







数据归一化(Normalization)
归一化是将数据缩放到特定范围(通常是[0, 1]),特别适用于距离度量敏感的算法,如K近邻算法。
原理
归一化后的数据每个特征的取值范围相同,有助于提高某些机器学习算法的性能。通过归一化,可以消除特征值范围的差异,使得各特征在同一尺度下进行比较和分析。
核心公式
归一化公式:
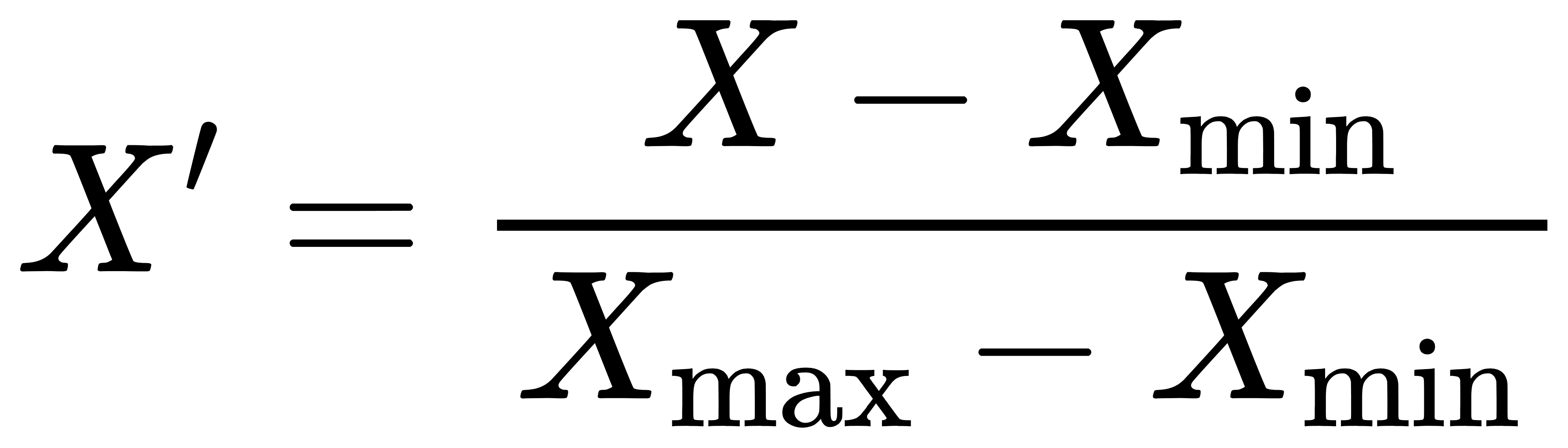
其中, Xmin 和 Xmax 分别是特征的最小值和最大值。
假设特征 X 的最小值和最大值分别为 Xmin 和 Xmax,则归一化后的数据 X′ 为:
案例
假设我们有一个包含不同家庭的收入和支出的数据集,我们需要对这些数据进行归一化,以便后续的分析和建模。
代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
# 1. 创建一个随机数据集(模拟家庭收入和支出)
np.random.seed(42)
data = {
'Income': np.random.normal(loc=50000, scale=15000, size=100), # 家庭收入,均值50000元,标准差15000元
'Expenses': np.random.normal(loc=30000, scale=10000, size=100) # 家庭支出,均值30000元,标准差10000元
}
# 创建一个DataFrame
df = pd.DataFrame(data)
# 显示原始数据集
print("原始数据集:")
print(df.head(10))
# 2. 对数据进行归一化
scaler = MinMaxScaler()
data_normalized = scaler.fit_transform(df)
# 创建归一化后的DataFrame
df_normalized = pd.DataFrame(data_normalized, columns=['Income', 'Expenses'])
# 显示归一化后的数据集
print("\n归一化后的数据集:")
print(df_normalized.head(10))
# 3. 绘制归一化前后的数据分布直方图
plt.figure(figsize=(14, 6))
# 归一化前
plt.subplot(1, 2, 1)
plt.hist(df['Income'], bins=20, alpha=0.7, label='Income', color='blue')
plt.hist(df['Expenses'], bins=20, alpha=0.7, label='Expenses', color='green')
