







一、传统RNN存在的问题
1)容易出现梯度爆炸和梯度弥散
虽然在某些情况下,其参数比卷积神经网络要少很多。但是,RNN并没有我们想象中的那么完美,随着循环次数的叠加,其梯度很容易出现梯度爆炸或者梯度弥散,而导致这个缺陷产生的主要原因是,传统RNN在计算梯度时,其公式中存在一个的k次方。具体出现的原因我们在上一篇博客中有详细讲解,下面给出链接:
第七章:Tensorflow2.0 RNN循环神经网络实现IMDB数据集训练(理论+实践)
由于其梯度求解公式中有的k次方的存在,所以会出现下面的极限情况:
,则:
接近于无穷大;出现梯度爆炸
,则:
接近于0;出现梯度弥散
2)memory记忆不足
虽然我们使用了一个全局的memory去记录全局的语境信息,但实际上,memory只能记住很短的全局信息,随着迭代次数的增加,memory会渐渐遗忘前面的语境信息。
解决方法
1)针对梯度爆炸,最简单有效的方法就是对每次求得的梯度,都进行缩放。即保持其梯度方向不变,梯度模长度缩放到某一范围。这样做能使得当前梯度前进的距离控制在某一个较小范围。具体方法如下:
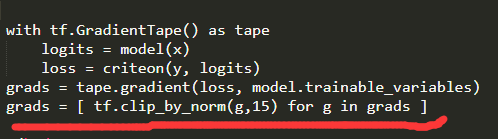
tf.clip_by_norm(x, number):该函数能按照L2正则项的方式把x缩放到[0 , number]范围中,并保持其方向不变。
2)针对梯度弥散和memory记忆不足的缺陷,我们可以使用长短期记忆网络(LSTM)或者GRU。
二、长短期记忆网络(LSTM)
一个句子中,并不是所有单词都是有用的,也不是所有单词之间的语义是需要记住的,所以,LSTM网络在传统RNN网络中设置了三道闸门用于控制不同对象的输出量,达到选择性记忆的目的。下面给出第一道闸门------遗忘门或者记忆门的函数定义形式和工作原理:
是一个用于线性变化的矩阵,
是一个偏置。
是一个sigmoid函数,它能把输入值映射到[0,1]之间,即
。在得到
后,我们只需要让输入量和
向乘,即可达到控制输出量的大小。其他两个闸门的函数定义形式和工作原理与第一道闸门除了
和
不相同外,其他的都一样。下面将详细讲解这三道闸门分别控制的是那些输出量。
1)遗忘门或者记忆门
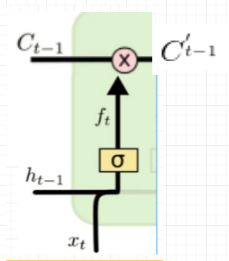
可由公式
求得,
表示t-1时刻输出的memory,
表示t-1时刻memory的中间状态,该状态影响着新memory参生的输入量,
表示t时刻输入的训练数据,
表示
和
相乘。
表示t时刻记住t-1时刻的信息。
2)输入门

输入门公式:
表示t-1时刻memory和t时刻输入值进过tanh函数后得到的输入值,
和
相乘再和经过第一道记忆门过滤后的值进行相加得到
,
是LSTM网络中memory的中间状态。其决定着t时刻最终的memory输出。
3)输出门

输出门公式:
输出门利用输出了t时刻最终的memory(
)。
三、LSTM是如何减轻梯度弥散的?
在LSTM网络中,其梯度由原来相乘的形式变成了三道门相加的形式,避免了的k次方的出现,所以,不会轻易的出现梯度弥散的情况,也减轻了memory信息衰退的情况,其具体求导公式如下:

实战部分
此次实战代码是在第七章的代码上进行修改的,代码中有什么看不懂的 大家可以之间去第七章中查看,这里附上链接:
第七章:Tensorflow2.0 RNN循环神经网络实现IMDB数据集训练(理论+实践)
当我们理解LSTM的工作原理后,在代码实现上就很简单,只需要在原来代码自定义层的代码块中,稍作修改即可:

修改成如下:
即每一层的状态都变成了两个(一个是memory,一个是memory的中间状态)layers.SimpleRNNCell变成layers.LSTMCell即可,其他地方的代码不变。下面给出完整代码:
import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import time
print(np.__version__)
tf.random.set_seed(22)
np.random.seed(22)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = '2'
assert tf.__version__.startswith('2.')
total_words = 10000
max_review_len = 80
batchsz = 128
embedding_len = 100
(x_train, y_train) , (x_test, y_test) = keras.datasets.imdb.load_data(num_words = total_words)
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen = max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen = max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.shuffle(1000).batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x test shape:', x_test.shape)
class MyRnn(keras.Model):
def __init__(self, units):
super(MyRnn,self).__init__()
self.state0 = [tf.zeros([batchsz, units]),tf.zeros([batchsz, units])]
self.state1 = [tf.zeros([batchsz, units]),tf.zeros([batchsz, units])]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length = max_review_len)
self.rnn_cell0 = layers.LSTMCell(units, dropout=0.2)
self.rnn_cell1 = layers.LSTMCell(units, dropout=0.2)
self.outlayer = layers.Dense(1)
def call(self, inputs, training=None):
x = inputs
x = self.embedding(x)
state0 = self.state0
state1 = self.state1
for word in tf.unstack(x, axis=1):
out0, state0 = self.rnn_cell0(word, state0, training)
out1, state1 = self.rnn_cell1(out0, state1)
x = self.outlayer(out1)
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epoch = 4
start_time = time.time()
model = MyRnn(units)
model.compile(optimizer= keras.optimizers.Adam(0.001),
loss=tf.losses.BinaryCrossentropy(),
metrics = ['accuracy'])
model.fit(db_train, epochs= epoch, validation_data = db_test)
model.evaluate(db_test)
end_time = time.time()
print('all time: ' ,end_time - start_time)
if __name__ == '__main__':
main()第一章:Tensorflow 2.0 实现简单的线性回归模型(理论+实践)
第二章:Tensorflow 2.0 手写全连接MNIST数据集(理论+实战)
第三章:Tensorflow 2.0 利用高级接口实现对cifar10 数据集的全连接(理论+实战实现)
第四章:Tensorflow 2.0 实现自定义层和自定义模型的编写并实现cifar10 的全连接网络(理论+实战)
第五章:Tensorflow 2.0 利用十三层卷积神经网络实现cifar 100训练(理论+实战)















 4725
4725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









