






 本文介绍了一种高效的人脸关键点检测模型PFLD,它结合了MobileNet的轻量化和增强特征融合。文章详细讲解了模型设计、数据处理、增强和评估过程,以及如何在实际应用中配合MTCNN进行人脸区域检测。
本文介绍了一种高效的人脸关键点检测模型PFLD,它结合了MobileNet的轻量化和增强特征融合。文章详细讲解了模型设计、数据处理、增强和评估过程,以及如何在实际应用中配合MTCNN进行人脸区域检测。
PFLD全称
A Practical Facial Landmark Detector是一个精度高,速度快,模型小的人脸关键点检测模型。在移动端达到了超实时的性能(模型大小2.1Mb,在Qualcomm ARM 845 处理器上达到140fps),有较大的实用意义。
人脸关键点检测作为人脸相关应用中的一个基础任务面临了很多挑战,包括检测精度,处理速度,模型大小这些因素都要考虑到,并且在现实场景中很难获取到质量非常高的人脸,所以人脸关键点检测主要面临下面几个挑战:
局部变化:表情、局部特殊光照、部分遮挡,导致一部分关键点偏离了正常的位置,或者不可见了
全局变化:人脸姿态、成像质量
数据不均衡:在人脸数据里面,数据不均衡体现在,大部分是正脸数据,侧脸很少,所以对侧脸、大角度的人脸不太准
模型效率:在 CNN 的解决方案中,模型效率主要由 backbone 网络决定

网络结构:
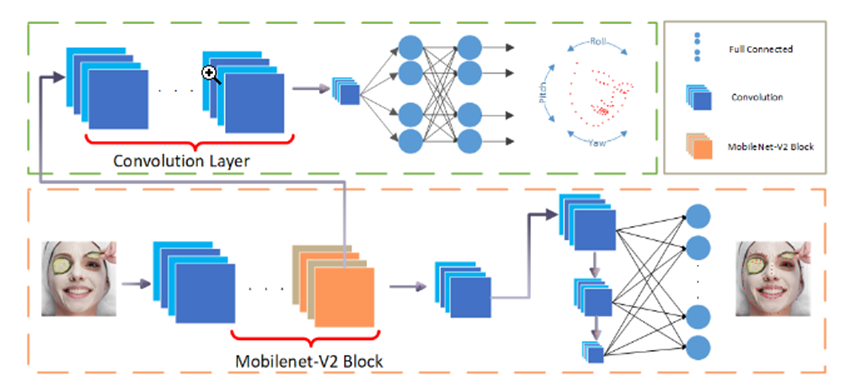
在模型设计上,PFLD的骨干网络没有采用VGG16、ResNet等网络模型,而是采用了轻量化的Backbone MobileNet。但是为了增加模型的表达能力,对MobileNet的输出特征进行了结构上的修改,融合了大中小三个尺度上的特征,并使用融合后的特征进行人脸关键点检测,从而实现对不同大小的脸都有较好的检测效果。同时,网络包含主干网络和辅助网络两部分,辅助网络主要用于在训练时预测人脸姿态,从而提高定位精度。
数据处理
开始实验之前,请确保本地已经安装了Python环境并安装了MindSpore Vision套件。
数据准备
本案例使用300W数据集作为训练集和验证集。请在官网i·bug - resources - 300 Faces In-the-Wild Challenge (300-W), ICCV 2013下载afw,helen,ibug,ifpw这四个文件。
其中每个图像上包含不止一张人脸,但是对于每张图像只标注一张人脸。由以上4个文件夹组成的训练集共计3148张图像,测试集有689张图像。
请将解压后的数据集放到./datasets/300W/300W_images/下,文件目录如下所示:

其中Mirrors68.txt就是https://github.com/mindspore-courses/applications/blob/master/pfld/data/300W_annotations.txt
当前要去掉前两行
数据预处理
原始数据集中并没有将训练集的图片和关键点进行汇总,而是存储在pts文件中,非常分散,不利于数据集加载。
因此,运行以下代码对数据中的关键点和样本路径进行收集汇总以便后续的训练和评估过程。
先进行数据处理,获得list_68pt_rect_attr_test.txt和list_68pt_rect_attr_train.txt
数据增强
在300W数据集中,尽管已经重新标注了四个数据集并统一为68个坐标点,但是对于网络而言数据量仍然不大,因此使用旋转、平移等操作将训练数据进行数据增强。
其中有个文件的命名中间存在空格,需要去掉。
数据加载
通过数据集加载接口加载数据集,并转换为Tensor以备输入模型。

