







完整代码已上传至Github
框架代码怎么跑
- 我用的linux,最开始报错,解决方案如下
- 把文件夹
predictor删掉,这应该是在Windows下跑才需要的(否则就会和文件重名导致报错) - 运行如下命令解决报找不到
-lz的错sudo apt-get updatesudo apt-get install zlib1g-dev
- 把文件夹
- 然后按readme中的说法就可以正常跑了,见下图
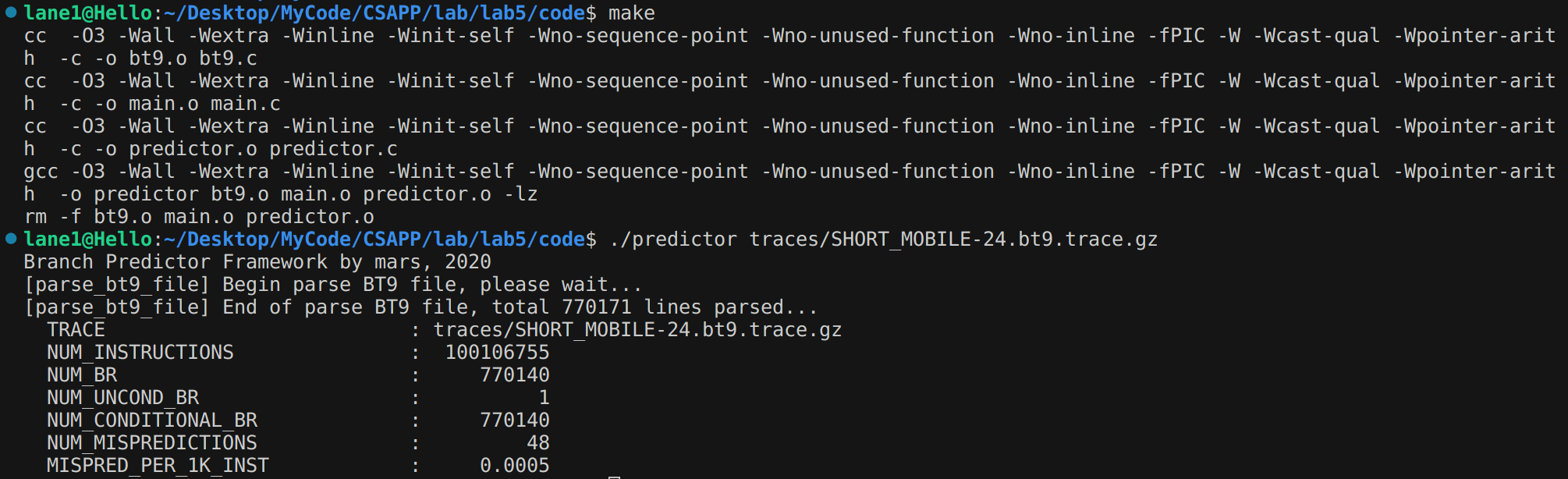
记录一下初始效果
- 参考代码中,已经实现了一个经典的Gshare分支预测器,记录一下效果,方便后面对照
| Gshare | NUM_MISPREDICTIONS | MISPRED_PER_1K_INST |
|---|---|---|
| LONG1 | 370661 | 0.5772 |
| LONG2 | 1762528 | 1.3861 |
| LONG3 | 9997824 | 7.7871 |
| LONG4 | 5170 | 0.0052 |
| SHORT1 | 434642 | 2.9176 |
| SHORT2 | 3927121 | 11.3901 |
| SHORT3 | 376277 | 3.7208 |
| SHORT4 | 1923213 | 5.1629 |
| SHORT24 | 48 | 0.0005 |
| SHORT25 | 174 | 0.0018 |
| SHORT27 | 104 | 0.4710 |
| SHORT28 | 104 | 0.0074 |
| SHORT30 | 4620079 | 7.0143 |
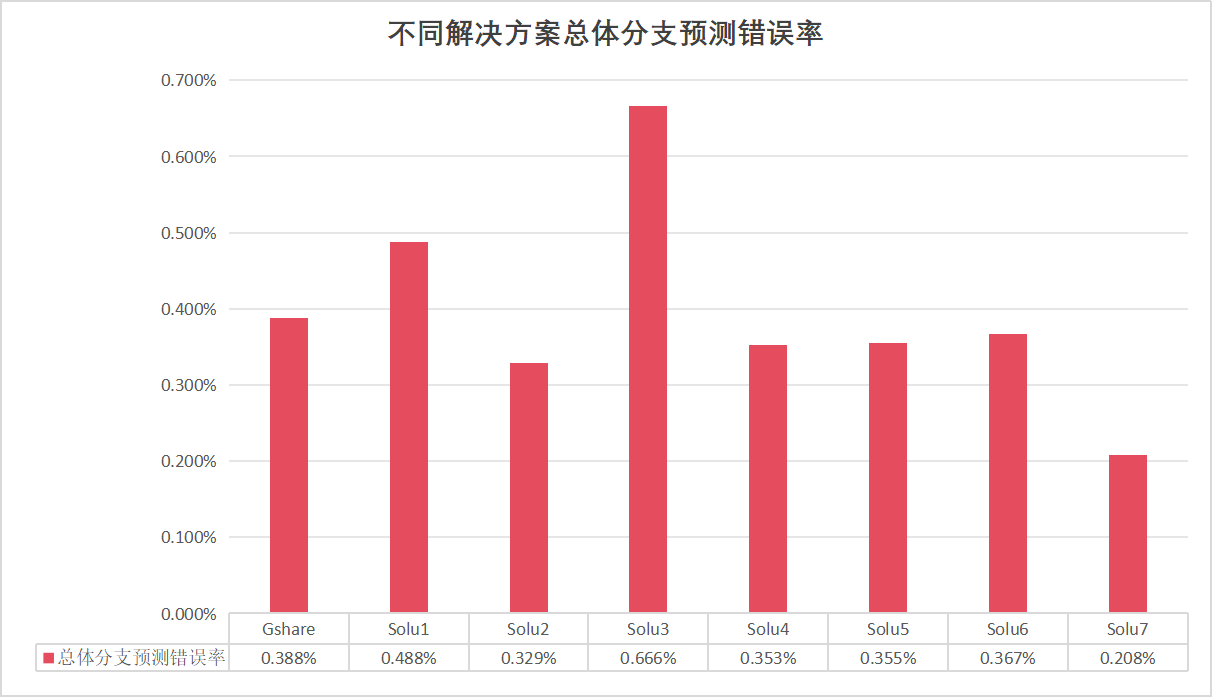
总体分支预测错误率
- 在做这个实验的时候,我发现每一次优化,对于不同的测试集效果不同,有的能降低错误率,但有的反而会提高错误率;因此,一种优化到底是好还是不好就很难客观地得出结论
- 那么,如果我直接把所有测试集中错误指令求和,除以总指令数,得出的总体分支预测错误率,是否可以作为一个综合性的分支预测效果评价指标?亦或有其他更好的方案?
