






更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验
持久化原理
持久化流程
Redis 是基于内存的数据库,数据存储在内存中,为了避免进程退出导致数据永久丢失,需要定期对内存中的数据以某种形式从内存呢保存到磁盘当中;当 Redis 重启时,利用持久化文件实现数据恢复。
Redis 的持久化主要有以下流程:
- 客户端向服务端发送写操作数据
- 数据库服务端接收到写请求的数据
- 服务端调用 write 这个系统调用,将数据往磁盘上写
- 操作系统将缓冲区中的数据转移到磁盘控制器上
- 磁盘控制器将数据写到磁盘的物理介质
上述流程中,数据的传播过程为:客户端内存 -> 服务端内存 -> 系统内存缓冲区 -> 磁盘缓冲区 -> 磁盘
在理想条件下,上述过程是一个正常的保存流程,但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分两种情况:
- Redis 数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成
- 操作系统发生故障,必须上面 5 步都完成才可以
为了应对以上 5 步操作,Redis 提供了两种不同的持久化方式:RDB(Redis DataBase) 和 AOF(Append Only File)。
RDB 原理
基础概念
RDB 是 Redis 默认开启的全量数据快照保存方案:
- 每隔一段时间,将当前进程中的数据生成快照保存到磁盘(快照持久化),生成一个文件后缀名为 rdb 的文件
- 当 Redis 重启时,可以读取快照文件进行恢复
关于 RDB 的配置均保存在 redis.conf 文件中,可以进行修改
触发机制及原理
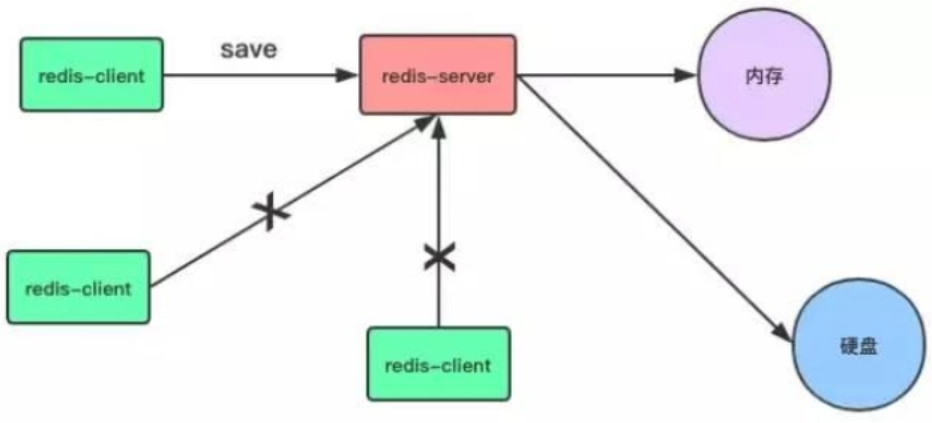
通过 SAVE 命令手动触发 RDB,这种方式会阻塞 Redis 服务器,直到 RDB 文件创建完成,线上禁止使用这种方式

通过 BGSAVE 命令,这种方式会 fork 一个子进程,由子进程负责持久化过程,因此阻塞只会发生在 fork 子进程的时候
注意:
- 子进程不直接拷贝硬盘数据,而是拷贝父进程的页表,但实际上仍然和父进程共享同一物理地址(共享数据)
- 子进程执行 bgsave 操作会生成临时的 RDB 文件,不会直接修改原有的 RDB 文件
- 为了避免脏写,这里 fork 时又引入了 copy-on-write 的技术:
- 主进程读操作访问共享内存,此时不会复制数据
- 主进程发生写操作,会复制一份物理地址的数据副本进行写入,子进程仍然读取原来的旧版数据
除了上述指令手动执行外,Redis 还可以根据 redis.conf 文件的配置自动触发:
- 设置 redis.conf 中的
save x y:表示 x 秒内,至少有 y 个 key 值变化,则触发 bgsave - 当发生主从节点复制时,从节点申请同步,主节点会触发 bgsave 操作,将生成的文件快照发送给从节点
- 执行 Debug reload 命令重新加载 redis 时,也会触发 bgsave 操作
- 默认情况下,执行了 shutdown 指令,如果没有开启 AOF 持久化,则也会触发 bgsave 操作
AOF 原理
基础概念
AOF 是 Redis 默认未开启的持久化策略:
- 以日志的形式来记录用户请求的写操作,读操作不会记录,因为写操作才会存储
- 文件以追加的形式而不是修改的形式
