







Abstract
- 准确、高效、紧凑是实用的面部地标探测器的关键。为了同时考虑这三个问题,本文研究了一个在野外环境(如无约束姿势、表情、灯光和遮挡条件)下具有良好检测精度和超实时速度的移动设备整洁模型。更具体地说,我们定制了一个与加速技术相关的端到端单级网络。在训练阶段,每个样本的旋转信息被估计为几何规则化的地标定位,然后不涉及测试阶段。设计了一种新的损失方法,除了考虑几何规则化之外,还可以通过将样本的权重调整到训练集中的不同状态(如大姿态、极端照明和遮挡)来缓解数据不平衡的问题。我们进行了大量的实验,以证明我们的设计的有效性,并在广泛采用的具有挑战性的基准(即300W(包括IBUG、LFPW、AFW、Helen和XM2VTS)和AFLW)上,展示其优于最新替代产品的性能。我们的型号在高精度的移动电话(高通ARM 845处理器)上仅能达到2.1MB的大小,并达到每面140帧以上,因此对于大规模或实时应用具有吸引力。
Introduction
- 面部地标检测A.K.A.面部定位旨在自动定位人脸上的一组预先定义的识别点(例如眼角、嘴角等)。作为人脸识别[21,49]和验证[27]以及人脸变形[11]和编辑[28]等多种人脸应用程序的基本组成部分,该问题近年来得到了视觉界的广泛关注,并取得了很大的进展。然而,开发一个实用的面部标志性探测器仍然具有挑战性,因为检测精度、处理速度和模型尺寸都应受到关注。
- 在现实生活中,要获得完美的面孔几乎不可能。换句话说,人的脸经常暴露在受控甚至不受约束的环境中。在不同的光线条件下,其外观在姿势、表情和形状上有很大的变化,有时会出现部分遮挡。图1提供了几个这样的例子。此外,数据驱动方法的有效培训数据也是模型性能的关键。在不同的条件下,以平衡的方式捕捉几个人的脸可能是可行的,但是,这种收集方式变得不切实际,尤其是当需要大规模数据来训练(深层)模型时。在这种情况下,人们经常会遇到数据分布不平衡的情况。下面将有关地标探测精度的问题总结为三个挑战。
- 挑战1-局部变化。表达式、局部极端照明(例如,高光和着色)和遮挡会对面部图像带来局部更改/干扰。一些地区的地标可能偏离其正常位置,甚至消失。
- 挑战2-全局变化。姿态和成像质量是影响图像中人脸外观的两个主要因素,当对人脸的总体结构进行错误估计时,会导致大部分标志物定位不良。
- 挑战3-数据不平衡。在浅学习和深学习中,一个可用的数据集在其类/属性之间呈现出不均匀的分布,这并不少见。这种不平衡很可能会使算法/模型无法正确地表示数据的特征,从而在不同的属性上提供不令人满意的精度。上述挑战大大增加了精确检测的难度,要求检测仪具有鲁棒性。
- 随着便携式设备的出现,越来越多的人喜欢随时随地处理自己的业务或享受娱乐。因此,除了追求高检测精度外,还应考虑以下挑战。
- 挑战4-模型效率。对适用性的另外两个限制是模型大小和计算要求。机器人、增强现实和视频聊天等任务预计将在配备有限计算和内存资源(如智能手机或嵌入式产品)的平台上及时执行。
- 这一点特别要求探测器的模型尺寸小,处理速度快。毫无疑问,人们希望建立精确、高效和紧凑的系统,用于实际地标探测。
- 在过去的几十年中,文献中提出了许多经典的面部标志物检测方法。参数化外观模型,带有活动外观模型(AAMS)[6]和约束局部模型(CLMS)[7]作为代表,通过最大限度地提高图像中零件位置的可信度来完成工作。具体来说,AAMS及其后续行动[23、17、20]试图共同模拟整体外观和形状,而CLMS和变体[2、31]则通过施加各种形状约束来学习当地专家组。此外,三结构部分模型(TSPM)[50]使用基于可变形部分的模型进行同时检测、姿态估计和地标定位。这些方法包括显式形状回归(ESR)[5]和监督下降法(SDM)[38]试图用回归的方式解决这个问题。这些方法的主要局限性是针对不同情况的弱鲁棒性、昂贵的计算和/或高模型复杂性。对经典方法的更详细的回顾可以在[32]中找到。