- 经询问教员,最好的方案是对不同测试集的错误率赋予不同的权重,因为每个测试集中指令的类型和出现频率都有一定的差异;但如果不知道这个权重是多少,退而求其次,直接求平均值也是可行的
- 因此,后续实验以 总体分支预测错误率 = 所有测试集中错误指令条数 所有测试集中指令条数 总体分支预测错误率=\frac{所有测试集中错误指令条数}{所有测试集中指令条数} 总体分支预测错误率=所有测试集中指令条数所有测试集中错误指令条数 为评价标准
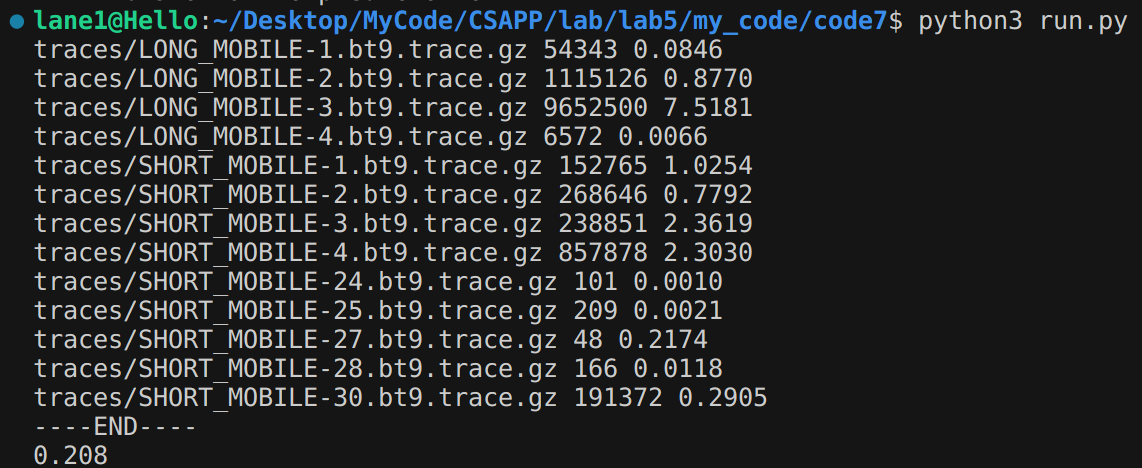
运行脚本
- 因为一共有13个测试集,一个一个测试太过麻烦,而且不方便把运行结果录入Excel表格进行比较
- 为简便起见,我写了一个名为
run.py的Python文件,可以实现自动对所有测试集进行测试,计算总体分支预测错误率,并在控制台打印NUM_MISPREDICTIONS和MISPRED_PER_1K_INST以及总体分支预测错误率这三个我比较关心的结果;还能自动把上述结果写在文件data.txt里,方便我拷贝到Excel中进行分析 - 运行效果如图所示
前六关
第一关:实现1位的分支预测器
- 代码中
#define PHT_CTR_MAX 3即为定义FSM的位数,此处的值有如下公式: P H T _ C T R _ M A X = 2 n − 1 PHT\_CTR\_MAX=2^n-1 PHT_CTR_MAX=2n−1- 因此,将模式历史表(PHT)的长度改为1即可
第二关:扩展全局分支历史长度
- 代码中
#define HIST_LEN 17即为定义全局历史寄存器长度,原本为17位,即能储存 2 17 2^{17} 217条历史信息- 因此,此处将长度增大即可,我改成了22
- 尝试改成更大的长度,例如32位,但是会溢出
第三关:为每个分支指令,分配完全独立的状态机
- 在代码的
UpdatePredictor和GetPrediction函数中,将PC中的后17位用&取出来,直接作为索引值;而不是采用hash函数- 即改为
UINT32 phtIndex = (PC & 0x1FFFF) % (numPhtEntries); - 其中,
0x1FFFF=0b1111_1111_1111_1111_1
- 即改为
第四关:扩展为3位状态机