- redis 的 AOF 恢复其实就是把追加的文件从开始到结尾读取执行写操作
持久化原理

AOF 的持久化实现原理分为四大步骤:
- 命令追加:所有的命令都会被追加到 AOF 缓冲当中
- 文件同步:AOF 缓冲区根据对应的策略向磁盘进行同步操作
- 文件重写:随着同步的进行,AOF 文件追加的命令会越来越多,导致文件臃肿,会触发重写以便减小文件体积
- 重启恢复:当 Redis 重启时,会重新加载 AOF 执行命令恢复数据
注意:
- AOF 默认是关闭的,修改 redis.conf 文件的
appendonly yes即可开启 - 频率配置:
always同步刷盘:数据可靠,但性能影响大everysec每秒刷盘:性能适中,最多丢失一秒数据no系统控制刷盘:性能最好,可靠性差,容易丢失大量数据
- 设置重写:
- 用
bgrewriteaof重写 AOF 文件,用最少命令达到相同效果 - 可设置文件大小到大一定阈值自动触发
- 用
AOF 数据恢复过程
已知 Redis 通过重新执行一遍 AOF 文件里面的命令进行还原状态,但实际上 Redis 并不是直接执行的:
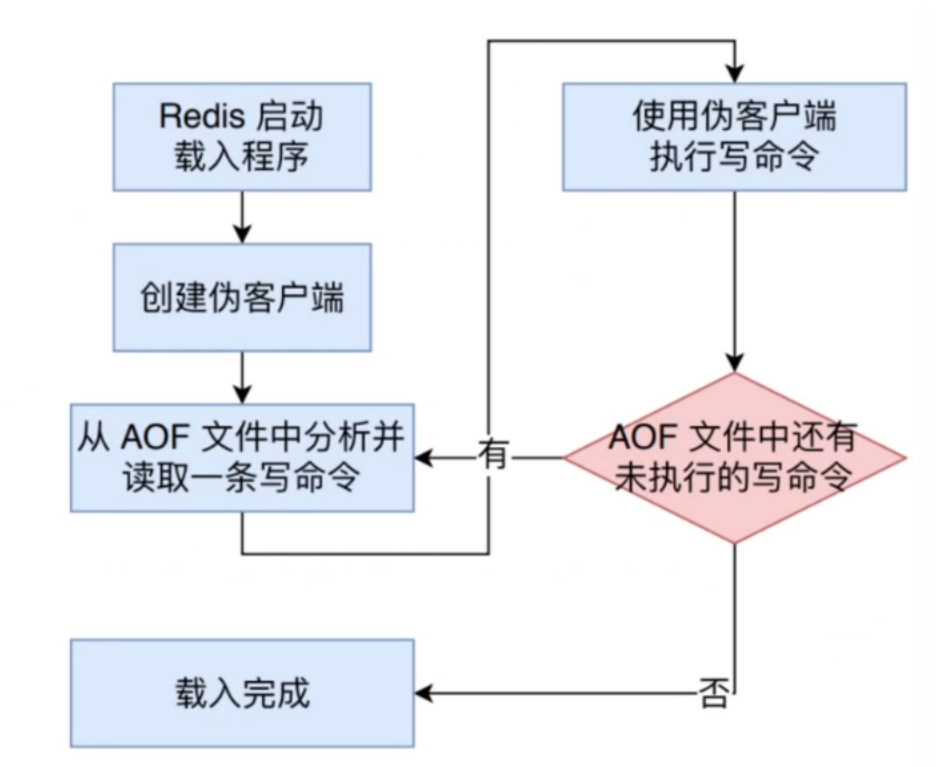
具体步骤如下:
- 首先创建一个不带有网络链接的伪客户端,此过程只需要载入 AOF 文件即可,因此无需网络连接
- 之后读取一条 AOF 文件中的命令并使用伪客户端执行
- 重复上述过程,直到 AOF 文件所有的命令执行完毕
AOF 文件重写过程
为了解决 AOF 文件持续追加命令导致 AOF 文件过度膨胀的问题,Redis 提供了 AOF 文件重写功能

例如上述命令在执行重写前,会记录 list 这个 key 的状态,重写前 AOF 要保存这五条命令,重写后只需要一条命令,结果确是等价的。
注意:
- AOF 重写的过程并不是针对现有的 AOF 文件读取、分析或写入操作,而是读取服务器当前数据库的状态来实现
- 例如,首先从数据库中读取当前键的值,然后用一条命令记录键值对,以此代替记录这个键值对的多条命令
触发机制:
- 手动:使用命令
bgrewriteaof,如果当前有正在运行的 rewrite 子进程,则本次的重写会延迟执行,否者直接触发 - 自动触发:根据配置规则
auto-aof-rewrite-min-size 64mb,若 AOF 文件超过配置大小则会自动触发
AOF 重写原理
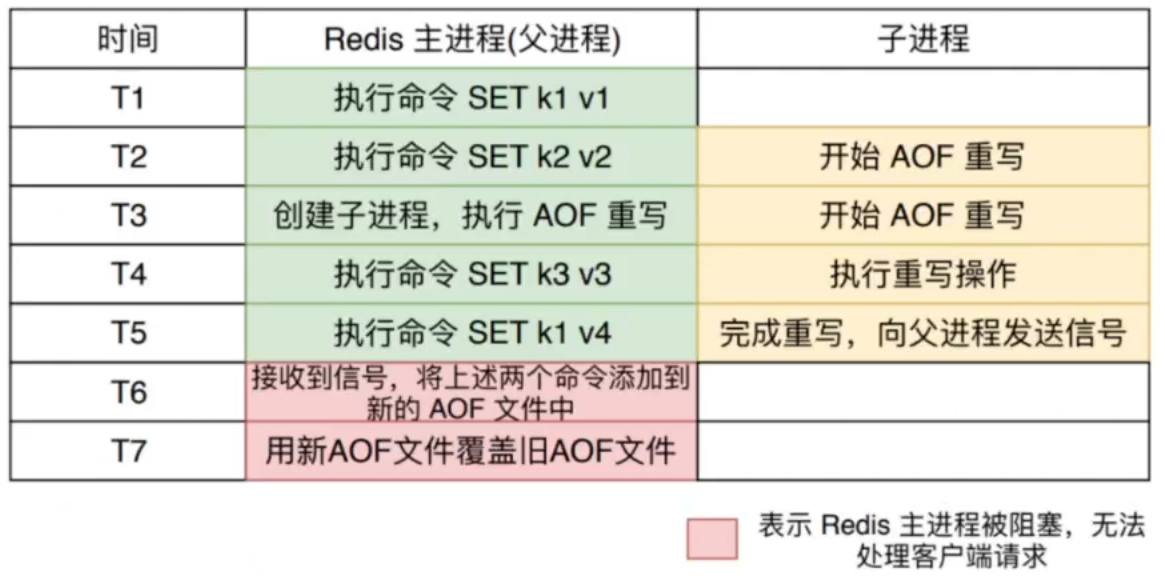
AOF 重写函数会进行大量的写入操作,调用该函数的线程将被长时间阻塞,所以 Redis 在子进程中执行 AOF 重写操作:

在整个 AOF 重写的过程中,只有信号处理函数的执行过程会对 Redis 主进程造成阻塞,在其他时候都不会阻塞主进程
持久化优先级
首先对比一下两种持久化方式的优缺点:
- 文件大小:RDB 文件默认使用 LZF 算法进行压缩,压缩后的文件体积远远小于内存大小,适用于备份、全量复制等
- 恢复速度:Redis 加载 RDB 文件恢复数据要远远快于AOF 方式,AOF 则需要执行全部的命令
- 内存占用:两种方式都需要 fork 出子进程,子进程属于重量级操作,频繁执行的成本较高
- 备份容灾:RDB 文件为二进制文件,没有可读性,AOF 文件在了解其结构的情况下可以手动修改或者补全
- 数据一致性:RDB 方式的实时性不够,无法做到秒级的持久化,存在丢失数据的风险,AOF 可以做到最多丢失一秒的数据
