







 这篇博客详细介绍了如何使用Tensorflow构建CNN模型处理CIFAR-10数据集。内容涵盖CIFAR-10数据集的特点、数据读取方法、模型构建过程以及运行结果。通过训练,模型在200个周期后达到训练准确率0.62和测试准确率0.498。
这篇博客详细介绍了如何使用Tensorflow构建CNN模型处理CIFAR-10数据集。内容涵盖CIFAR-10数据集的特点、数据读取方法、模型构建过程以及运行结果。通过训练,模型在200个周期后达到训练准确率0.62和测试准确率0.498。
Tensorflow学习笔记:CNN篇(3)——CIFAR-10数据集的CNN实现
前序
—在前面的介绍中,使用卷积神经网络对MNIST数据集做了应用,然而MNIST数据集仅限于对手写数字的识别,而且手写数字相对于自然物体和图片非常简单,也缺少相应的噪声和变换。
—本文将使用CNN对CIFAR-10数据集进行验证,同时会比较不同参数作用下卷积神经网络对准确率产生的影响。
CIFAR-10数据集
CIFAR-10数据集官网
从网站首页可以看到,这里提供10个分类的现实物体的图片,与前面所讲的成熟的人工手写识别相比,现实物体识别挑战巨大,而且图片中含有大量特征、噪声,识别物体比例不一,也加大了识别的难度,使其非常具有挑战性。

官网提供了数据集的下载,这里选用python版本

此外,官网提供了CIFAR-10的数据结构介绍:

可以看到,数据集中的数据分成了两部分:第一部分是特征部分,使用一个[10000,3072的uint8的矩阵进行存储,每一行向量都是3X3大小的3通道图片,构成的格式类似于[3,3,3];第二部分为标签部分,使用一个10000数据的list进行存储,每个list对应的是0-9中的一个数字,对应于物品分类。另外对于python的数据集,还有一个标签为“label_names”,例如label_names[0] == “airplane”等。
对于具体的数据读取,官网上也提供了相应的代码:
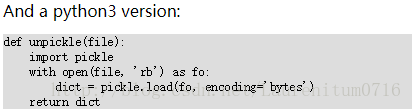
代码实例
1、数据读取
前面说到,label是一个包含0-9的list列表,根据之前我们用到的one-hot方法,采用稀疏性列表法,即10个列表数字中只有对应的那个值为1,其他值都为0,因此需要将list格式转化成对应的one-hot矩阵。
def unpickle(filename):
with open(filename, 'rb') as f:
d = pickle.load(f, encoding='latin1')
return d
def onehot(labels):
'''one-hot 编码'''
n_sample = len(labels)
n_class = max(labels) + 1
onehot_labels = np.zeros((n_sample, n_class))
onehot_labels[np.arange(n_sample), labels] = 1
return onehot_labels
# 训练数据集
data1 = unpickle('cifar10-dataset/data_batch_1')
data2 = unpickle('cifar10-dataset/data_batch_2')
data3 = unpickle('cifar10-dataset/data_batch_3')
data4 = unpickle('cifar10-dataset/data_batch_4')
data5 = unpickle('cifar10-dataset/data_batch_5')
X_train = np.concatenate((data1['data'], data2['data'], data3['data'], data4['data'], data5['data']), axis=0)
y_train = np.concatenate((data1['labels'], data2['labels'], data3['labels'], data4['labels'], data5['labels']), axis=0)
y_train = onehot(y_train)
# 测试数据集
test = unpickle('cifar10-dataset/test_batch')
X_test = test['data'][:5000, :]
y_test = onehot(test['labels'])[:5000, :]
print('Training dataset shape:', X_train.shape)
print('Training labels shape:', y_train.shape)
print('Testing dataset shape:', X_test.shape)
print('Testing labels shape:', y_test.shape)这里使用unpick函数依次读取5个batch中的数据,生成5个dict格式文件,而其中的数据以[data, labels]格式存放,之后链接对应的5个特征数据和标签数据生成最终的训练集,采用前5000个数据作为测试集进
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









