







正则表达式的作用
# 1,在一大堆文本字符在找到自己想要的字符 # 过滤 爬虫 # 2,验证是否合法
re模块
1,search和match
search和match都是查找第一个匹配
match只能从字符串开头查找,开头部分没有,那就匹配不上,只匹配开头部分
如果匹配到了,就会返回一个match对象,

#findall或者finditer
findall--查找所有匹配的,返回的是一个列表

finditer --得到的结果是个迭代器

##########正则替换(灵活性比较强)sub

#############编译正则compile
先将正则表达式编译成一个对象,再使用对象去匹配


######################################正则表达式规则、
#区间匹配

##或匹配
msg= "xdj fajgv dfld ngam ddg"
print(re.findall("so|dj",msg))
#.占位符 表示除了换行符以外的任意一个字符
ret = re.findall("p.thon","python Python pgthon p thon p\nthon")
print(ret)
#只能匹配上python pgthon p thon
##快捷方式
# \A 匹配字符串的开始 # ^ # \b 词边界 # \B 非词边界 # \w 匹配单词字符 # \W 匹配非单词字符 # \s 匹配空白字符 # \S 匹配非空白字符 # \d 匹配数字 # \D 匹配非数字 # r的作用时抑制转义 # 原样交给正则表达引擎去匹配
####标志位
ret = re.findall("^[Pp]ython",msg,re.M|re.I)
#re.M匹配多行,re.I忽略大小写,re.S让.表示任意字符,包括换行符
print(ret)
ret = re.findall("^[python]",msg,re.I)
###通配符
{n,m} 匹配前一项n-m次

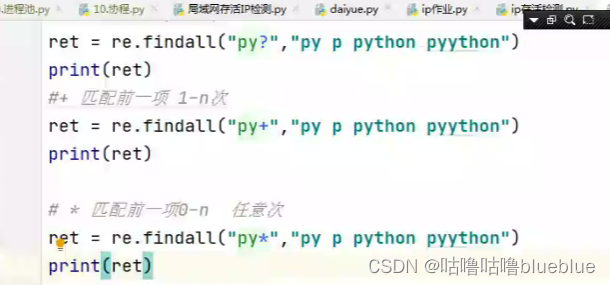
####贪婪模式与非贪婪模式


# #捕获分组(正则表达式)
# #分组匹配上之后,会把匹配上的数据放到内存中,并给一个从一开始的索引
# ret = re.search(r"(\d{3})-(\d{3})-(\d{3})","abc-123-456-789aaa")
# print(ret.group())
# print(ret.group(1))
# print(ret.group(2))
# print(ret.group(3))
# #非捕获分组(?:正则表达式)
# #只分组,不捕获,不会分配下标也不会保存
##分组向后引用

####零宽断言
拿ip:

##零宽断言 #不占用匹配宽度,确定位置 s = "sc1 hello sc2 hello" #匹配后面是sc2的hello print(re.findall(r"hello(?= sc2)",s)) #匹配后面不是sc2的hello print(re.findall(r"hello(?! sc2)",s)) #匹配前面是sc2 的hello print(re.findall(r"(?<=sc2 )hello",s)) #匹配前面不是sc2 的hello print(re.findall(r"(?<!sc2 )hello",s))















 2003
2003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