在服务器同时开启了 RDB 和 AOF 的情况下,会优先选择 AOF 方式,若不存在 AOF 文件,则会执行 RDB 恢复。
RDB 混合 AOF 解决方案
针对上述 RDB 和 AOF 的持久化原理可知,两者都需要 fork 出子进程,可能会造成主进程的阻塞,因此需要:
- 降低 fork 的频率,手动触发 RDB 快照或 AOF 重写
- 控制 Redis 内存限制,防止 fork 耗时过长
- 配置 Linux 的内存分配策略,避免因为物理内存不足导致 fork 失败
除此之外,在线上环境中,如果不是特别敏感的数据或可以通过重新生成的方式恢复数据,则可以关闭持久化
对于其他场景,Redis 在 4.0 引入了 RDB 混合 AOF 的解决方案——混合使用 AOF 日志和内存快照:
- 在 redis.conf 里面开启配置:
aof-use-rdb-preamble yes
当开启混合持久化时,在 AOF 重写日志时,fork 出来的子进程会先将与主线程共享的内存数据以 RDB 的方式写入 AOF,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区的增量命令会以 AOF 的方式写入 AOF 文件,写入完成后,通知主进程将新的含有RDB 格式和 AOF 格式的 AOF 文件替换旧的 AOF 文件。
注意:对于采用混合持久化方案的 AOF 文件,AOF 文件的前半部分是 RDB 格式的全量数据,后半部分则是 AOF 格式的增量数据。
这样的好处在于,由于前半段为 RDB 格式的文件,恢复速度较快,加载完 RDB 的内容后再执行后半部分 AOF 的内容,以减少的丢失数据的风险。
安全策略
密码认证
可以通过 Redis 的配置文件设置密码参数,当客户端连接到 Redis 服务器时,需要密码验证:
- 打开 redis.conf,找到
requirepass进行配置 - 密码要求:长度 8 位以上,包含四类中的三类字符(字母大小写,数字,符号)
配置完毕后,重启生效。
也可以通过命令的方式修改:
CONFIG SET requirepass password- 登陆时需要:
AUTH password
注意:
-
这里修改的密码为 default 用户密码
-
在 initServer 中会调用 ACLUpdateDefaultUserPassword(server.requirepass) 函数设置 default 用户的密码
-
/* Set the password for the "default" ACL user. This implements supports for * requirepass config, so passing in NULL will set the user to be nopass. */ void ACLUpdateDefaultUserPassword(sds password) { ACLSetUser(DefaultUser,"resetpass",-1); if (password) { sds aclop = sdscatlen(sdsnew(">"), password, sdslen(password)); ACLSetUser(DefaultUser,aclop,sdslen(aclop)); sdsfree(aclop); } else { ACLSetUser(DefaultUser,"nopass",-1); } }
密码不生效解决方案
查看 redis.conf 配置:
# IMPORTANT NOTE: starting with Redis 6 "requirepass" is just a compatibility
# layer on top of the new ACL system. The option effect will be just setting
# the password for the default user. Clients will still authenticate using
# AUTH <password> as usually, or more explicitly with AUTH default <password>
# if they follow the new protocol: both will work.
#
# The requirepass is not compatible with aclfile option and the ACL LOAD
# command, these will cause requirepass to be ignored.
#
# requirepass foobared
自 Redis 6.0 起,requirepass 只是针对 default 用户的配置,由于 redis 加载配置后会读取 aclfile,重新新建全局 Users 对象,此举会调用 ACLInitDefaultUser 函数重新新建 nopass 的 default 用户,因此导致配置的 requirepass 失效
根据上述分析,解决方案很明显:
- 更改启动 redis 的方式,不读取 aclfile:
redis-server ./redis.conf - 或者在启用 aclfile 的情况下,redis-cli 登录后,用
config set requirepass xxx,然后acl save(会写 default 的 user 规则到 aclfile 中)
过期策略
基础操作
Redis 的 key 存在过期时间,设置命令如下:
expire <key> <n>:设置 key 在 n 秒后过期pexpire <key> <n>:设置 key 在 n 毫秒后过期expireat <key> <n>:设置 key 在某个时间戳(精确到秒)后过期pexpireat <key> <n>:设置 key 在某个时间戳(精确到毫秒)后过期
也可以在 key 创建时直接设置:
set <key> <value> ex <n>:设置键值对的时候,同时指定过期时间(精确到秒)set <key> <value> px <n>:设置键值对的时候,同时指定过期时间(精确到毫秒)setex <key> <n> <va1ue>:设置键值对的时候,同时指定过期时间(精确到秒),该操作是一个原子操作
其他相关操作:
persist <key>:将 key 的过期时间删除TTL <key>:返回 key 的剩余生存时间(精确到秒)PTTL <key>:返回 key 的剩余生存时间(精确到毫秒)
Redis 过期删除策略
要想删除一个过期的 key,首先需要判断它是否过期:
- 在 Redis 内部,当我们给某个 key 设置过期时间时,Redis 会给该 key 带上过期时间存入一个过期字典(redisdb)中
- 每次查询一个 key 时,Redis 会先从过期字典查询该键是否存在:
- 不存在则正常返回
- 存在则取该 key 的时间和当前系统时间对比判定是否过期
- 对于过期的 key 会根据过期删除策略进行处理
Redis 提供了三种过期策略:
- 惰性删除:只有当客户端尝试获取一个 key 时,Redis才会检查该 key 是否过期,如果过期则删除
- 定时删除:在设定key的过期时间的同时,创建一个定时器,当达到过期时间时,定时器立即删除该 key
- 定期删除:每隔一段时间随机取出一定数量的 key 进行检查,并删除过期的 key
而 Redis 的过期删除策略是:惰性删除 + 定期删除
惰性删除原理
查看 Redis 源码 db.c,其中执行惰性删除的逻辑会反复调用 expireIfNeeded 函数对 key 其进行检查:
/* Return values for expireIfNeeded */
typedef enum {
KEY_VALID = 0, /* Could be volatile and not yet expired, non-volatile, or even non-existing key. */
KEY_EXPIRED, /* Logically expired but not yet deleted. */
KEY_DELETED /* The key was deleted now. */
} keyStatus;
keyStatus expireIfNeeded(redisDb *db, robj *key, int flags) {
if (server.lazy_expire_disabled) return KEY_VALID; // 未设置过期策略直接返回 key 值
if (!keyIsExpired(db,key)) return KEY_VALID;
/* If we are running in the context of a replica, instead of
* evicting the expired key from the database, we return ASAP:
* the replica key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys. The
* exception is when write operations are performed on writable
* replicas.
*
* Still we try to return the right information to the caller,
* that is, KEY_VALID if we think the key should still be valid,
* KEY_EXPIRED if we think the key is expired but don't want to delete it at this time.
*
* When replicating commands from the master, keys are never considered
* expired. */
// 这里说明了,从节点的 key 过期策略是由主节点控制的,如果是在复制主节点的命令时,键永远不会被视为已过期
if (server.masterhost != NULL) {
if (server.current_client && (server.current_client->flags & CLIENT_MASTER)) return KEY_VALID;
if (!(flags & EXPIRE_FORCE_DELETE_EXPIRED)) return KEY_EXPIRED;
}
/* In some cases we're explicitly instructed to return an indication of a
* missing key without actually deleting it, even on masters. */
if (flags & EXPIRE_AVOID_DELETE_EXPIRED)
return KEY_EXPIRED;
/* If 'expire' action is paused, for whatever reason, then don't expire any key.
* Typically, at the end of the pause we will properly expire the key OR we
* will have failed over and the new primary will send us the expire. */
if (isPausedActionsWithUpdate(PAUSE_ACTION_EXPIRE)) return KEY_EXPIRED;
/* The key needs to be converted from static to heap before deleted */
int static_key = key->refcount == OBJ_STATIC_REFCOUNT;
if (static_key) {
key = createStringObject(key->ptr, sdslen(key->ptr));
}
/* Delete the key */
deleteExpiredKeyAndPropagate(db,key);
if (static_key) {
decrRefCount(key);
}
return KEY_DELETED;
}
定期删除原理
查看 Redis 源码 expire.c,其中执行定期删除的逻辑在 void activeExpireCycle(int type) 中:
void activeExpireCycle(int type) {
/* Adjust the running parameters according to the configured expire
* effort. The default effort is 1, and the maximum configurable effort
* is 10. */
unsigned long
effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
// 每次循环取出过期键的数量
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
// FAST 模式下的执行周期
config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
// SLOW 模式的执行周期
config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
2*effort,
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
effort;
...........
