







 本文介绍了在Tensorflow中,将Mnist手写集分类模型的二次代价函数替换为交叉熵代价函数的过程,通过代码示例展示了如何计算损失值并优化模型。经过改进,模型在20次迭代后的准确率提升至0.97以上。
本文介绍了在Tensorflow中,将Mnist手写集分类模型的二次代价函数替换为交叉熵代价函数的过程,通过代码示例展示了如何计算损失值并优化模型。经过改进,模型在20次迭代后的准确率提升至0.97以上。
Tensorflow学习笔记:基础篇(5)——Mnist手写集改进版(交叉熵代价函数)
前序
— 前文中,我们的改进版本实现了一个三层(不包括输入层)全连接神经网络来完成MNIST数据的分类问题,输入层784个神经元,隐藏层500和300个神经元,输出层10个神经元,最终迭代计算20次,准确率接近0.96,本文我们在此基础上继续修改,将方差代价函数(二次代价函数)替换成交叉熵函数,看看有什么效果~~
Reference:
前文博客:Mnist手写集改进版
交叉熵代价函数
方差代价函数&交叉熵代价函数
C 表示代价函数,为简单起见,以一个样本为例进行说明,此时二次代价函数为:
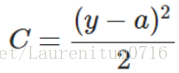
其中,y是我们期望的输出,a为神经元的实际输出:a=σ(z),z=wx+b
假如我们使用梯度下降法(Gradient descent)来调整权值参数的大小,权值w和偏置b的梯度推导如下:
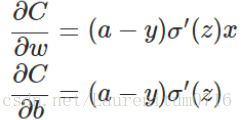
其中,z表示神经元的输入,σ表示激活函数。w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整得越快,训练收敛得就越快。
假设我们的激活函数是sigmoid函数:
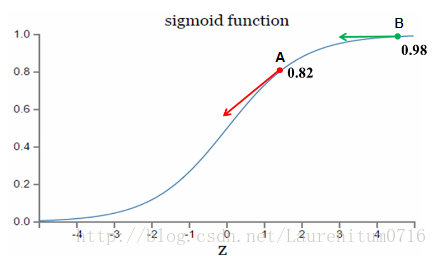
因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会很小(如上图标出来的B点,几近于平坦),这样会使得w和b更新非常慢(因为σ′(z)这一项接近于0)。
为了克服这个缺点,换一个思路,我们不改变激活函数,而是改变代价函数,改用交叉熵代价函数:
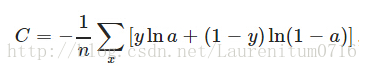
其中,y为期望的输出,a为神经元实际输出:a=σ(z), z=∑Wj*Xj+b
同样,权值w和偏置b的梯度推导如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