plt.title('Before Normalization')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.legend()
# 归一化后
plt.subplot(1, 2, 2)
plt.hist(df_normalized['Income'], bins=20, alpha=0.7, label='Income', color='blue')
plt.hist(df_normalized['Expenses'], bins=20, alpha=0.7, label='Expenses', color='green')
plt.title('After Normalization')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.legend()
plt.tight_layout()
plt.show()
# 4. 绘制归一化前后的数据散点图
plt.figure(figsize=(14, 6))
# 归一化前
plt.subplot(1, 2, 1)
plt.scatter(df['Income'], df['Expenses'], color='blue', alpha=0.7)
plt.title('Before Normalization')
plt.xlabel('Income')
plt.ylabel('Expenses')
# 归一化后
plt.subplot(1, 2, 2)
plt.scatter(df_normalized['Income'], df_normalized['Expenses'], color='red', alpha=0.7)
plt.title('After Normalization')
plt.xlabel('Income')
plt.ylabel('Expenses')
plt.tight_layout()
plt.show()解释
- 创建数据集:首先,我们创建一个包含家庭收入和支出的虚构数据集,并存储在一个DataFrame中。
- 对数据进行归一化:使用
MinMaxScaler对数据进行归一化,将其缩放到[0, 1]范围内。 - 绘制归一化前后的数据分布直方图:通过直方图展示归一化前后的数据分布情况。
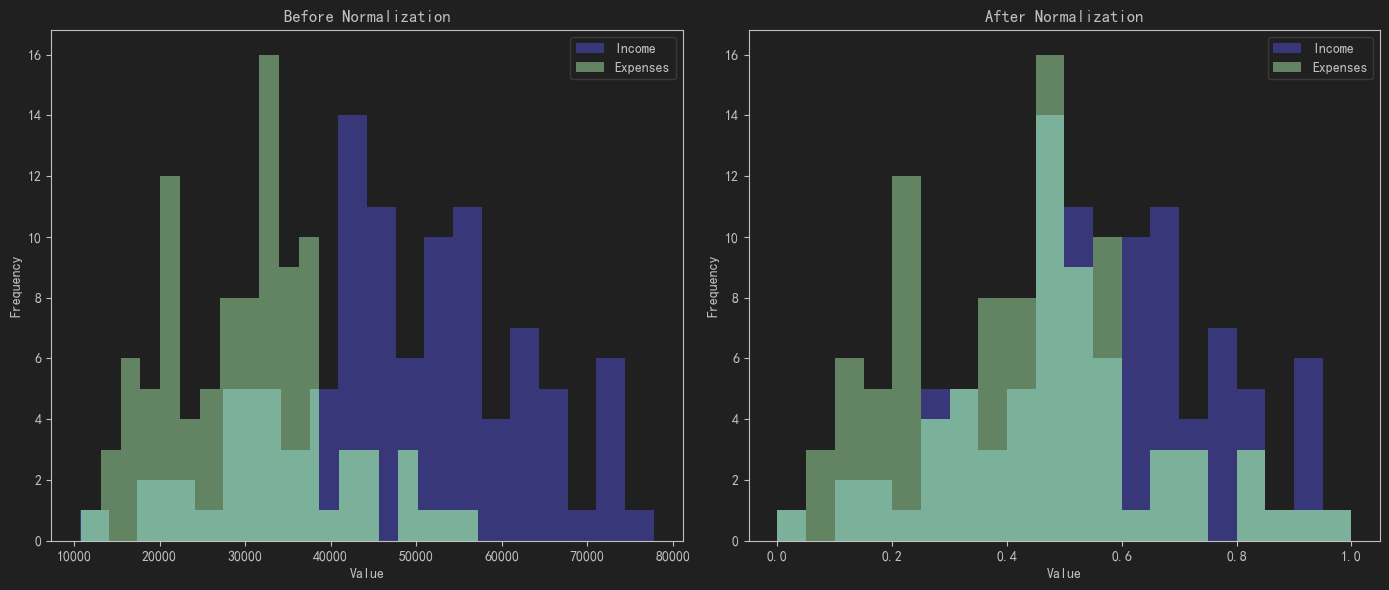
- 绘制归一化前后的数据散点图:通过散点图展示归一化前后的数据分布情况。
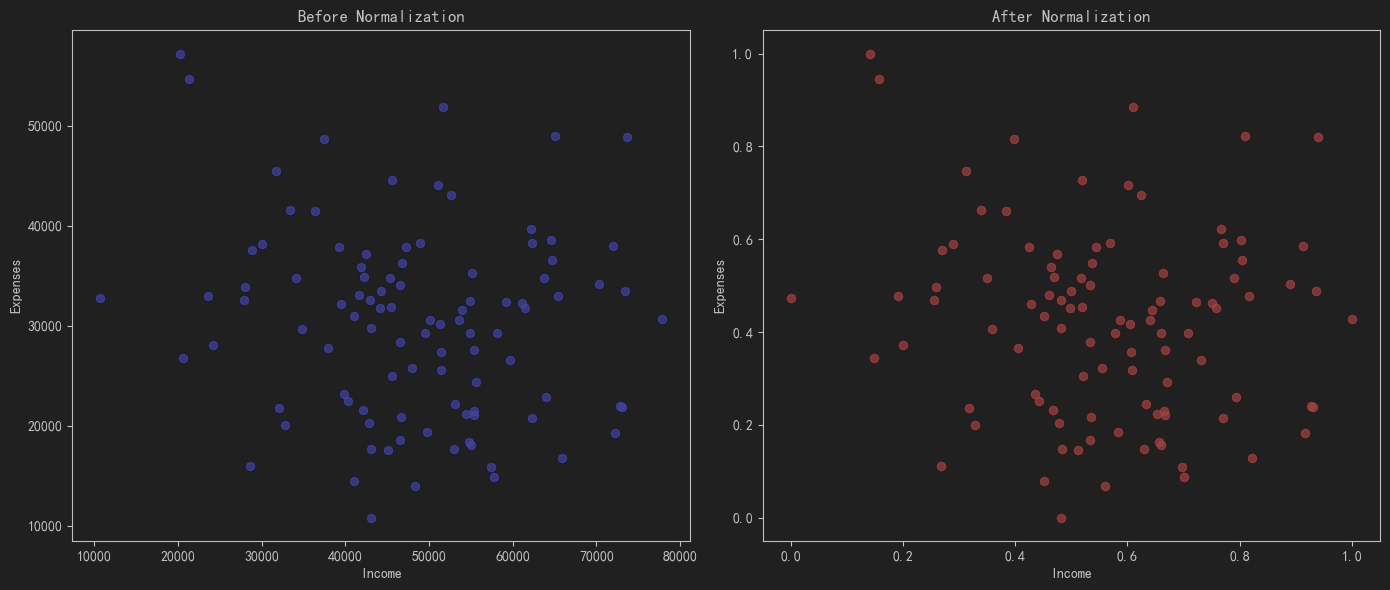
通过以上步骤,我们可以有效地归一化数据,并通过可视化手段展示归一化前后的数据变化。这对于理解归一化对数据的影响非常有帮助。
