







 本文介绍了强化学习中的动态规划方法,包括策略评估、策略迭代、值迭代和广义策略迭代。通过实例解释了策略评估的工作过程,并展示了如何通过策略迭代和值迭代找到最优策略。动态规划的思想对于理解和解决马尔科夫决策过程至关重要,尽管它依赖于完全已知的环境模型。
本文介绍了强化学习中的动态规划方法,包括策略评估、策略迭代、值迭代和广义策略迭代。通过实例解释了策略评估的工作过程,并展示了如何通过策略迭代和值迭代找到最优策略。动态规划的思想对于理解和解决马尔科夫决策过程至关重要,尽管它依赖于完全已知的环境模型。
一、前言
在强化学习系列(三):马尔科夫决策过程中,我们提到了什么是马尔科夫过程,并且表示大部分强化学习问题都可以看做满足马尔科夫决策过程,但我们没有说如何求解马尔科夫决策过程。在本章中,我们将介绍如何用动态规划(Dynamic Programming, DP)的方法求解马尔科夫决策过程,此处,我们假设需要求解的MDP是环境完全已知的。(注意:这不同于强化学习问题,大部分强化学习问题都是环境部分未知或全部未知的,但动态规划的思想对我们理解强化学习方法很有帮助,所以需要有一定了解。)
本章主要介绍两类问题,一类是预测问题(prediction problem),即给定一个策略 π π ,求出该策略的 value function,在DP中也被叫做策略估计(policy evaluation)。另一类是控制问题(control problem),即求解最优策略。
二、policy evaluation(策略估计)
问题:当给定一个策略 π π ,要求解该策略的state-value function vπ v π
方法:迭代 Bellman expectation backup
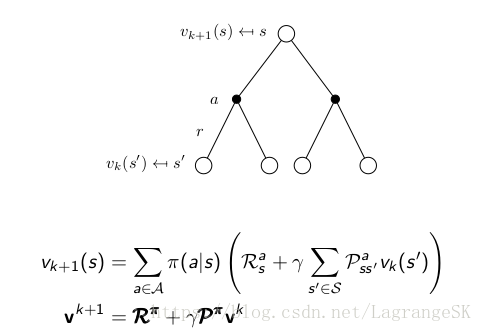
假设有一系列的state-value function v0,v1,v2,... v 0 , v 1 , v 2 , . . . , 其中, v0 v 0 为初始值函数,取随机值,那么随后的 v2,.... v 2 , . . . . 可以通过上式迭代获得。以此类推,当 k→∞ k → ∞ 时,可以求出 vπ v π 。通常在计算过程中,假设给定策略的value function是稳定的,所以不需要进行无限步迭代计算,可以通过给定一个 |vk+1(s)−v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1771
1771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









