表达式作为第一个参数。
re模块常用的函数如下所示:
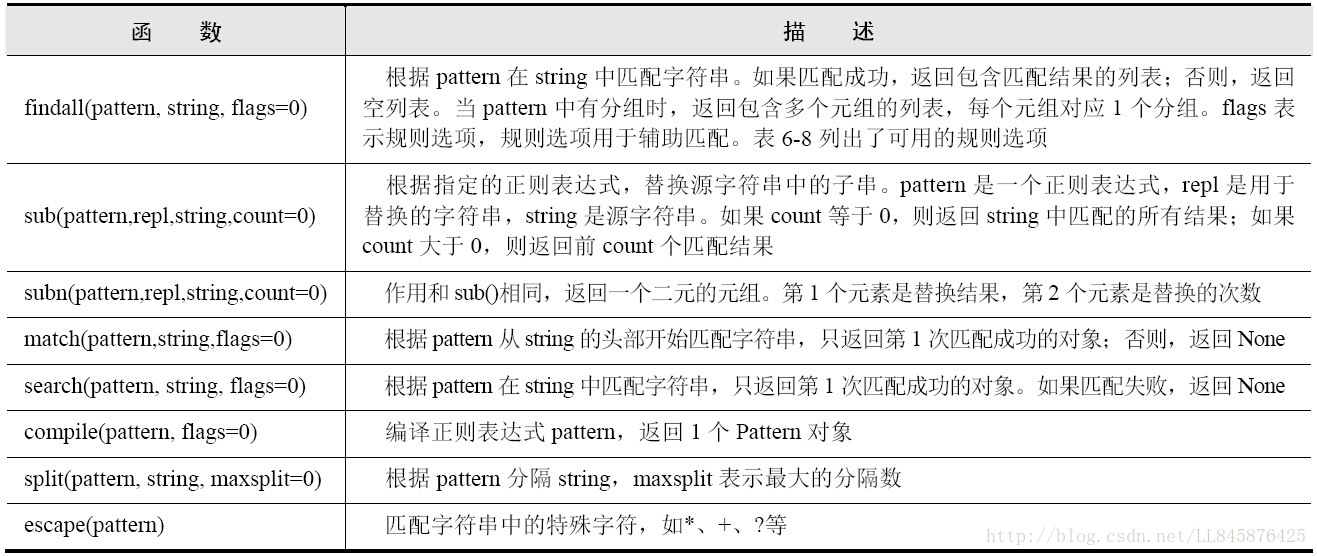
注意 函数match()必须从字符串的第0个索引位置处开始搜索。如果第0个索引位置的字符不匹配,match()的匹配失败。
re模块的一些函数中都有一个flags参数,该参数用于设置匹配的附加选项。例如,是否忽略大小写、是否支持多行匹配等。
下表列出了re模块的规则选项。



re模块定义了一些常量来表示这些选项,使用前导符“re.”加选项的简写或名称的方式表示某个常量。例如,re.I或re.IGNORECASE表示忽略大小写。
正则表达式中有3种间隔符号:“^”、“$”和“\b”。
“^”匹配字符串首部的子串,“$”匹配结束部分的子串,而“\b”用于分隔单词。下面这段代码展示了这些间隔符在Python中的使用。
import re
# ^与$的使用
string = "HELLO WORLD"
print(re.findall(r"^hello", string))
print(re.findall(r"^hello", string, re.I))
print(re.findall("WORLD$", string))
print(re.findall(r"WORLD$", string))
print(re.findall(r"WORLD$", string, re.I))
print(re.findall(r"\b\w+\b", string))【代码说明】
- 第4行代码匹配以“hello”开始的字符串。由于变量s中的“HELLO”采用的是大写,所有匹配失败。输出结果为“[]”。
- 第5行代码添加了辅助参数flags,re.I表示匹配时忽略大小写。输出结果为“[‘HELLO’]”。
- 第6行代码匹配以“WORLD”结尾的字符串。输出结果为“[‘WORLD’]”。
- 第7行代码匹配以“WORLD”结尾的字符串,并忽略大小写。输出结果为“[‘WORLD’]”。
- 第8行代码匹配每个英文单词。输出结果为“[‘HELLO’,’WORLD’]”。
在python中可以使用函数replace()实现字符串的替换,同样可以使用re模块的sub()实现替换的功能。
下面这段代码演示了sub()替换字符串的功能。
import re
# 使用sub()实现字符串的替换
string = "hello world"
print(re.sub("hello", "hi", string))
print(re.sub("hello", "hi", string[-4:]))
print(re.sub("world", "China", string[-5:]))【代码说明】
- 第4行代码的输出结果为“hi world”。
- 第5行代码在分片s[-4:]范围内替换“hello”,即在字符串“orld”中替换“hello”。由于没有找到匹配的子串,所有sub()返回s[-4:]。输出结果为“orld”。
- 第6行代码在分片s[-5:]范围内替换“world”,即把字符串“world”替换为“China”。输出结果为“China”。
注意 sub()先创建变量s的拷贝,然后在拷贝中替换字符串,并不会改变变量s的内容。
subn()的功能与sub()相同,但是多返回1个值,即匹配后的替换次数。
下面这段代码演示了subn()对字符串的替换以及正则表达式中特殊字符的使用。
import re
# 特殊字符的使用
string = "你好 WORLD2"
print("匹配字母数字:" + re.sub(r"\w", "hi", string))
print("替换次数:" + str(re.subn(r"\w", "hi", string)))
print("匹配非字母数字的字符:" + re.sub(r"\W", "hi", string))
print("替换次数:" + str(re.subn(r"\W", "hi", string)[1]))
print("匹配空白字符:" + re.sub(r"\s", "*", string))
print("替换次数:" + str(re.subn(r"\s", "*", string)))
print("匹配非空白字符:" + re.sub(r"\S", "#", string))
print("替换次数:" + str(re.subn(r"\S", "#", string)[1]))
print("匹配数字:" + re.sub(r"\d", "2.0", string))
print("替换次数:" + str(re.subn(r"\d", "2.0", string)[1]))
print("匹配非数字:" + re.sub(r"\D", "&", string))
print("替换次数:" + str(re.subn(r"\D", "&", string)[1]))
print("匹配任意字符:" + re.sub(r".", "%", string))
print("替换次数:" + str(re.subn(r".", "%", string)[1]))【代码说明】
- 第4行代码,“\w”并不能匹配汉字。
- 第5行代码输出替换次数。替换次数存放在subn()返回元组的第2个元素中。
- 第6行代码替换非字母、数字、下划线的字符。
- 第7行代码,汉字“你好”和后面的空格被替换为5个“hi”,每个汉字占2个字符。
- 第8行代码匹配空白字符,空格、制表符等都属于空白字符。
- 第9行代码,由于只有一个空格,所以替换次数为1。
- 第10行代码替换非空格字符。
- 第11行代码,除空格外字符串共占用了10个字符。
- 第12行代码替换数字。
- 第13行代码把数字2替换为“2.0”。
- 第14行代码替换每个英文字符。
- 第15行代码替换了10个非数字字符。
- 第16行代码,“.”替换任意字符。
- 第17行代码,所有11个字符均被替换。
正则表达式的解析非常费时,如果多次使用同一规则匹配字符串,可以使用compile()进行预编译,compile函数返回1个pattern对象。该对象拥有一系列方法用于查找、替换或扩展字符串,从而提高字符串的匹配速度。下表列出了pattern对象的属性和方法。