加载失败

在这里要修改相关代码才行。。。
训练集可视化
原代码要加plt.show()才行。

接下来是训练:
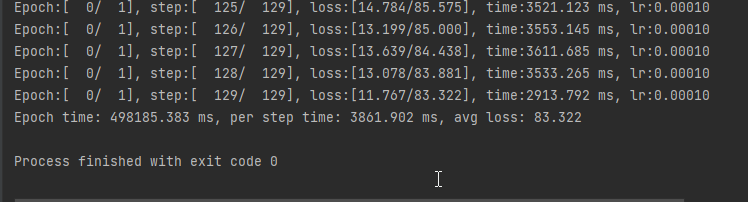
为了方便展示,案例中将epoch设置为1,经测试,在实际训练中,将epoch设置为100是一个不错的选择。
在这里就暂不训练了。
模型评估
在300W数据集的验证集上进行评估。
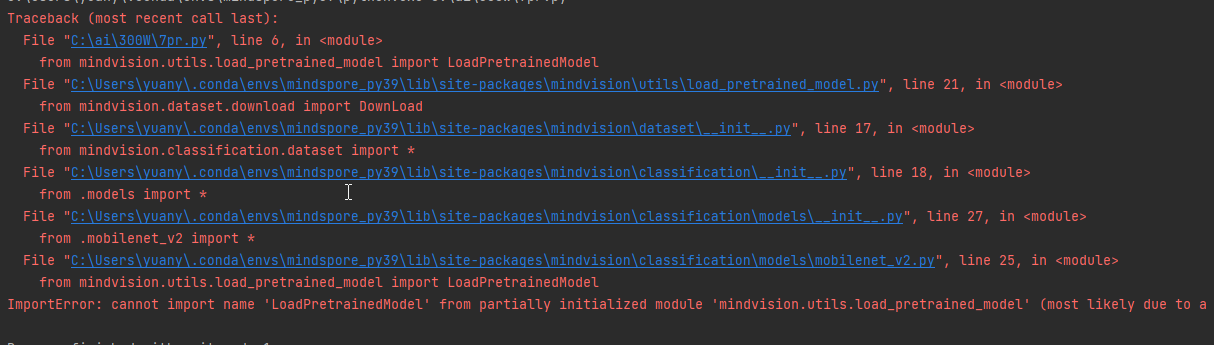
from mindvision.utils.load_pretrained_model import LoadPretrainedModel
会报循环导入错误。
采用手动下载预训练权重文件并导入到网络中进行评估。
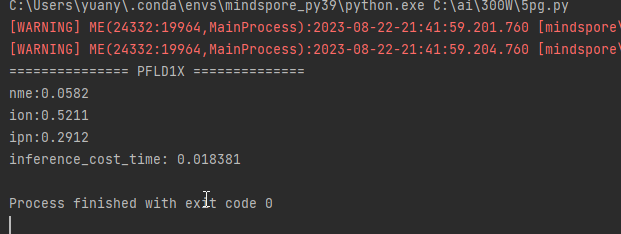
模型推理
值得注意的是:
-
PFLD是人脸关键点检测的网络,重点在关键点检测上,网络的输入需要为人脸区域图像,作者在验证模型效果之前用到了mtcnn检测人脸区域,因此,推理的图片需要直接使用人脸图像。
-
网络的输入为(1,3,112,112)的张量,本案例中的推理选择的是AFLW数据集中的一张处理后图片,若要使用其他大小的图片,请在输入网络前处理成网络可以推理的张量形式。
同样此处LoadPretrainedModel导入也会出问题,所以采用手动下载权重文件并导入到网络中进行推理。
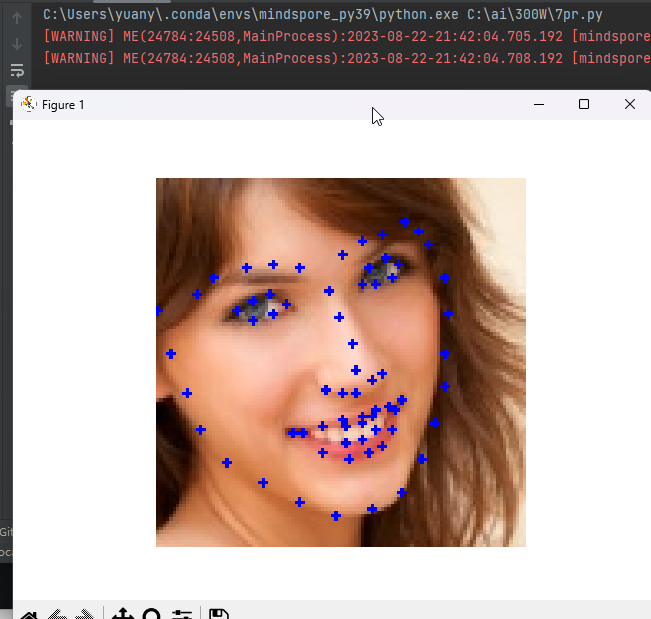
此处换成我只训练了一个epoch的权重来推理下
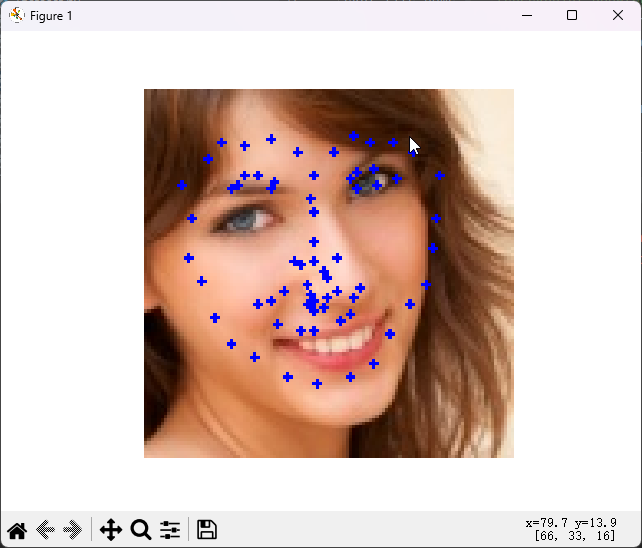
竟然还有个大概。。。不错

















 2688
2688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









