










首先去下载作者发布在github上面的代码
为了防止我们之前的虚拟环境遭到破坏
我们首先重新克隆一个虚拟环境
conda create --name pytorch2 --clone pytorch
接下来
The code is built with the following dependencies:
- Python 3.6 or higher
- CUDA 10.0 or higher
- [PyTorch](https://pytorch.org/) 1.2 or higher
- [tqdm](https://github.com/tqdm/tqdm.git)
- matplotlib
- pillow
- tensorboardX
要下载1.2版本的pytorch
先查看一下我自己的各版本
我们还可以使用nvidia-smi命令来查看CUDA版本。
nvidia-smi我的是11.4的满足CUDA Version: 11.4
pytorch和python需要使用语句
python
import torch
print(torch.__version__)就可以查看到两个python和torch的版本了
我的python符合3.6
pytorch有1.10.2
环境是符合的
1、 在mypath.py中定义自己的数据集
class Path(object):
@staticmethod
def db_root_dir(dataset):
if dataset == 'spacenet':
return '/home/mj/data/work_road/data/SpaceNet/spacenet/result_3m/'
elif dataset == 'DeepGlobe':
return '/home/mj/data/work_road/data/DeepGlobe/'
elif dataset == 'myroaddata':
return '/home/wangtianni/CoANet-main/CoANet-main/data/myroaddata/'
else:
print('Dataset {} not available.'.format(dataset))
raise NotImplementedError在里面加入我们自己的dataset,名字定义为myroaddata
2、修改create_crops.py中我们的数据集的格式
认真看了代码后
发现需要准备的数据有
目录下gt文件夹放标签
images文件夹放原图
除此之外