定期删除的周期配置在 redis.conf 中,其中 hz 10 默认值每秒进行 10 次过期检查
Redis 内存淘汰策略
当 Redis 运行内存超过设置的最大内存时,会执行淘汰策略删除符合条件的 key 保障高效运行
最大内存设置:redis.conf 中 maxmemory <bytes>,若不设置默认无限制(但最大为物理内存的四分之三)
Redis 支持八种淘汰策略:
- noeviction:不删除任何数据,内存不足直接报错 (默认策略)
- volatile-lru:挑选最近最久使用的数据淘汰
- volatile-lfu:挑选最近最少使用数据淘汰
- volatile-ttl:挑选将要过期的数据淘汰
- volatile-random:任意选择数据淘汰
- allkeys-lru:挑选最近最少使用的数据淘汰
- allkeys-lfu:挑选最近使用次数最少的数据淘汰
- allkeys-random:任意选择数据淘汰,相当于随机
LRU 算法原理
LRU 全称为 Least Recently Used,最近最少使用,会选择淘汰最近最少使用的数据
传统LRU算法实现:
- 基于链表的结构,链表中的元素按照操作顺序从前向后排列,最新操作的键会被移动到表头
- 当需要执行淘汰策略时,删除链表尾部的元素即可
但是 Redis 的 LRU 算法并不是传统的算法实现,在海量数据下,基于链表的操作会带来额外的内存开销,降低缓存性能
因此,Redis 采用了一种近似 LRU 算法
首先来看一下 Redis 源码中 server.h 中对 redisObject 的定义:
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
};
其中 lru 的值在创建对象时会被初始化,在 object.c 中:
// typedef struct redisObject robj;
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
o->lru = 0;
return o;
}
void initObjectLRUOrLFU(robj *o) {
if (o->refcount == OBJ_SHARED_REFCOUNT)
return;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes() << 8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return;
}
Redis 在每一个对象的结构体中添加了 lru 字段,用于记录此数据最后一次访问的时间戳,这里是基于全局 LRU 时钟计算的
如果一个 key 被访问了,则会调用 db.c 中的 lookupKey 函数对 lru 字段进行更新:
robj *lookupKey(redisDb *db, robj *key, int flags) {
// 通过 dbFind 函数查找给定的键(key)如果找到,则获取键对应的值
dictEntry *de = dbFind(db, key->ptr);
robj *val = NULL;
if (de) {
val = dictGetVal(de);
/* Forcing deletion of expired keys on a replica makes the replica
* inconsistent with the master. We forbid it on readonly replicas, but
* we have to allow it on writable replicas to make write commands
* behave consistently.
*
* It's possible that the WRITE flag is set even during a readonly
* command, since the command may trigger events that cause modules to
* perform additional writes. */
// 处理键过期的情况
int is_ro_replica = server.masterhost && server.repl_slave_ro;
int expire_flags = 0;
if (flags & LOOKUP_WRITE && !is_ro_replica)
expire_flags |= EXPIRE_FORCE_DELETE_EXPIRED;
if (flags & LOOKUP_NOEXPIRE)
expire_flags |= EXPIRE_AVOID_DELETE_EXPIRED;
if (expireIfNeeded(db, key, expire_flags) != KEY_VALID) {
/* The key is no longer valid. */
val = NULL;
}
}
if (val) {
/* Update the access time for the ageing algorithm.
* Don't do it if we have a saving child, as this will trigger
* a copy on write madness. */
// 更新访问时间
if (server.current_client && server.current_client->flags & CLIENT_NO_TOUCH &&
server.current_client->cmd->proc != touchCommand)
flags |= LOOKUP_NOTOUCH;
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val); // 策略为 LFU,更新使用频率
} else {
val->lru = LRU_CLOCK(); // 策略为 LRU,更新时间戳
}
}
if (!(flags & (LOOKUP_NOSTATS | LOOKUP_WRITE)))
server.stat_keyspace_hits++;
/* TODO: Use separate hits stats for WRITE */
} else {
if (!(flags & (LOOKUP_NONOTIFY | LOOKUP_WRITE)))
notifyKeyspaceEvent(NOTIFY_KEY_MISS, "keymiss", key, db->id);
if (!(flags & (LOOKUP_NOSTATS | LOOKUP_WRITE)))
server.stat_keyspace_misses++;
/* TODO: Use separate misses stats and notify event for WRITE */
}
return val;
}
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,查看源码 evict.c:
struct evictionPoolEntry {
unsigned long long idle; /* Object idle time (inverse frequency for LFU) */
sds key; /* Key name. */
sds cached; /* Cached SDS object for key name. */
int dbid; /* Key DB number. */
int slot; /* Slot. */
};
这里定义了一个淘汰池,所有待淘汰的 key 会通过 evictionPoolPopulate 函数填入:
int evictionPoolPopulate(redisDb *db, kvstore *samplekvs, struct evictionPoolEntry *pool) {
int j, k, count;
dictEntry *samples[server.maxmemory_samples];
int slot = kvstoreGetFairRandomDictIndex(samplekvs);
// 从字典中获取一些键,结果存放到 samples 中,并且返回获取的键的数量。所选取的键的数量不能超过 server.maxmemory_samples
count = kvstoreDictGetSomeKeys(samplekvs,slot,samples,server.maxmemory_samples);
// 循环采样,对抽样得到的键进行处理
for (j = 0; j < count; j++) {
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
de = samples[j];
key = dictGetKey(de);
/* If the dictionary we are sampling from is not the main
* dictionary (but the expires one) we need to lookup the key
* again in the key dictionary to obtain the value object. */
if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) {
if (samplekvs != db->keys)
de = kvstoreDictFind(db->keys, slot, key);
o = dictGetVal(de);
}
............