下面这段代码在1个字符串中查找多个数字,使用compile()提高查找的效率。
import re
# compile()预编译
string = "1abc23def45"
pat = re.compile(r"\d+")
print(pat.findall(string))
print(pat.pattern)【代码说明】
- 第4行代码返回1个正则表达式对象p,匹配变量s中的数字。
- 第5行代码调用p的findall()方法,匹配的结果存放在列表中。输出结果为“[‘1’,’23’,’45’]”。
- 第6行代码输出当前使用的正则表达式。输出结果为“\d+”。
函数compile()通常与match()、search()、group()一起使用,对含有分组的正则表达式进行解析。正则表达式的分组从左往右开始计数,第1个出现的圆括号标记为第1组,依次类推。此外还有0号组,0号组用于存储匹配整个正则表达式的结果。match()和search()将返回1个match对象,match对象提供了一系列的方法和属性来管理匹配的结果。
下表列出了match对象的方法和属性。

下面这段代码演示了对正则表达式分组的解析。
import re
# 分组
pat = re.compile(r"(abc)\1")
mat = pat.match("abcabcabc")
print(mat.group(0))
print(mat.group(1))
print(mat.group())
pat = re.compile(r"(?P<one>abc)(?P=one)")
mat = pat.search("abcabcabc")
print(mat.group("one"))
print(mat.groupdict().keys())
print(mat.groupdict().values())
print(mat.re.pattern)【代码说明】
- 第3行代码定义了1个分组“(abc)”,在后面使用“\1”再次调用该分组。即compile()返回1个包含2个分组的正则表达式对象p。
- 第4行代码,p.match()对字符串“abcabcab”进行搜索,返回1个match对象m。
- 第5行代码调用match对象的group(0)方法,匹配0号组。输出结果为“abcabc”。
- 第6行代码调用match对象的group(1)方法,匹配1号组。输出结果为“abc”。
- 第7行代码,默认情况下,返回分组0的结果。输出结果为“abcabc”。
- 第9行代码,给分组命名,“?P”中的“one”表示分组的名称。“(?P=one)”调用分组“one”,相当于“\1”。
- 第11行代码输出分组“one”的结果。输出结果为“abc”。
- 第12行代码获取正则表达式中分组的名称。输出结果为“[‘one’]”。
- 第13行代码获取正则表达式中分组的内容。输出结果为“[‘abc’]”。
- 第13行代码获取正则表达式中分组的内容。输出结果为“[‘abc’]”。
- 第14行代码获取当前使用的正则表达式。输出结果为“(?Pabc)(?P=one)”。
如果使用match()匹配的源字符串“abcabcabc”改为“bcabcabc”,则Python将提示如下错误。

AttributeError: 'NoneType' object has no attribute 'group'
这种情况可以用search()替换match(),search()可以匹配出正确的结果。















 6639
6639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









