







【异常检测】数据挖掘领域常用异常检测算法总结以及原理解析(一)
一、基于统计的方法
基于统计的异常检测方法主要依赖于统计学原理来识别数据中的异常值。这些方法通常假设数据遵循一定的统计分布,如正态分布等。
1. 3sigma
基于正态分布,3sigma准则认为超过3sigma的数据为异常点。
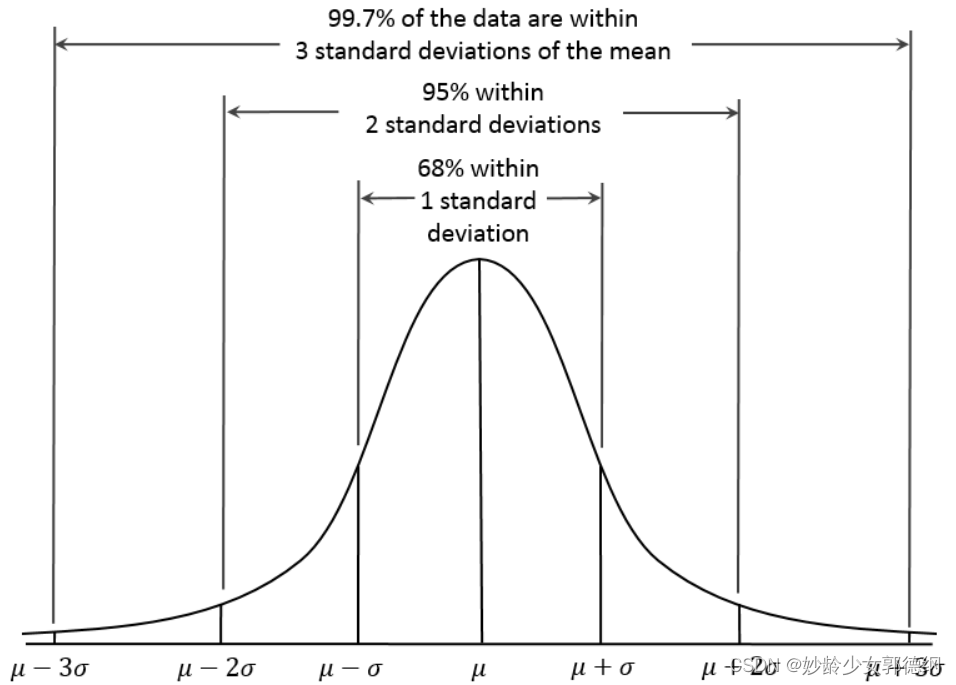
如果数据处于均值加减三倍标准差之间,则认为是正常数据,否则,则认为是异常数据。
2. Z-Score(标准分数)
Z-Score(标准分数)异常检测方法是通过测量数据点与数据集均值的偏差程度来识别异常数据的。这种方法假设数据大致遵循正态分布(也称为高斯分布)。在正态分布中,大多数数据点(约68%)位于均值的一个标准差内,约95%的数据位于两个标准差内,而几乎所有的数据(约99.7%)位于三个标准差内。
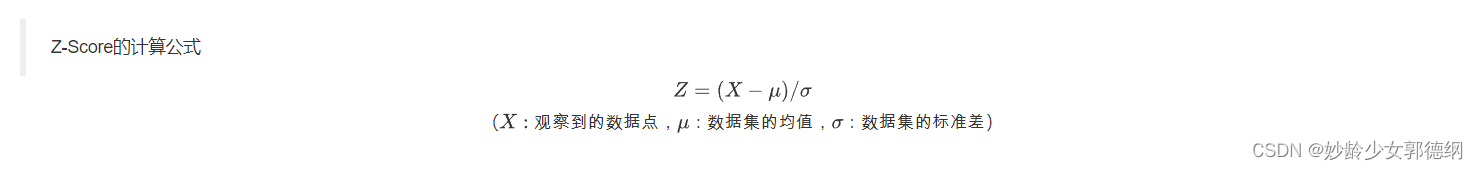
识别异常数据
- 在Z-Score方法中,较高或较低的Z-Score值表示数据点与均值相比有显著的偏差。
- 通常,如果一个数据点的Z-Score的绝对值很高(例如,高于2或3),它就被认为是异常的。这意味着该数据点距离平均值相当远。例如,如果我们选择Z-Score的阈值为3,那么任何Z-Score大于3或小于-3的数据点都会被认为是异常的(与3sigma一致)。这基于统计学上的标准,即在正态分布中,距离均值超过3个标准差的数据点是非常罕见的。
应用场景
- 数据分布:Z-Score最适合于接近正态分布的数据。如果数据显著偏离正态分布,这种方法可能不那么有效。
- 异常值的影响:由于Z-Score方法依赖于均值和标准差,异常值本身可能会显著影响这两个参数,从而影响异常检测的结果。在实际应用中,决定什么样的Z-Score阈值用于标识异常通常取决于特定的应用场景和对于异常数据的敏感度。
综上所述,Z-Score方法是一种有效的工具来识别那些在统计上显著偏离大多数数据的数据点,但它的有效性取决于数据的分布和所选的阈值。
3. Grubbs’ Test(格拉布斯检验)
Grubbs’ Test(格拉布斯检验)是一种用于检测数据集中单个异常值的统计检验方法。这种方法假设数据遵循正态分布,并旨在确定数据集中是否存在一个显著偏离其他数据点的观测值。

识别异常数据
- 计算Grubbs’ 统计量:首先计算数据集中每个数据点的Grubbs’ 统计量。
- 临界值:然后,这个统计量与临界值进行比较。临界值通常基于所需的置信水平(如95%、99%)和数据集的大小,可以通过查看Grubbs’Test的临界值表或使用相关统计软件得到。
- 判断异常:如果计算出的Grubbs’ 统计量大于临界值,那么认为数据集中存在异常值。
应用场景
- 数据分布:Grubbs’ Test最适合于正态分布的数据。如果数据偏离正态分布,这种方法可能不准确。
- 单一异常值:Grubbs’Test主要用于检测数据集中的单个异常值。如果存在多个异常值,这种方法可能不适用。
- 数据大小:Grubbs’Test对于小样本数据可能不那么有效&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