LFU 算法原理
LFU 全称 Least Frequently Used,最近最不常用,LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去
被访问多次,那么将来被访问的频率也更高”
传统 LFU 算法实现:
- 基于链表的结构,链表中的元素按照访问的次数从大到小排序,新插入的元素在尾部,访问后次数加一
- 当需要执行淘汰策略时,对链表进行排序,相同次数按照时间排序,删除访问次数最少的尾部元素
Redis 实现的 LFU 算法也是一种近似 LFU 算法
首先,仍然从 Redis 源码中 server.h 中对 redisObject 的定义入手:
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
};
之前在 LRU 算法原理时我仅仅提到 lru 字段作为 LRU 算法的时间戳来使用,但如果选择 LFU 算法,该字段将被拆分为两部分:
- 低 8 位:计数器,被设置为宏定义 LFU_INIT_VAL = 5
- 高 16 位:以分钟为精度的 Unix 时间戳
之后仍然是 db.c 中的 lookupKey 函数,这次具体来看 LRU 的更新策略:
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val); // 策略为 LFU,更新使用频率
} else {
val->lru = LRU_CLOCK(); // 策略为 LRU,更新时间戳
}
}
更新策略为调用了 updateLFU:
void updateLFU(robj *val) {
// 根据距离上次访问的时长,衰减访问次数
unsigned long counter = LFUDecrAndReturn(val);
// 根据当前访问更新访问次数
counter = LFULogIncr(counter);
// 更新 lru 变量值
val->lru = (LFUGetTimeInMinutes()<<8) | counter;
}
Redis 执行 LFU 淘汰策略和 LRU 基本类似,也是将所有待淘汰的 key 通过 evictionPoolPopulate 函数填入,区别在于填充策略的选择:
/* Calculate the idle time according to the policy. This is called
* idle just because the code initially handled LRU, but is in fact
* just a score where a higher score means better candidate. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
idle = estimateObjectIdleTime(o);