- 最近,基于深度学习的策略在这项任务中占据了最先进的表现。接下来,我们将简要介绍这一类具有代表性的作品。张等。[45]建立了一个称为TCDCN的多任务学习网络,用于共同学习地标位置和姿势属性。由于TCDCN具有多任务性,因此在实践中很难进行培训。Trigeorgis等人提出了一种从粗到细的面部定位的端到端重复卷积模型,称为MDM。lv等人[22]提出了一种基于两步重初始化的深度回归结构,即TSR,它将整个人脸分为多个部分,以提高检测精度。使用姿态角(包括俯仰、偏航和滚转)作为属性,[39]构建一个网络来直接估计这三个角度,以帮助地标检测。但是[39]的级联特性使得它在随后的地标探测中处于次优状态。Jourabloo等人提出的位不变面对准(简称PIFA)。[14]通过深度级联回归器估计从3d到2d的投影矩阵,然后使用单个卷积神经网络(CNN)进行PIFA-CNN[15]的工作。[48]中的工作首先对Z缓冲区中的面深度进行建模,然后为二维图像建立三维模型。
- 最近,Kumar和Chellapa设计了一个单树突状CNN,称为pose-conditioned树突状卷积神经网络(pcd-cnn)[19],它将分类网络与第二个模块化分类网络相结合,以提高检测精度。Honari等人设计了一个网络,称为顺序多任务(seqmt)网络,具有等变标志变换(elt)损失项[12]。在[30]中,作者提出了一种基于回归树粗到细集(ert)[16]的面部标志性回归方法。为了使面部地标探测器能够抵抗图像风格的内在变化,Dong等人开发了一种风格聚合网络(SAN)[9],它将原始人脸图像与风格聚合网络一起训练地标探测器。通过将边界信息作为人脸的几何结构来考虑,吴等。为了提高检测精度,提出了一种边界哈瓦雷人脸对准算法,即实验室法。实验室从边界线提取面部标志。通过这样做,可以在很大程度上避免地标定义中的模棱两可。其他面部定位技术包括[33、42、47、10、37、36]。虽然现有的深度学习策略已经取得了很大的进展,但仍存在巨大的改进空间,特别是考虑到实际使用的探测器的精度、效率和模型紧凑性。
- 这项工作的主要目的是证明一个好的设计可以节省大量的资源,在目标任务上有最先进的性能。这项工作开发了一种实用的面部标志性探测器,称为pfld,对包括不受约束的姿势、表情、灯光和闭塞等复杂情况具有高精度。例如,一个训练集可能包含大量的正面,而缺乏那些大姿态。这将降低处理大型姿势案件的准确性。为了解决这一问题,我们主张对与稀有培训样本相对应的错误进行处罚,而不是对富人进行处罚。考虑到上述两个问题,如几何约束和数据不平衡,设计了一种新的损失。为了扩大接收视野,更好地捕捉人脸上的整体结构,增加了一个多尺度全连接(MS-FC)层,用于精确定位图像中的地标。在处理速度和模型紧凑性方面,我们使用Mobilenet块构建了我们的PFLD的主干网。在实验中,我们评估了设计的效率,并在两个广泛采用的具有挑战性的数据集(包括300W[25]和AFLW[18])上证明了其优于其他最先进的替代方案的性能。我们的型号可以调整到只有2.1MB的大小,并在手机上实现超过140帧/秒的每张脸。以上优点使我们的PFLD具有实用价值。
Methodology
- 针对上述挑战,需要采取有效措施。在本节中,我们首先关注损失函数的设计,同时考虑挑战1、2和3。然后,我们详细介绍了我们的架构。整个深网包括一个用于预测地标坐标的主干子网,专门考虑挑战4,以及一个用于估计几何信息的辅助子网。训练质量很大程度上取决于损失函数的设计,尤其是当培训数据的规模不够大时。对于地面真值界标
 与预测值
与预测值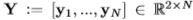 之间的误差的惩罚,最简单的损失可以说是
