






图算法之GCN实现原理以及代码
一、什么是GCN
GCN(图卷积网络,Graph Convolutional Network)是一种在图结构数据上进行卷积操作的神经网络架构。它是深度学习领域中处理图数据的一种重要方法,能够捕获图中节点间的复杂关系和特征。GCN的核心思想是通过邻居节点的信息来更新每个节点的表示(这一点与传统的Graph Embedding算法如DeepWalk、Node2Vec等类似,但GCN不仅可以学习到图的结构更能学习到各个节点的属性来生成顶点向量)。这一过程可以看作是在图中进行信息的聚合(Aggregation)和更新(Update),与传统卷积网络(如用于图像的CNN)在局部邻域进行信息处理的思想相似。
邻接矩阵和特征矩阵:在GCN中,图由邻接矩阵(Adjacency Matrix)表示节点间的连接关系,而每个节点的属性由特征矩阵(Feature Matrix)表示。
图卷积操作:图卷积操作是GCN的核心,它包括以下两个步骤:
1.聚合邻居信息:每个节点收集其邻居节点的特征,并可能包括自己的特征,通常使用邻接矩阵与特征矩阵的乘积来实现。
2.转换特征表示:聚合后的信息通过一层神经网络(通常是线性变换后接非线性激活函数)进行处理,以生成新的节点表示。
GCN迭代公式如下所示:
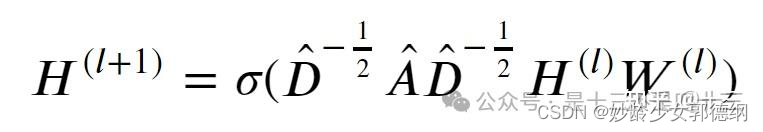
其中, 𝐴̂ =𝐴+𝐼,𝐴是邻接矩阵, 𝐼是单位矩阵,表示添加自环(添加自环主要作用是保留节点自身的特征贡献,在后续进行特征传播时,每个节点的特征不再是自身的特征,而是自身和其邻居节点的特征加权求和。可以保证在特征变换时,节点自身的特征也被考虑在内,从而更准确地反映节点的整体特征), 𝐷̂ 是 𝐴̂ 的度矩阵, 𝑊(𝑙)是层的权重矩阵, 𝜎是非线性激活函数(如 𝑅𝑒𝐿𝑈), 𝐻(𝑙)是第l层的节点特征矩阵。
二、GCN代码实现(TensorFlow)
import tensorflow as tf
from keras.initializers import Identity, glorot_uniform, Zeros
from keras.layers import Dropout, Input, Layer, Embedding, Reshape
from keras.models import Model
from keras.regularizers import l2
import numpy as np
from keras.optimizers import Adam
from scipy.sparse import csr_matrix
# 定义图卷积网络层
# 继承自TensorFlow Layer类
class GraphConvolution(Layer):
def __init__(self, units, activation=tf.nn.relu, dropout_rate=0.5,
use_bias=True, l2_reg=0, feature_less=False,
seed=1024, **kwargs):
super(GraphConvolution, self).__init__(**kwargs)
# 当前卷积层的输出维度
self.units = units
# 是否使用节点特征,False 使用,True 不使用
self.feature_less = feature_less
# 是否添加偏置项
self.use_bias = use_bias
# L2 正则化系数
self.l2_reg = l2_reg
# dropout率
self.dropout_rate = dropout_rate
# 激活函数
self.activation = activation
# 随机种子
self.seed = seed
def build(self, input_shapes):
if self.feature_less:
input_dim = int(input_shapes[0][-1])
else:
assert len(input_shapes) == 2
features_shape = input_shapes[0]
input_dim = int(features_shape[-1])
# 定义图卷积网络的卷积核的权重矩阵
self.kernel = self.add_weight(shape=(input_dim, self.units),
initializer=glorot_uniform(seed=self.seed),
regularizer=l2(self.l2_reg),
name='kernel')
if self.use_bias:
self.bias = self.add_weight(shape=(self.units,),
initializer=Zeros(),
name='bias')
self.dropout = Dropout(self.dropout_rate, seed=self.seed)
# 标记层已经被成功构建
self.built = True
# 前向传播函数
def call(self, inputs, training=None, **kwargs):
features, A = inputs
features = self.dropout(features, training=training)
output = tf.matmul(tf.matmul(A, features), self.kernel)
if self.use_bias:
output += self.bias
act = self.activation(output)
# act._uses_learning_phase = features._uses_learning_phase
return act
# 定义GCN模型
def GCN(adj_dim, feature_dim, n_hidden, num_class, num_layers=2, activation=tf.nn.relu, dropout_rate=0.5, l2_reg=0,
feature_less=True):
# adj_dim: 邻接矩阵的维度。
# feature_dim: 特征维度。
# n_hidden: 隐藏层的节点数。
# num_class: 输出类别数。
# num_layers: 网络层数,默认为2层。
# activation: 激活函数,默认为tf.nn.relu。
# dropout_rate: Dropout比率,用于防止过拟合。
# l2_reg: L2正则化系数。
# feature_less: 是否使用无特征输入,默认为True。
# 接受稀疏矩阵输入
Adj = Input(shape=(None,), sparse=True)
