








本文由浙江大学、旷视科技、华中科技大学、清华大学、东京大学的研究人员共同完成,阵容可谓相当强悍了。本文发表于CVPR2019.
论文地址:An End-to-End Network for Panoptic Segmentation
本人将CVPR2019关于Segmentation的文章放在云盘了,需要的朋友自取CVPR2019-segmentation,提取密码为:0d8b
背景
开始说文章之前,有几点需要明确。什么是Panoptic segmentation,它与其他分割任务的差异在哪?

语义分割和实例分割就不赘述了,上图b和d极为类似,但是要注意到的是全景分割中的实例没有重叠区域、此外还需同时识别stuff和things.
那么things、stuff的差异是什么?图像中的内容按照是否有固定形状分为things和stuff
things:指人、车等有固定形状的物体;
stuffs指天空、草地等没有固定形状的物体。通常来说,可数名词属于things,不可数名词属于stuff.
Panoptic segmentation译作全景分割,要求对图像中的每一个像素分配一个类别标签,同时分割图片中的每一个对象实例。此前何恺明等人在Panoptic Segmentation一文中,使用两个模型独立的完成前景、背景模块的分割。由于在训练过程中不共享任何特征,同时需要后处理过程融合不同模型预测的分割结果,相对来说整体模型复杂、低效难以执行。并且在合并两个模型的结果时使用启发式算法在没有足够上下文信息的情况下很难确定对象实例之间的重叠关系。这样就使得这样的算法很难应用到工业界。
Panoptic segmentation由何恺明等人在Panoptic Segmentation中首次提出。此前的研究方法主要有弱监督学习方法、JSIS-Net、AUNet等。
本文针对于全景分割任务,提出一种端到端的闭环模型,能够在单一模型中有效的预测instance和stuff分割。此外还引出一种新的空间排序模块处理预测实例之间的冲突问题。整合instance segmentation和stuff segmentation到一个网络结构中,这两个任务共享主干特征,但对于不同任务有不同的分支结构处理,如下图:

模型结构
模型的整体构架如下图,主要包含以下几个方面:
stuff branch预测整个输入的stuff分割结果。instance branch预测实例分割。spatial ranking model空间排序模型对每个实例产生排名得分。

在训练过程中,累计两个分支的损失优化模型,而对于每一个分支,则根据具体任务进行微调。
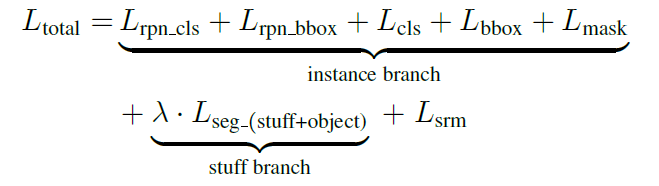
其中
L
r
p
n
−
c
l
s
L_{rpn-cls}
Lrpn−cls和
L
r
p
n
−
b
b
o
x
L_{rpn-bbox}
Lrpn−bbox分别代表RPN中的分类损失和回归框回归损失。
端到端模型结构
将FPN结构作为端到端网络的Backbone,在实例分割分支中使用原始Mask R-CNN模型,采用自上而下的路径以及横向连接得到特征图,然后使用一个3*3大小的卷积层以获得RPN特征图,而后使用RoI Align提取特征,产生三个预测值。
Stuff segmentation
对于Stuff segmentation模块,对于RPN之后得到的特征图添加两个3*3大小的卷积以及一个1*1的卷积。训练过程中,由于辅助的标记信息可以为事物的预测提供对象的上下文,stuff segmentation和thing segmentation可以同时进行,因为只用提取stuff预测,并将之归一化为概率值。