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
/* When we use an LRU policy, we sort the keys by idle time
* so that we expire keys starting from greater idle time.
* However when the policy is an LFU one, we have a frequency
* estimation, and we want to evict keys with lower frequency
* first. So inside the pool we put objects using the inverted
* frequency subtracting the actual frequency to the maximum
* frequency of 255. */
idle = 255-LFUDecrAndReturn(o);
} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
/* In this case the sooner the expire the better. */
idle = ULLONG_MAX - (long)dictGetVal(de);
} else {
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
}
Redis 高可用
主从复制解决方案
将一台 Redis 服务器的数据,复制到其他的 Redis 服务器,前者称为主节点(master),其他服务器称为从节点(slave)。
注意:主从复制的数据流动是单向的,只能从主节点流向从节点
Redis 的主从复制是异步复制,异步分为两个方面:
- 一个是 master 服务器在将数据同步到 slave 时是异步的,因此 master 服务器在这里仍然可以接收其他请求,
- 一个是 slave 在接收同步数据也是异步的

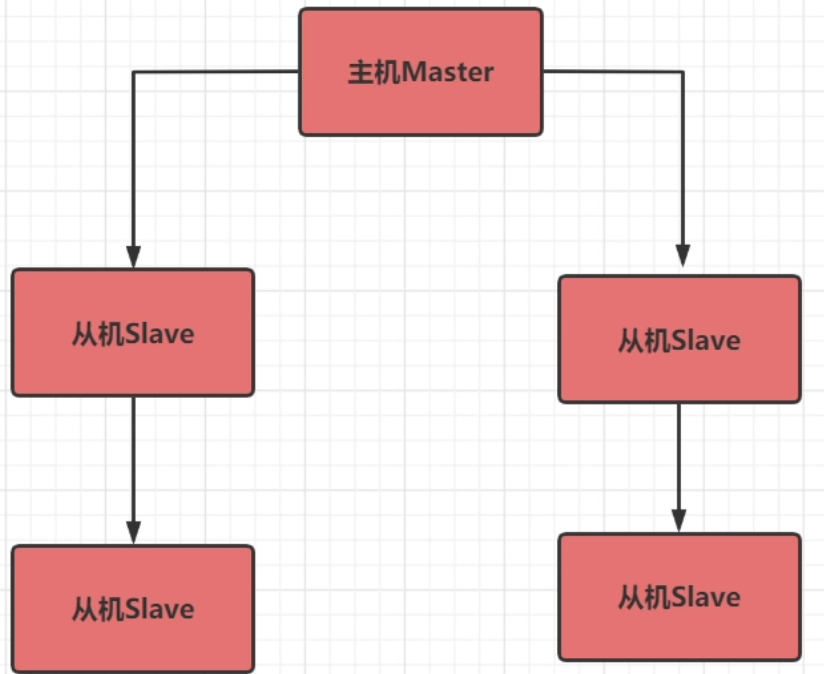
一主多从:
- 一个主节点:负责数据修改操作
- 多个从节点:负责读数据,一般多为一主一从的配置
如果从节点需求大,由于主从同步时,主节点需要发送自己的 RDB 文件给从节点进行同步,若此时从节点数量过多,主节点需要频繁地进行 RDB 操作,会影响主节点的性能。
因此,考虑从节点再做为主节点配置从节点:
全量同步原理
全量同步发生在主节点和从节点的第一次同步
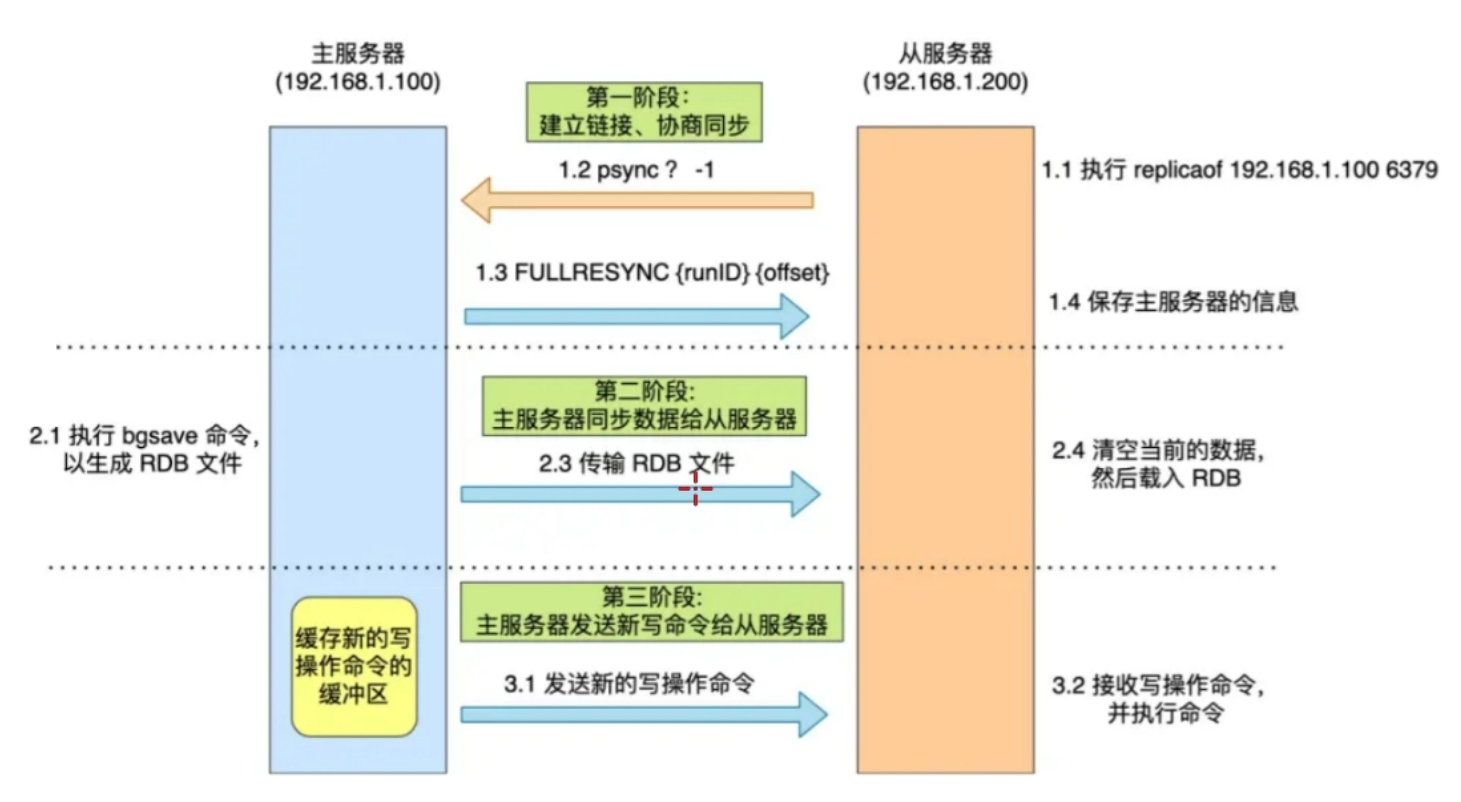
- 从节点向主节点发起同步请求
- 主节点先返回 replid 给从节点更新
- 然后主节点执行 bgsave 生成 RDB 文件发送给从节点
- 从节点删除本地数据,接收 RDB 文件并加载
- 同步过程中若主节点收到新的命令也会写入从节点的缓冲区中
