







文章目录
数据预处理
归一化
sklearn.preprocessing.MinMaxScaler
通过对原始数据进行变换把数据映射到(默认为[0,1])之间。

note:
注意在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
标准化
scikit-learn.preprocessing.StandardScaler
通过对原始数据进行变换把数据变换到均值为0,方差为1范围内。

归一化和标准化区别在于异常值的影响程度,归一化的异常点影响最大最小值从而影响结果,标准化由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
缺失值处理
sklearn.preprocessing.Imputer
删除:如果每列或者行数据缺失值达到一定的比例,建议放弃整行或者整列
插补:可以通过缺失值每行或者每列的平均值、中位数来填充
特征选择
原因
sklearn.feature_selection.VarianceThreshold
冗余:部分特征的相关度高,容易消耗计算性能
噪声:部分特征对预测结果有负影响
主要方法(三大武器):
Filter(过滤式):VarianceThreshold
Embedded(嵌入式):正则化、决策树
Wrapper(包裹式)
降维
sklearn. decomposition
PCA(n_components=None)
PCA.fit_transform(X)
PCA:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
问题: 高维度数据特征之间通常是线性相关的
LDA
监督学习
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
分类学习
k-近邻算法
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
计算距离公式:欧式距离
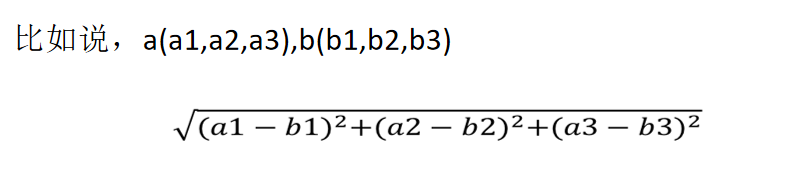
k值取值:
k值取很小:容易受异常点影响
k值取很大:容易受最近数据太多导致比例变化
优缺点

贝叶斯分类
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
alpha:拉普拉斯平滑系数

贝叶斯公式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1126
1126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