之间的误差的惩罚,最简单的损失可以说是 和
和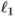 损失。然而,在不考虑几何/结构信息的情况下,同样测量地标对的差异并不明智。例如,在图像空间中给定一对
损失。然而,在不考虑几何/结构信息的情况下,同样测量地标对的差异并不明智。例如,在图像空间中给定一对 和
和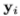 ,其偏差为
,其偏差为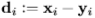 ,如果将两个投影(相对于相机的姿态)从3D真实面应用到2D图像,则真实人脸上的固有距离可以明显不同。因此,将几何信息整合到惩罚中有助于缓解这一问题。对于人脸图像,全局几何状态-三维姿态能够很好地确定投影方式。形式上,X表示二维地标的相关位置,它是三维面地标的投影,即
,如果将两个投影(相对于相机的姿态)从3D真实面应用到2D图像,则真实人脸上的固有距离可以明显不同。因此,将几何信息整合到惩罚中有助于缓解这一问题。对于人脸图像,全局几何状态-三维姿态能够很好地确定投影方式。形式上,X表示二维地标的相关位置,它是三维面地标的投影,即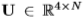 ,每列对应一个三维位置
,每列对应一个三维位置 。通过假设弱透视模型为[14],2×4投影矩阵p可以通过
。通过假设弱透视模型为[14],2×4投影矩阵p可以通过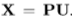 连接U和X。这个投影矩阵有六个自由度,包括偏航、滚转、俯仰、缩放和二维平移。在这项工作中,人脸应该被很好地检测、集中和规范化。局部变异的表达几乎不影响投影。也就是说,可以减少三个自由度,包括比例和二维平移,因此只需要估计三个欧拉角(偏航、滚转和俯仰)。
连接U和X。这个投影矩阵有六个自由度,包括偏航、滚转、俯仰、缩放和二维平移。在这项工作中,人脸应该被很好地检测、集中和规范化。局部变异的表达几乎不影响投影。也就是说,可以减少三个自由度,包括比例和二维平移,因此只需要估计三个欧拉角(偏航、滚转和俯仰)。 - 此外,在深度学习中,数据不平衡是另一个经常限制精确检测性能的问题。例如,一个训练集可能包含大量的正面,而缺少那些具有大姿态的正面。没有额外的技巧,几乎可以肯定的是,由这样一个训练集训练的模型不能很好地处理大的姿态情况。在这种情况下,“平等”地惩罚每个样本反而使其不平等。为了解决这一问题,我们主张对与稀有培训样本相对应的错误进行处罚,而不是对富有的样本进行处罚。
- 在数学上,损失可以用以下一般形式写:
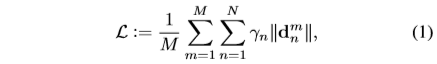
- 其中,
 指定一个度量来测量第m输入与第n个标志的距离/误差。n是预先确定的每个人脸要检测的地标数量。M表示每个过程中的训练图像数量。考虑到所用的度量(例如,本文中的“2”),权重
指定一个度量来测量第m输入与第n个标志的距离/误差。n是预先确定的每个人脸要检测的地标数量。M表示每个过程中的训练图像数量。考虑到所用的度量(例如,本文中的“2”),权重 起着关键作用。结合上述问题,如几何约束和数据不平衡,设计了一个新的损失,如下所示:
起着关键作用。结合上述问题,如几何约束和数据不平衡,设计了一个新的损失,如下所示: 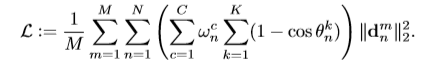
- 很容易得出式(2)中
 在式(1)中充当
在式(1)中充当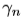 。让我们在这里仔细看看损失。其中,
。让我们在这里仔细看看损失。其中, 、