# 不使用节点特征
if feature_less:
X_in = Input(shape=(1,), dtype='int32')
# 将节点映射为feature_dim维
emb = Embedding(adj_dim, feature_dim, embeddings_initializer=Identity(), trainable=False)
X_emb = emb(X_in)
h = Reshape(target_shape=(feature_dim,))(X_emb)
else:
X_in = Input(shape=(feature_dim,))
h = X_in
# 循环构建多层
for i in range(num_layers):
# 最后一层的输出为待预测类别
if i == num_layers - 1:
activation = tf.nn.softmax
n_hidden = num_class
h = GraphConvolution(n_hidden, activation=activation, dropout_rate=dropout_rate, l2_reg=l2_reg)([h, Adj])
output = h
model = Model(inputs=[X_in, Adj], outputs=output)
return model
if __name__ == '__main__':
# GCN 模型调用、训练
# 模拟数据
num_nodes = 5
num_features = 16
num_classes = 3
# 创建一个简单的邻接矩阵(稀疏格式)
# 假设每个节点都至少与自己连接(添加自环)
adj_matrix = np.eye(num_nodes)
adj_sp = csr_matrix(adj_matrix)
# 创建随机特征
features = np.random.rand(num_nodes, num_features)
# 创建随机标签
labels = np.random.randint(0, num_classes, size=(num_nodes,))
# 转换标签为独热编码
labels_onehot = np.eye(num_classes)[labels]
# 构建模型
model = GCN(adj_dim=num_nodes, feature_dim=num_features, n_hidden=32, num_class=num_classes, feature_less=False)
# 编译模型
model.compile(optimizer=Adam(learning_rate=0.01), loss='categorical_crossentropy', metrics=['accuracy'])
# 输入邻接矩阵和特征
model.fit(x=[features, adj_sp], y=labels_onehot, epochs=50, batch_size=num_nodes)
"============================================================================================================="
# 不使用节点特征版本
# 构建模型
model = GCN(adj_dim=num_nodes, feature_dim=num_features, n_hidden=32, num_class=num_classes, feature_less=True)
# 编译模型
model.compile(optimizer=Adam(learning_rate=0.01), loss='categorical_crossentropy', metrics=['accuracy'])
# 准备数据
node_indices = np.arange(num_nodes).reshape(-1, 1) # 节点索引(只有一维节点索引)
adj_matrix = np.random.randint(0, 2, size=(num_nodes, num_nodes)) # 邻接矩阵,随机0或1
labels_onehot = tf.keras.utils.to_categorical(np.random.randint(0, num_classes, size=num_nodes),
num_classes) # 随机标签
# 训练模型
model.fit(x=[node_indices, adj_matrix], y=labels_onehot, epochs=50, batch_size=num_nodes)
pass
三、GCN代码实现(PyTorch)
PyTorch中有现成的GNN库——PyG(PyTorch Geometric Library)。PyTorch Geometric 是一个基于 PyTorch 的开源库,专门用于处理图数据和图神经网络(GNN)。它提供了一组灵活且高效的工具,用于加载、处理和操作图数据,并实现了许多经典和先进的图神经网络模型,这其中就包括GCN。
PyTorch Geometric源码:https://github.com/pyg-team/pytorch_geometric/tree/master
# pip install torch-geometric
# 官方GCN的例子
import argparse
import os.path as osp
import time
import torch
import torch.nn.functional as F
import torch_geometric.transforms as T
from torch_geometric.datasets import Planetoid
from torch_geometric.logging import init_wandb, log
from torch_geometric.nn import GCNConv
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', type=str, default='Cora')