- 从节点将缓冲区的命令写入本地,记录最新数据到 offset
增量同步原理
因为各种原因 master 服务器与 slave 服务器断开后,slave 服务器在重新连上 master 服务器时会尝试重新获取断开后未同步的数据
即部分同步,或者称为部分复制。
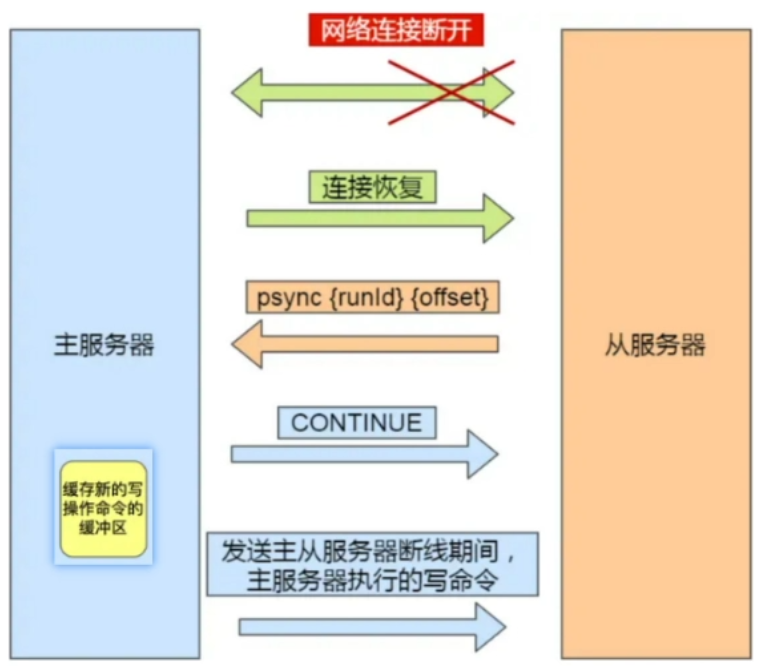
- master 服务器会记录一个 replicationId 的伪随机字符串,用于标识当前的数据集版本,还会记录一个当数据集的偏移量 offset
- 主节点不断滴把自己接收到的命令记录在 repl_backlog 中,并修改 offset
- 执行增量同步时,主节点在 repl_backlog 获取 offset 后的数据并返回给从节点
- 从节点接收数据后写入本地,修改 offset 与主节点一致
注意:
- epl_backlog 大小有上限,超过后新数据会覆盖老数据
- 如果从节点断开时间太久导致未备份的数据被覆盖则无法基于 log 做增量同步
Sentinel 哨兵解决方案
对于主从同步解决方案,如果主节点因为某种原因宕掉,从节点也无法承担主节点的任务,导致整个系统无法正常执行业务
因此引入 Sentinel,若主节点宕掉,则 Sentinel 会从节点之间会选举出一个节点作为主节点

服务监控原理
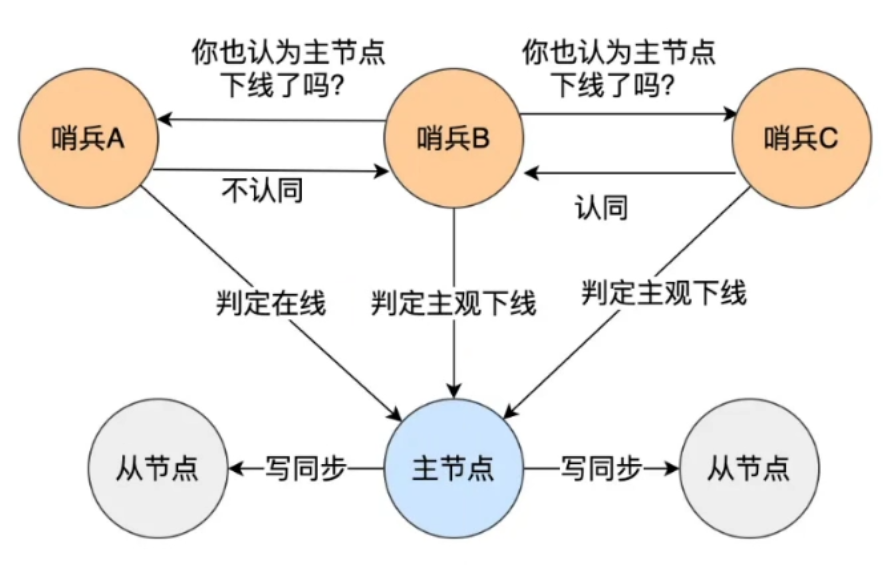
- Sentinel 基于心跳机制监控服务状态,每 1 s 向集群的每个实例发送一次 ping
- 主观下线:某个 Sentinel 节点发现某个实例未响应,认为该实例主观下线
- 客观下线:超过一定数量的 Sentinel 节点都认为该实例主观下线,则该实例客观下线
选举规则
- 首先判断与主节点断开时间最短的从节点
- 然后判断从节点的 slave-priority 值,值越小优先级越高
- slave-priority 值相同判断 offset 值,值越大优先级越高
- 最后是从节点运行 id,id越小优先级越高
脑裂问题
假设 Sentinel 和 集群的各个实例处于不同的网络分区,由于网络抖动,Sentinel 没有心跳感知到主节点,因此选举提升了一个从节点作为新的主节点:
- 客户端由于还在老的主节点写数据
- 但网络恢复后,老的主节点会被强制降为从节点导致原有数据丢失
解决方案:
- 设置 redis 参数
- min-replicas-to-write 1 表示最少的 salve 节点为 1 个
- min-replicas-max-lag 5 表示数据复制和同步的延迟不能超过 5 秒
- 如果发生脑裂,原master会在客户端写入操作的时候拒绝请求,避免数据大量丢失
















 4455
4455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