需要提前准备val.txt里面放置预测图像的名称
train.txt里面放置训练图像的名称
这样才能读取里面的name设置图片格式
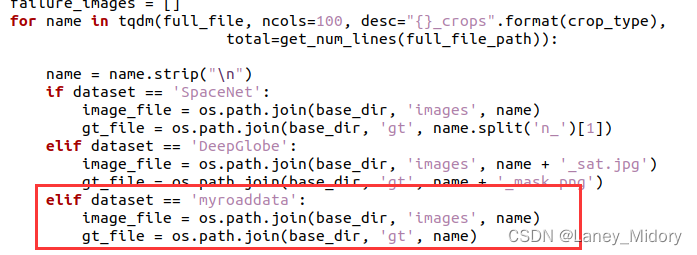
py文件里面需要改的一共有两处
这里贴一下我定义后改好的create_crops.py
"""
create_crops.py: script to crops for training and validation.
It will save the crop images and mask in the format:
<image_name>_<x>_<y>.<suffix>
where x = [0, (Image_Height - crop_size) / stride]
y = [0, (Image_Width - crop_size) / stride]
It will create following directory structure:
base_dir
| train_crops.txt # created by script
| val_crops.txt # created by script
|
└───crops # created by script
│ └───gt
│ └───images
"""
from __future__ import print_function
import argparse
import os
import mmap
import cv2
import time
import numpy as np
from skimage import io
from tqdm import tqdm
tqdm.monitor_interval = 0
def verify_image(img_file):
try:
img = io.imread(img_file)
except:
return False
return True
def CreatCrops(base_dir, dataset, crop_type, size, stride, image_suffix, gt_suffix):
crops = os.path.join(base_dir, 'crops')
if not os.path.exists(crops):
os.mkdir(crops)
os.mkdir(crops+'/images')
os.mkdir(crops+'/gt')
crops_file = open(os.path.join(base_dir,'{}_crops.txt'.format(crop_type)),'w')
full_file_path = os.path.join(base_dir,'{}.txt'.format(crop_type))
full_file = open(full_file_path,'r')
def get_num_lines(file_path):
fp = open(file_path, "r+")
buf = mmap.mmap(fp.fileno(), 0)
lines = 0
while buf.readline():
lines += 1
return lines
failure_images = []
for name in tqdm(full_file, ncols=100, desc="{}_crops".format(crop_type),
total=get_num_lines(full_file_path)):
name = name.strip("\n")
if dataset == 'SpaceNet':
image_file = os.path.join(base_dir, 'images', name)
gt_file = os.path.join(base_dir, 'gt', name.split('n_')[1])
elif dataset == 'DeepGlobe':
image_file = os.path.join(base_dir, 'images', name + '_sat.jpg')
gt_file = os.path.join(base_dir, 'gt', name + '_mask.png')
elif dataset == 'myroaddata':
image_file = os.path.join(base_dir, 'images', name+ '.tif')
gt_file = os.path.join(base_dir, 'gt', name+ '.png')
if not verify_image(image_file):
failure_images.append(image_file)
continue
image = cv2.imread(image_file)
gt = cv2.imread(gt_file,0)
if image is None:
failure_images.append(image_file)
continue
if gt is None:
failure_images.append(image_file)
continue
H,W,C = image.shape
maxx = int((H-size)/stride)
maxy = int((W-size)/stride)
if dataset == 'SpaceNet':
name = name.split('.')[0]
name_a = name.split('n_')[1]
elif dataset == 'DeepGlobe':
name_a = name
elif dataset == 'myroaddata':
name_a = name
for x in range(maxx+1):
for y in range(maxy+1):
im_ = image[x*stride:x*stride + size,y*stride:y*stride + size,:]
gt_ = gt[x*stride:x*stride + size,y*stride:y*stride + size]
crops_file.write('{}_{}_{}.png\n'.format(name,x,y))
cv2.imwrite(crops+'/images/{}_{}_{}.png'.format(name,x,y), im_)
cv2.imwrite(crops+'/gt/{}_{}_{}.png'.format(name_a,x,y), gt_)
crops_file.close()
full_file.close()
if len(failure_images) > 0:
print("Unable to process {} images : {}".format(len(failure_images), failure_images))
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--base_dir', type=str, default='../../data/SpaceNet/spacenet/result_3m',
help='Base directory for Spacenent Dataset.')
parser.add_argument('--dataset', type=str, default='DeepGlobe',
choices=['SpaceNet', 'DeepGlobe', 'myroaddata'], help='dataset name')
parser.add_argument('--crop_size', type=int, default=650,
help='Crop Size of Image')
parser.add_argument('--crop_overlap', type=int, default=0,
help='Crop overlap Size of Image')
parser.add_argument('--im_suffix', type=str, default='.png',
help='Dataset specific image suffix.')
parser.add_argument('--gt_suffix', type=str, default='.png',
help='Dataset specific gt suffix.')
args = parser.parse_args()
start = time.clock()
# Create crops for training
CreatCrops(args.base_dir,
args.dataset,
crop_type='train',
size=args.crop_size,
stride=args.crop_size,
image_suffix=args.im_suffix,
gt_suffix=args.gt_suffix)
## Create crops for validation
CreatCrops(args.base_dir,
args.dataset,
crop_type='val',
size=args.crop_size,
stride=args.crop_size,
image_suffix=args.im_suffix,
gt_suffix=args.gt_suffix)
end = time.clock()
print('Finished Creating crops, time {0}s'.format(end - start))
if __name__ == "__main__":
main()很明显
这个txt里面需要写的就是图片的名称
我之前在跑segnext的时候也写过相关的代码
这里直接改改路径用就行了
import mmcv
import os.path as osp
data_root = "/home/wangtianni/CoANet-main/CoANet-main/data/myroaddata/"
#valid_root = "/home/wangtianni/SegNeXt-main/SegNeXt-main/data/data/MyRoadData/images/"
ann_dir = "gt"
split_dir = 'splits'
mmcv.mkdir_or_exist(osp.join(osp.abspath(osp.join(data_root,"..")), split_dir))
filename_list = [filename[:-4] for filename in mmcv.scandir(
osp.join(data_root +ann_dir), suffix='.png')]
with open(osp.join(osp.abspath(osp.join(data_root,"..")),split_dir, 'train.txt'), 'w') as f:
# select first 4/5 as train set
train_length = int(len(filename_list))
f.writelines(line + '\n' for line in filename_list[:train_length])
#validname_list = [filename[:-8] for filename in mmcv.scandir(
# osp.join(valid_root, ann_dir), suffix='.tif')]
##with open(osp.join(data_root, '../',split_dir, 'val.txt'), 'w') as f:
#with open(osp.join(osp.abspath(osp.join(data_root,"..")),split_dir, 'val.txt'), 'w') as f:
# # select last 1/5 as train set
# valid_length = int(len(validname_list))
# f.writelines(line + '\n' for line in validname_list[:valid_length])这样就得到了train.txt
所需材料收集齐全就可以开始炼丹啦

但这里一定要注意,这个程序是需要有validation数据集的
因此要照猫画虎
在新建一个val.txt放置验证的图片
图片还是放在gt和images里面
然后运行
python create_crops.py --base_dir ./data/myroaddata --dataset myroaddata --crop_size 512不过报错
Traceback (most recent call last):
File "create_crops.py", line 26, in <module>
from skimage import io
ModuleNotFoundError: No module named 'skimage'
需要下载这个模块
这下新建一个虚拟环境的优势就有啦
免得我们的修改造成其他环境的损坏
安装这个库
pip install scikit-image
安装成功后就可以运行上面的切割图片语句啦

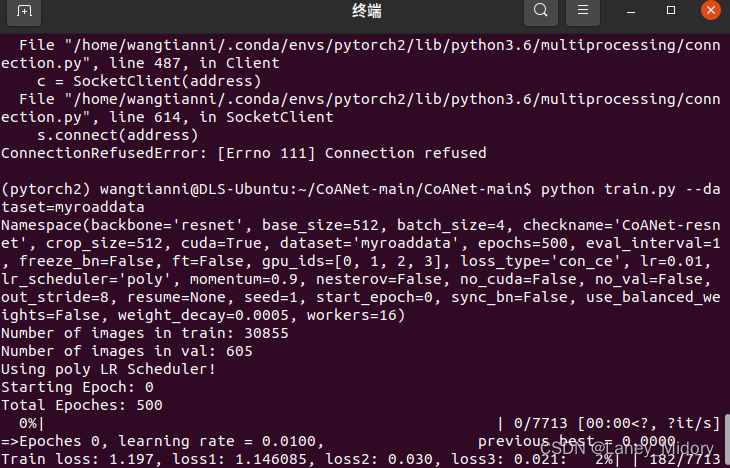
跑出来的结果如下:

裁剪结果都在crops里面了,不过黑色的样本没有被删除
可以先不删除,先跑跑试试
如果是deepglobe的数据集,则切割语句如下:
python create_crops.py --base_dir ./data/deepglobe/ --dataset DeepGlobe --crop_size 512
3、修改create_connection.py的配置
python create_connection.py --base_dir ./data/myroaddata/cropspy文件不用改,只用写一下路径就行
就开始运行啦
运行后会得到

如果是deepglobe的数据集,则语句如下:
python create_connection.py --base_dir ./data/deepglobe/crops
4、修改train.py的相关配置
运行这个语句
python train.py --dataset=myroaddata
如果是deepglobe的数据集,则语句如下:
python train.py --dataset=DeepGlobe报错:
ModuleNotFoundError: No module named 'prefetch_generator'
需要安装这个模块
pip install prefetch_generator直接安装即可
继续运行train.py
还是报错
ModuleNotFoundError: No module named 'tensorboardX'
那么继续安装
tensorboardX安装:
因为tensorboardX是对tensorboard进行了封装后,开放出来使用,所以必须先安装tensorboard, 再安装tensorboardX,
(而如果不需要,可以不安装tensorflow,只是有些功能会受限)
直接使用pip/conda安装:
pip install tensorboard
pip install tensorboardX
安装好后
继续运行
报错
Traceback (most recent call last):
File "train.py", line 342, in <module>
main()
File "train.py", line 331, in main
trainer = Trainer(args)
File "train.py", line 71, in __init__
self.model = torch.nn.DataParallel(self.model, device_ids=self.args.gpu_ids)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 142, in __init__
_check_balance(self.device_ids)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 23, in _check_balance
dev_props = _get_devices_properties(device_ids)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/_utils.py", line 464, in _get_devices_properties
return [_get_device_attr(lambda m: m.get_device_properties(i)) for i in device_ids]
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/_utils.py", line 464, in <listcomp>
return [_get_device_attr(lambda m: m.get_device_properties(i)) for i in device_ids]
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/_utils.py", line 447, in _get_device_attr
return get_member(torch.cuda)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/_utils.py", line 464, in <lambda>
return [_get_device_attr(lambda m: m.get_device_properties(i)) for i in device_ids]
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/cuda/__init__.py", line 359, in get_device_properties
raise AssertionError("Invalid device id")
AssertionError: Invalid device id
这个时候我猜测应该是多GPU运行的问题
查了半天
这个语句self.model = torch.nn.DataParallel(self.model, device_ids=self.args.gpu_ids)
但还是报错
现在终于解决了:
使用这个语句查看GPU的id
nvidia-smi
然后查看前面的id

我的前面都是0
所以把这个语句改成
if args.cuda:
#self.model = torch.nn.DataParallel(self.model, device_ids=self.args.gpu_ids)
device_ids = [0]
self.model = torch.nn.DataParallel(self.model, device_ids=device_ids).cuda()
patch_replication_callback(self.model)
self.model = self.model.cuda()
就可以成功啦!
如果不按照上面的办法做的话,直接暴力注释掉这段代码会报下面的错误:
报错:
Traceback (most recent call last):
File "train.py", line 344, in <module>
main()
File "train.py", line 337, in main
trainer.training(epoch)
File "train.py", line 118, in training
output, out_connect, out_connect_d1 = self.model(image)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/wangtianni/CoANet-main/CoANet-main/modeling/coanet.py", line 29, in forward
e1, e2, e3, e4 = self.backbone(input)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/wangtianni/CoANet-main/CoANet-main/modeling/backbone/resnet.py", line 114, in forward
x = self.conv1(input)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 446, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/home/wangtianni/.conda/envs/pytorch2/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 443, in _conv_forward
self.padding, self.dilation, self.groups)
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
我搜了一下发现这段报错指的是
就像是字面意思那样,这个错误是因为模型中的 weights 没有被转移到 cuda 上,而模型的数据转移到了 cuda 上而造成的
但是造成这个问题的原因却没有那么简单。
绝大多数时候,造成这个的原因是因为你定义好模型之后,没有对模型进行 to(device) 而造成的,但是,也有可能,是因为你的模型在定义的时候,没有定义好,导致模型的一部分在加载的时候没有办法转移到 cuda上。
具体的解释可以查看这篇博文(Pytorch避坑之:RuntimeError: Input type(torch.cuda.FloatTensor) and weight type(torch.FloatTensor) shoul)
改好之后就没有报错啦,把batchsize设置小一点
就可以跑起来了

















 1525
1525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