parser.add_argument('--hidden_channels', type=int, default=16)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--epochs', type=int, default=200)
# 是否使用图扩散卷积(图扩散卷积相比普通额图卷积引入了全局图结构信息,
# 更注重全局信息的传播和捕捉)
sparser.add_argument('--use_gdc', action='store_true', help='Use GDC')
parser.add_argument('--wandb', action='store_true', help='Track experiment')
args = parser.parse_args()
if torch.cuda.is_available():
device = torch.device('cuda')
elif hasattr(torch.backends, 'mps') and torch.backends.mps.is_available():
device = torch.device('mps')
else:
device = torch.device('cpu')
init_wandb(
name=f'GCN-{args.dataset}',
lr=args.lr,
epochs=args.epochs,
hidden_channels=args.hidden_channels,
device=device,
)
# 读取数据
path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', 'Planetoid')
dataset = Planetoid(path, args.dataset, transform=T.NormalizeFeatures())
data = dataset[0].to(device)
if args.use_gdc:
transform = T.GDC(
self_loop_weight=1,
normalization_in='sym',
normalization_out='col',
diffusion_kwargs=dict(method='ppr', alpha=0.05),
sparsification_kwargs=dict(method='topk', k=128, dim=0),
exact=True,
)
data = transform(data)
class GCN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, hidden_channels,
normalize=not args.use_gdc)
self.conv2 = GCNConv(hidden_channels, out_channels,
normalize=not args.use_gdc)
def forward(self, x, edge_index, edge_weight=None):
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv1(x, edge_index, edge_weight).relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index, edge_weight)
return x
# 定义GCN模型,有两个图卷积层
model = GCN(
in_channels=dataset.num_features,
hidden_channels=args.hidden_channels,
out_channels=dataset.num_classes,
).to(device)
optimizer = torch.optim.Adam([
dict(params=model.conv1.parameters(), weight_decay=5e-4),
dict(params=model.conv2.parameters(), weight_decay=0)
], lr=args.lr) # Only perform weight-decay on first convolution.
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index, data.edge_attr)
loss = F.cross_entropy(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return float(loss)
@torch.no_grad()
def test():
model.eval()
pred = model(data.x, data.edge_index, data.edge_attr).argmax(dim=-1)
accs = []
for mask in [data.train_mask, data.val_mask, data.test_mask]:
accs.append(int((pred[mask] == data.y[mask]).sum()) / int(mask.sum()))
return accs
best_val_acc = test_acc = 0
times = []
for epoch in range(1, args.epochs + 1):
start = time.time()
loss = train()
train_acc, val_acc, tmp_test_acc = test()
if val_acc > best_val_acc:
best_val_acc = val_acc
test_acc = tmp_test_acc
log(Epoch=epoch, Loss=loss, Train=train_acc, Val=val_acc, Test=test_acc)
times.append(time.time() - start)
print(f'Median time per epoch: {torch.tensor(times).median():.4f}s)
总结
















 1765
1765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