类别编码(Categorical Encoding)
将类别特征转换为数值形式,以便机器学习算法能够处理。
原理
机器学习算法通常只能处理数值特征,因此需要将类别特征转换为数值。常用的方法包括独热编码(One-Hot Encoding)、标签编码(Label Encoding)等。
核心公式
独热编码(One-Hot Encoding): 对于一个类别特征 XXX 具有 nnn 个不同的类别,将其转换为 nnn 维向量,其中只有一个位置为1,其余为0。
例如,假设特征 XXX 有三个类别:红色、绿色、蓝色。则:
- 红色:[1, 0, 0]
- 绿色:[0, 1, 0]
- 蓝色:[0, 0, 1]
案例
假设我们有一个包含家庭的城市、性别、年龄和收入的数据集,我们需要对这些数据进行类别编码,以便后续的分析和建模。
代码实现
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder
# 生成示例数据
data = {
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix', 'New York', 'Los Angeles', 'Chicago'],
'Gender': ['Male', 'Female', 'Female', 'Male', 'Male', 'Female', 'Female', 'Male'],
'Age': [25, 30, 22, 35, 40, 29, 23, 37],
'Income': [70000, 80000, 60000, 120000, 110000, 75000, 65000, 130000]
}
df = pd.DataFrame(data)
# 原始数据的描述性统计
print("原始数据描述性统计:")
print(df.describe(include='all'))
# 可视化原始数据
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.countplot(x='City', data=df)
plt.title('City Distribution')
plt.subplot(1, 2, 2)
sns.boxplot(x='Gender', y='Income', data=df)
plt.title('Income by Gender')
plt.tight_layout()
plt.show()
# 类别编码
encoder = OneHotEncoder(sparse_output=False)
encoded_features = encoder.fit_transform(df[['City', 'Gender']])