、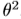 和
和 表示地面真值与估计的横摆角、纵摇角和横摇角之间的偏差角。很明显,随着偏离角的增加,惩罚也会增加。此外,我们将一个样本分类为一个或多个属性类,包括profile face、frontal face、head up、head down、expression和occlusion。加权参数
表示地面真值与估计的横摆角、纵摇角和横摇角之间的偏差角。很明显,随着偏离角的增加,惩罚也会增加。此外,我们将一个样本分类为一个或多个属性类,包括profile face、frontal face、head up、head down、expression和occlusion。加权参数 根据C类样本的分数进行调整(本工作只采用分数的倒数)。例如,如果禁用几何和数据不平衡功能,我们的损失将退化为简单的
根据C类样本的分数进行调整(本工作只采用分数的倒数)。例如,如果禁用几何和数据不平衡功能,我们的损失将退化为简单的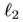 损失。无论三维姿态和/或数据不平衡是否影响训练,我们的损失都可以通过其距离测量来处理局部变化。
损失。无论三维姿态和/或数据不平衡是否影响训练,我们的损失都可以通过其距离测量来处理局部变化。 - 尽管文献中有几部作品考虑了三维姿态信息来提高性能,但我们的损失有以下优点:1)它在三维姿态估计和二维距离测量之间起着耦合作用,这比简单地增加两个关注点更为合理[14,15];2)与[19]相比,前向和后向计算直观易行;3)使网络以单级方式工作,而不是以级联方式工作[39,14],提高了优化性能。这里我们注意到变量
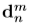 来自主干网,而
来自主干网,而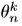 来自辅助网,由等式(2)中的损耗耦合/连接。在接下来的两个小节中,我们详细介绍了我们的网络,如图2所示:
来自辅助网,由等式(2)中的损耗耦合/连接。在接下来的两个小节中,我们详细介绍了我们的网络,如图2所示:
- 与其他基于CNN的模型类似,我们使用几个卷积层来提取特征和预测地标。考虑到人脸具有很强的整体结构,如眼、口、鼻等的对称性和空间关系,这种整体结构有助于更精确地定位地标。因此,我们将其扩展为多尺度地图,而不是单尺度特征地图。扩展是通过用步幅执行卷积操作来完成的,这样可以扩大接收范围。然后,我们通过完全连接多尺度特征图来进行最终预测。主干子网的详细配置如表1所示。从体系结构的角度来看,主干网是简单的。我们的主要目的是验证,与我们的新丢失和辅助子网(在下一小节中讨论)相关联的,即使是非常简单的体系结构也可以实现最先进的性能。
- 主干网在处理速度和模型大小方面是瓶颈,因为在测试中只涉及到这个分支。因此,使其快速紧凑至关重要。在过去的几年里,为了加快网络速度,研究了几种策略,包括Shuf flyent[44]、二值化[3]和Mobilenet[13]。由于Mobilenet技术(非纵向可分离卷积、线性瓶颈和反向残差)的良好性能,我们用Mobilenet块代替了传统的卷积操作。通过这样做,我们的主干网的计算负载显著降低,速度也因此加快。此外,我们的网络还可以根据用户的需求,通过调整Mobilenet的宽度参数来压缩,使模型变得更小、更快。这个操作是基于观察和假设,一个深卷积层的大量单个特征通道可能位于一个低维流形中。因此,在不降低(明显)精度的情况下,极有可能减少特征图的数量。我们将在实验中证明,损失80%的模型尺寸仍然可以提供有希望的检测精度。这再次证实了一个设计良好的简单/小型架构可以在面部地标检测任务中有效地执行。值得一提的是,量化技术完全兼容Shuf fluent和Mobilenet,这意味着我们的模型可以通过量化进一步缩小。

