







1. 正则表达式:
是一种字符串验证的规则,通过特殊的字符串组合来确立规则
用规则去匹配字符串是否满足
如(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)可以表示为一个标准邮箱的格式
re模块的三个主要方法:
re.match:
re.match(匹配规则, 被匹配字符串)
从被匹配字符串开头进行匹配, 匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空。从头开始匹配,匹配第一个命中项
re.search:
re.search(匹配规则, 被匹配字符串)
从被匹配字符串开头进行匹配, 匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空。全局匹配,匹配第一个命中项
re.findall:
re.findall(匹配规则, 被匹配字符串)
匹配整个字符串,找出全部匹配项,找不到返回空list: []。
全局匹配,匹配全部命中项
import re
s = "1python python python"
# match 从头匹配
result = re.match("python", s)
print(result)
# print(result.span())
# print(result.group())
# search 搜索匹配
result = re.search("python2", s)
print(result)
# findall 搜索全部匹配
result = re.findall("python", s)
print(result)2. 掌握正则表达式的各类元字符规则
单字符匹配:
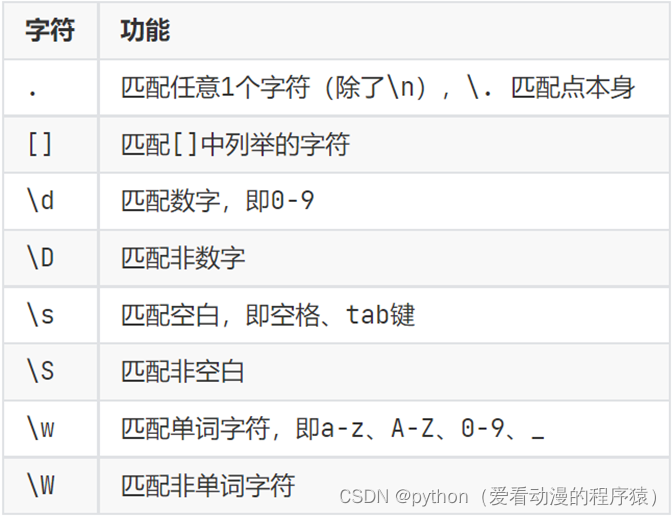 找出全部数字: re.findall(r‘\d’, s)
找出全部数字: re.findall(r‘\d’, s)
注意:字符串的r标记,表示当前字符串是原始字符串,即内部的转义字符无效而是普通字符
找出特殊字符:re.findall(r‘\W’, s)
找出全部英文字母:re.findall(r’[a-zA-Z]’, s)
注意:[]内可以写:[a-zA-Z0-9] 这三种范围组合或指定单个字符如[aceDFG135]
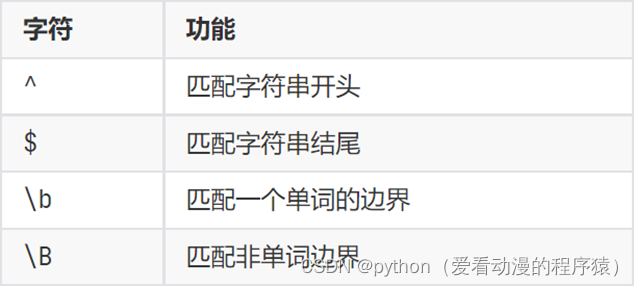
数量匹配:

边界匹配:
分组匹配:
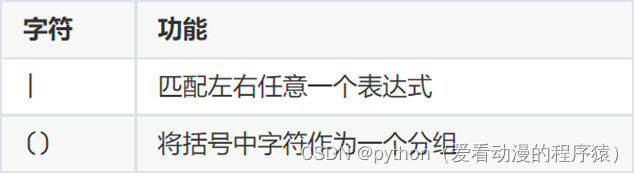
匹配账号:只能由字母和数字组成,长度限制6到10位,规则为: ^[0-9a-zA-Z]{6, 10}$
匹配QQ号:要求纯数字,长度5-11,第一位不为0,规则为:^[1-9][0-9]{4, 10}&
[1-9]匹配第一位,[0-9]匹配后面4到10位
匹配邮箱地址:只允许qq、163、gmail这三种邮箱地址,规则为:^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+&
[\w-]+ 表示出现a-z A-Z 0-9 _ 和 - 字符最少一个,最多不限
(\.[\w-]+)*,表示出现组合 . 和 a-z A-Z 0-9 _ -的组合最少0次,最多不限
用于匹配:abc.ced.efg@123.com中的ced.efg这部分
@表示匹配@符号
(qq|163|gmail)表示只匹配这3个邮箱提供商
(\.[\w-]+)+表示a-z A-Z 0-9 _ -的组合最少1次,最多不限
用于匹配abc.ced.efg@123.com.cn中的.com.cn这种
最后使用+表示最少一次,即比如:.com
多了可以是:.com.cn.eu这样
import re
# s = "lala @@python2 !!666 ##ast3"
#
# result = re.findall(r'[b-eF-Z3-9]', s) # 字符串前面带上r的标记,表示字符串中转义字符无效,就是普通字符的意思
# print(result)
# 匹配账号,只能由字母和数字组成,长度限制6到10位
# r = '^[0-9a-zA-Z]{6,10}$'
# s = '123456_'
# print(re.findall(r, s))
# 匹配QQ号,要求纯数字,长度5-11,第一位不为0
# r = '^[1-9][0-9]{4,10}$'
# s = '123453678'
# print(re.findall(r, s))
# 匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
# abc.efg.daw@qq.com.cn.eu.qq.aa.cc
# abc@qq.com
# {内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}@{内容}.{内容}.{内容}
r = r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
# s = 'a.b.c.d.e.f.g@qq.com.a.z.c.d.e'
s = 'a.b.c.d.e.f.g@126.com.a.z.c.d.e'
print(re.match(r, s))3. 递归:
在满足条件的情况下,函数自己调用自己的一种特殊编程技巧
注意:
注意退出的条件,否则容易变成无限递归
os模块的3个方法:
os.listdir,列出指定目录下的内容
os.path.isdir,判断给定路径是否是文件夹,是返回True,否返回False
os.path.exists,判断给定路径是否存在,存在返回True,否则返回False
import os
def test_os():
"""演示os模块的3个基础方法"""
print(os.listdir("D:/test")) # 列出路径下的内容
# print(os.path.isdir("D:/test/a")) # 判断指定路径是不是文件夹
# print(os.path.exists("D:/test")) # 判断指定路径是否存在
def get_files_recursion_from_dir(path):
"""
从指定的文件夹中使用递归的方式,获取全部的文件列表
:param path: 被判断的文件夹
:return: list,包含全部的文件,如果目录不存在或者无文件就返回一个空list
"""
print(f"当前判断的文件夹是:{path}")
file_list = []
if os.path.exists(path):
for f in os.listdir(path):
new_path = path + "/" + f
if os.path.isdir(new_path):
# 进入到这里,表明这个目录是文件夹不是文件
file_list += get_files_recursion_from_dir(new_path)
else:
file_list.append(new_path)
else:
print(f"指定的目录{path},不存在")
return []
return file_list
if __name__ == '__main__':
print(get_files_recursion_from_dir("D:/test"))
def a():
a()
















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











