







- Binary-class Classification
- 逻辑斯蒂回归
- Multi-class Classification
五、Classification:Probabilistic Generative Model
在分类中找一个function,它的input是一个object x,它的output是这个object属于哪一个class。

task:在金融上,通过某个人的信息决定要不要借钱给他;医疗诊断;手写字辨识;人脸辨识;
以下以宝可梦为例,输入一个宝可梦输出它是哪一类:

1.将宝可梦数值化放到function中,即特性数值化:
Total(多强)、HP(生命值)、Attack(攻击)、Defense(防御)、SP Atk(特殊攻击时的攻击力)、SP Def(特殊攻击时的攻防御值)、Speed(速度);
那么一只宝可梦就是一个7个数字组成的vector(向量);
2.Training data for Classification
a.建立一个function f ( x ) f(x) f(x),内嵌一个函数 g ( x ) g(x) g(x), g ( x ) g(x) g(x)>0输出为分类1; g ( x ) g(x) g(x)<0输出为分类2;
b.定义Loss Function为输出数值为错误的次数;
c.找到最好的function(方法有SVM等)

find best function solution(非SVM):
两个分类中,x属于分类1的概率(其中 P ( C 1 ) P(C_{1}) P(C1)为从calss1抽出x的几率、 P ( C 2 ) P(C_{2}) P(C2)为从calss2抽出x的几率、 P ( x ∣ C 1 ) P(x\mid C_{1}) P(x∣C1)从class1中能抽到指定x的几率、 P ( x ∣ C 2 ) P(x\mid C_{2}) P(x∣C2)从class2中能抽到指定x的几率):

以上想法叫Generative Model(生成模型,可以算某一个x出现的几率 P ( x ) = P ( x ∣ C 1 ) P ( C 1 ) + P ( x ∣ C 2 ) P ( C 2 ) P(x) = P(x \mid C_{1})P(C_{1}) + P(x \mid C_{2})P(C_{2}) P(x)=P(x∣C1)P(C1)+P(x∣C2)P(C2) ,就可以自己产生x)。
从training data中估测出以上4个几率值:
假设Class1为水系的神奇宝贝,Class2为一般系;400个data中,水系和一般系的当做training data 。剩下的当做testing data;
Training data:79 Water ,61 Normal;
Prior:从Class1里sample出一只宝可梦的概率:
P ( C 1 ) P({C_{1}}) P(C1) = 79 / ( 79 + 61 ) =0.56;
从Class2里sample出一只宝可梦的概率:
P ( C 2 ) P({C_{2}}) P(C2) = 61 / ( 79 + 61 ) =0.44;
79只水系宝贝的分布(一个点代表一只):
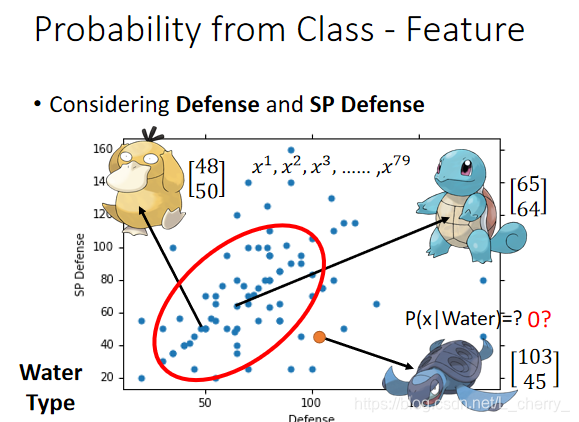
如何计算不在这79个中的海归的 P ( x ∣ W a t e r ) P(x \mid Water) P(x∣Water)?
假设这79个点都是从一个Gaussian distribution(高斯分布)中sample出来的,如何通过79个点找到这个高斯分布?
Gaussian Distribution
mean: μ \mu μ(是一个vector)、covariance(协方差): Σ \Sigma Σ(是一个matrix);
同样的x,把不同的 μ \mu μ和 Σ \Sigma Σ代入function,就会有不同的形状;
同样的 Σ \Sigma Σ、不同的 μ \mu μ,代表它们几率分布最高点的地方是不一样的;
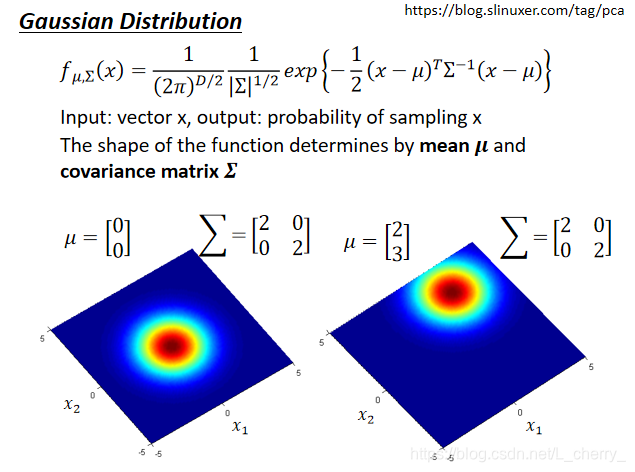
同样的 μ \mu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4333
4333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