- 先前的工作[48、14、19、34]证实了适当的辅助约束有助于使地标定位稳定和稳健。我们的辅助网络起着这个作用。与以前的方法不同,例如[14]学习三维到二维投影矩阵,[19]发现零件的树枝状结构,[34]使用边界线,我们的目的是估计三维旋转信息,包括偏航、俯仰和滚动角度。有了这三个欧拉角,就可以确定头部的姿态。
- 人们可能会奇怪,给定预测和地面真实性标志,为什么不直接从它们计算欧拉角?从技术上讲,这是可行的。然而,地标预测可能太不准确,尤其是在训练开始时,这会导致对角度的低质量估计。这可能会把训练拖入两难境地,比如过度惩罚和缓慢收敛。为了将旋转信息估计与地标定位分离,引入了辅助子网。
- 值得一提的是,Detone等人[8]提出了一个深度网络来估计两幅相关图像之间的同形性。横摆角、横摇角和纵摇角可以从估计的同形矩阵中计算出来。但是对于我们的任务,我们没有每个训练样本的正面。有趣的是,我们的辅助网络可以输出目标角度,而不需要正面作为输入。原因是,我们的任务是针对人类面部的,从正面看,这些面部具有很强的规则性和结构。此外,表情和灯光等因素几乎不会影响姿势。因此,相同的平均正面可以被视为对不同的人可用。换句话说,没有额外的注释用于计算欧拉角。以下是我们计算它们的方法:1)预先确定一个标准面(在一组正面上取平均值),并在主要面平面上确定11个地标作为所有训练面的参考;2)使用每个面对应的11个标志和参考标志估计旋转矩阵。3)根据旋转矩阵计算欧拉角。为了精确起见,每个面的角度可能不精确,因为平均面用于所有面。尽管如此,它们对于我们的任务还是非常准确的,正如后来在实验中验证的那样。
- 在训练过程中,根据给定的边界框,将所有面剪切并调整为112×112进行预处理。我们通过KERA框架实现网络,使用256的批量大小,并使用Adam技术进行优化,权重衰减为10-6,动量为0.9。最大迭代次数为64K,整个培训期间学习率固定为10-4。整个网络都在Nvidia GTX 1080TI GPU上进行培训。对于300W,我们通过采集每个样本并以5_的间隔将其从−30旋转到30_来增加培训数据。此外,每个样本都有一个20%的面大小的区域被随机遮挡。而对于AFLW,我们在不增加任何数据的情况下将原始训练集输入网络。在测试中,只涉及到主干网,这是有效的。
Concluding Remarks
- 面部地标探测器的三个方面需要考虑到能够胜任大规模和/或实时任务,即准确性、效率和紧凑性。本文提出了一种实用的人脸地标探测器,称为pfld,它由主干网和辅助网两个子网组成。主干网由mobilenet块构成,可以在很大程度上释放卷积层的计算压力,并通过调整宽度参数使模型的尺寸根据用户的要求灵活。引入了一个多尺度的全连接层,扩大了接收场,从而增强了捕捉人脸结构的能力。为了进一步规范地标定位,我们定制了另一个分支,即辅助网络,通过它可以有效地估计旋转信息。考虑到几何正则化和数据不平衡问题,设计了一种新的损耗。广泛的实验结果表明,我们的设计在精度、模型尺寸和加工速度方面优于最先进的方法,因此验证了我们的PFLD 0.25x是一个很好的折衷实际使用。
- 在当前版本中,pfld仅采用旋转信息(偏航、侧倾和俯仰角)作为几何约束。预计将采用其他几何/结构信息来帮助进一步提高精度。例如,像实验室[34]一样,我们可以调整地标,使其不偏离边界线太远。从另一个角度来看,提高性能的一个可能尝试是用一些特定的任务来代替基本损失,即“2损失”。在损失中设计更复杂的加权策略也会带来好处,尤其是当培训数据不平衡和有限时。我们将上述思想作为我们今后的工作。















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