Instance Segmentation Branch
分割模块是采用的Mask R-CNN模型。

Spatial ranking module
在全景分割任务中,由于一幅图像中的像素数目是固定的,因此必须解决重叠问题,特别是一个像素的多重分配问题。一般而言,通常采用检测得分对实例进行排序,但是这种启发式算法在实际中容易失败。文中举的例子是:
上图中男子的领带也是一个实例,但是在启发式算法对目标实例进行排序中被忽略掉了,导致整体性能降低。因为人这一类别的出现频率比领带高。
文中首先使用对领带打标记注释然后用对领带标注的图片进行训练但是性能并没有提升。(几张图某几个类别的标记怎么可能改变这一现象呢…)
然后作者提出spatial ranking module用以解决遮挡问题。
首先将实例分割的结果映射到输入大小的张量。特征映射的维度等于对象类别。将不同类别的实例引射到对应的通道。实例张量的初始值为0,映射值则为1.在张量之后采用大的卷积核以产生排序得分图。最后使用像素级的交叉熵损失函数优化排序得分图。
L
s
r
m
=
C
E
(
S
m
a
p
,
S
l
a
b
e
l
)
L_{\mathrm{srm}}=C E\left(S_{m a p}, S_{l a b e l}\right)
Lsrm=CE(Smap,Slabel)
其中
S
m
a
p
S_{map}
Smap为输出的得分图,
S
l
a
b
e
l
S_{label}
Slabel为相应的无重叠的语义标签。对于得到的排序分数图,按如下公式计算每个实例对象的排名分数。
P
o
b
j
s
=
∑
(
i
,
j
)
∈
o
b
j
s
S
i
,
j
,
c
l
s
⋅
m
i
,
j
∑
(
i
,
j
)
∈
o
b
j
s
m
i
,
j
P_{o b j s}=\frac{\sum_{(i, j) \in o b j s} S_{i, j, c l s} \cdot m_{i, j}}{\sum_{(i, j) \in o b j s} m_{i, j}}
Pobjs=∑(i,j)∈objsmi,j∑(i,j)∈objsSi,j,cls⋅mi,j
其中
m
i
,
j
=
{
0
(
i
,
j
)
∈
instance
1
(
i
,
j
)
∉
instance
m_{i, j}=\left\{\begin{array}{ll}{0} & {(\mathrm{i}, \mathrm{j}) \in \text { instance }} \\ {1} & {(\mathrm{i}, \mathrm{j}) \notin \text { instance }}\end{array}\right.
mi,j={01(i,j)∈ instance (i,j)∈/ instance
其中,
S
i
,
j
,
c
l
s
S_{i, j, c l s}
Si,j,cls是标准化后的概率分布,代表某一类
c
l
s
cls
cls在
(
i
,
j
)
(i,j)
(i,j)上的排序得分,
m
i
,
j
m_{i,j}
mi,j表示如果
(
i
,
j
)
(i,j)
(i,j)属于某一实例。
实验
实验中主要针对以下三点进行分析。
平衡参数
这里涉及的是两个分支对模型的影响实验。将
λ
\lambda
λ的值设置为[0.2,0.25,0.33,0.5,0.75,1.0],实验表明
λ
=
0.25
\lambda=0.25
λ=0.25效果最佳。
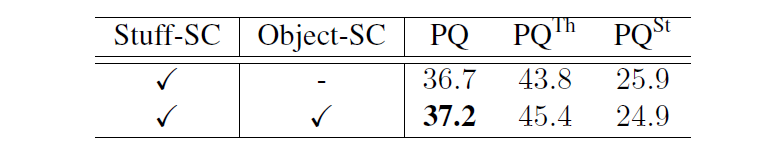
Stuff分支中的对象上下文
这里是指在Stuff分支中虽然仅仅想要获得背景信息分割结果,但是如果使用了对象分割信息也会提升模型性能,提升了0.5.
两支路的共享模式
对比shadow share model和deep share model特征图,得到的结果是:
空间排序模块
文中还对比了是否使用空间排序模块对模型的性能:

最后在COCO 2018 panoptic segmentation challenge中的表现如下:

参考文章:
1. 旷视研究院提出用于全景分割的端到端闭环网络OANet
2.Panoptic Segmentation
3.论文阅读理解 - Panoptic Segmentation 全景分割















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