- 和第一关类似,不再赘述
第五关:实现局部历史信息
- 和
pht类似,定义local history table(LHT,局部历史表)- 并完成对
lht的内存分配、初始化 - 在求索引值阶段,用
&取PC的后14位作为lht的索引值;后14位左侧的3位,与lht或运算后作为pht的索引值 - 之后对
lht做类似于pht的更新和释放内存操作
- 并完成对
UINT32 lhtIndex = (PC & 0x3FFF) % (numPhtEntries); // 0011_1111_1111_1111
UINT32 phtIndex = ((PC & 0x1C000) | lht[lhtIndex]) % (numPhtEntries); // 0001_1100_0000_0000_0000
- 这样就实现了对局部历史信息的保存和使用
第六关:实现局部+全局历史信息
- 目的就是将
pht和ghr结合起来,可以用^操作 - 在代码的
UpdatePredictor和GetPrediction函数中,对索引值作如下修改:
UINT32 lhtIndex = (PC & 0x3FFF) % (numPhtEntries); // 0011_1111_1111_1111
UINT32 phtIndex = (((PC & 0x1C000) | lht[lhtIndex]) ^ ghr) % (numPhtEntries); // 0001_1100_0000_0000_0000
- 这样就在第五关局部历史信息的基础上完成了对全局历史信息的使用
第七关:优化分支预测器
- 根据前面六关的结果,注意到扩展全局分支历史长度、使用局部和全局历史信息、扩展有限状态机位数等措施均能有效降低总体分支预测错误率
- 另外,通过实验发现,不同的hash函数对总体分支预测错误率也有显著影响
- 于是,我便开始了“赛博炼丹”:通过不断调整分支预测器的结构和各种参数来优化总体分支预测错误率,最终把总体分支预测错误率由原代码(Gshare)的0.388%,降低至0.208%,优化率达46.5%
- 具体优化措施如下
- 扩展有限状态机位数至3位
- 使用多位的状态机可以有效地识别出程序目前所处的状态,从而更好地预测分支