encoded_feature_names = encoder.get_feature_names_out(['City', 'Gender'])
encoded_df = pd.DataFrame(encoded_features, columns=encoded_feature_names)
encoded_df['Age'] = df['Age']
encoded_df['Income'] = df['Income']
# 编码后的数据的描述性统计
print("编码后的数据描述性统计:")
print(encoded_df.describe(include='all'))
# 可视化编码后的数据
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.heatmap(encoded_df.corr(), annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Correlation Heatmap')
plt.subplot(1, 2, 2)
sns.boxplot(x='City_New York', y='Income', data=encoded_df)
plt.title('Income by New York City Category')
plt.tight_layout()
plt.show()
解释
- 创建数据集:首先,我们创建一个包含家庭所在城市、性别、年龄和收入的虚构数据集,并存储在一个DataFrame中。
- 描述性统计:使用
describe函数查看原始数据的描述性统计信息,包括计数、均值、标准差、最小值、四分位数和最大值。 - 可视化原始数据:使用Seaborn库绘制原始数据的分布图和箱线图,以了解数据的分布情况。
- 类别编码:使用
OneHotEncoder对类别特征(城市和性别)进行独热编码,并将编码后的特征与原始数值特征(年龄和收入)合并到新的DataFrame中。 - 编码后的描述性统计:查看编码后的数据的描述性统计信息,确保编码过程正确。
- 可视化编码后的数据:使用热力图展示编码后数据的相关性,并使用箱线图展示编码后的特征与收入之间的关系。
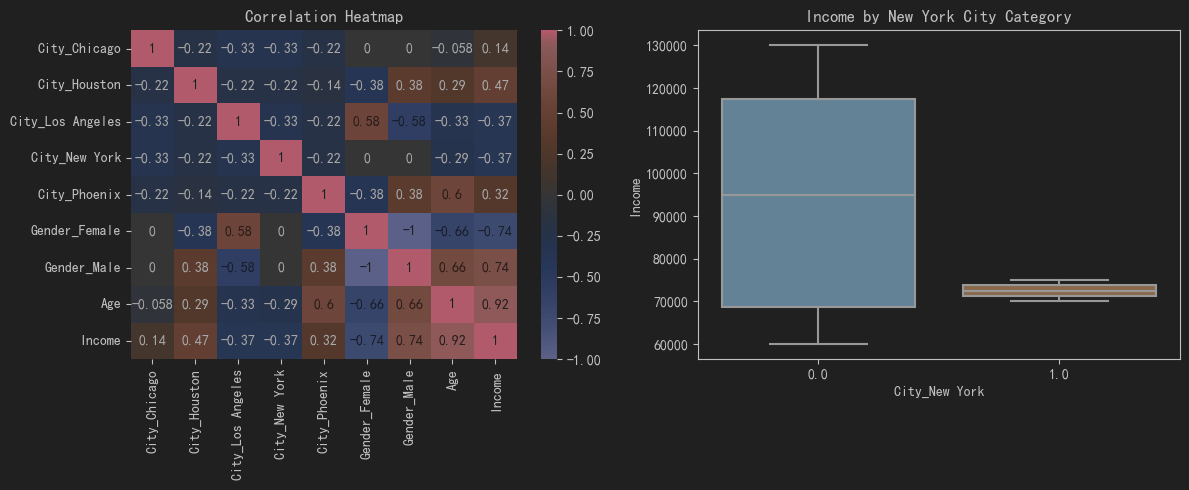
通过以上步骤,我们可以有效地将类别特征转换为数值特征,并通过可视化手段展示编码前后的数据变化。这对于理解类别编码对数据的影响非常有帮助。















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