- 但是实验发现,位数过高使得程序变换跳转模式时敏感度下降,分支预测准确度反而降低
- 扩展全局分支历史长度至24位
- 这能有效减少不同指令的冲突,对于分支预测准确度的提升有较为可观的效果
- 但是分配空间受硬件条件限制不能过大,否则会报Overflow
- 实验发现,空间越大,预测准确度提升幅度越小;超过一定阈值后准确度甚至会下降
- 使用局部+全局历史
- 经过实验发现,将两部分的历史进行
^运算,优化效果最好
- 经过实验发现,将两部分的历史进行
- 除留余数法的除数改进为不超过最大值的素数
- 根据数据结构与算法课程学习的内容,除数为不超过最大值(pht和lht的最大值分别为 2 24 2^{24} 224和 2 20 2^{20} 220)的最大素数,能显著降低冲突率(经过实验发现,这一优化效果十分显著)
- 修改hash函数
- 这个东西真的很玄学,就是不断修改hash函数为各种结构,修改里面的每一个参数,我做了得有60多次的实验
- 这个hash函数的大体逻辑是
- 把
PC的末尾24位分成20+4 lht的索引值用&取后4位,与ghr异或后,进行除留余数pht的索引值用&取剩下的20位,与lht值移位后的结果取或,再进行除留余数
- 把
- 题目要求不用
^,但经过实验,不用^的错误率比较高- 事实上,这里的每一个符号我都已经尝试修改过了,这是最优的结果
#define LHTINDEX ((PC & 0xF) ^ ghr) % 1048573 #define PHTINDEX ((PC & 0xFFFFF0) | (lht[lhtIndex] << 11)) % 16777213
- 修改pht初始化的值
- 这个参数就更玄学了,我也是抱着试一试的心态把初始化的值由原本的2改成了3,对总体分支预测错误率有一定的降低效果
#define PHT_CTR_INIT 3
- 扩展有限状态机位数至3位
实验结果
- 详细实验数据见Excel表格
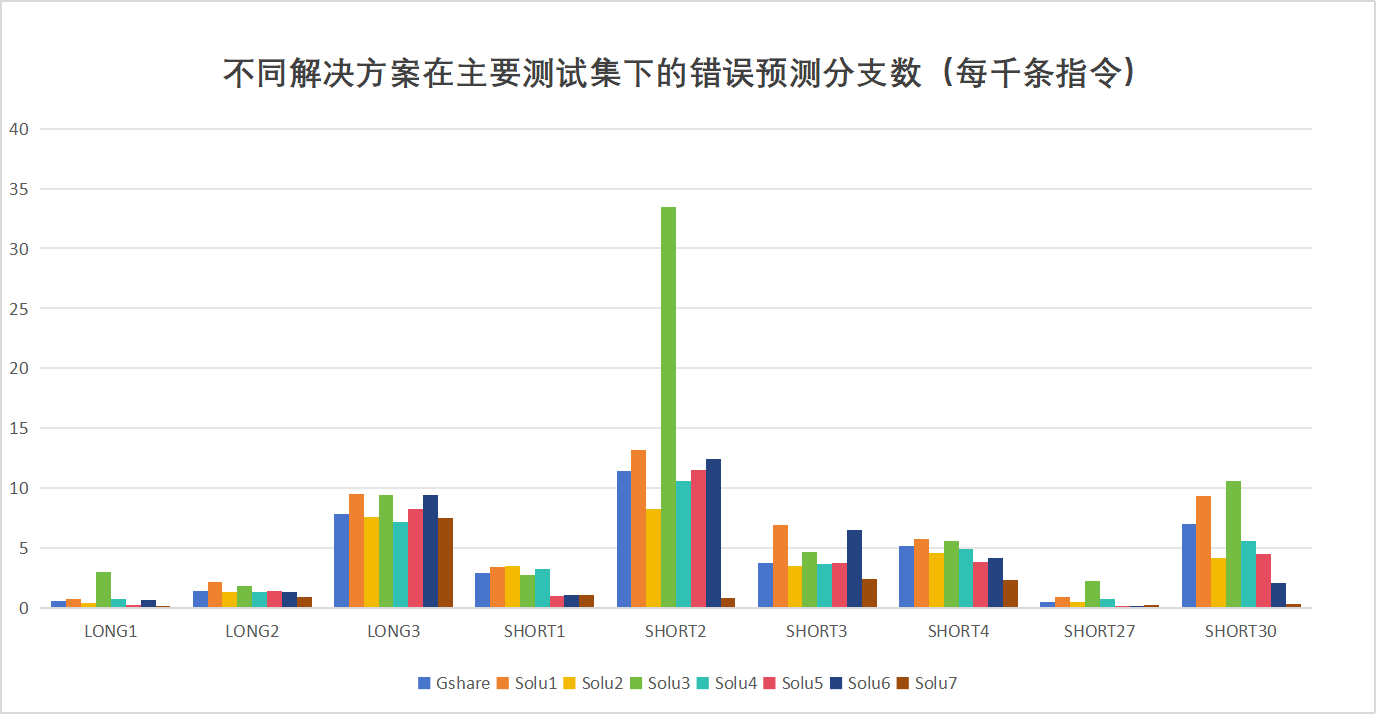
- 我把关键数据画成了图像,便于直观地比较















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









