









- 上一篇:
编码 - ASCII、Unicode(utf-8) - https://blog.csdn.net/LawssssCat/article/details/103404269- 资料:
- Emoji Unicode Tables - https://apps.timwhitlock.info/emoji/tables/unicode
- 参考:
- ⭐️ 特殊字符(包括emoji)梳理和UTF8编码解码原理 - https://www.jianshu.com/p/57c27d67a8a8
- 千千秀字 - emoji(绘文字) - https://www.qqxiuzi.cn/zh/emoji.html
- Emoji 识别与过滤 - https://www.jianshu.com/p/42fd6f84c27a
- 黎清海 - 简书
- 深入理解Emoji(一) —— 字符集,字符集编码 - https://www.jianshu.com/p/8d675a5b9e5c
- 深入理解Emoji(二) —— 字节序和BOM - https://www.jianshu.com/p/ca191d9bdcc0
- 深入理解Emoji(三) —— Emoji详解 - https://www.jianshu.com/p/32a95a4fc542
- 相关:
- Emoji Frequency - https://home.unicode.org/emoji/emoji-frequency/
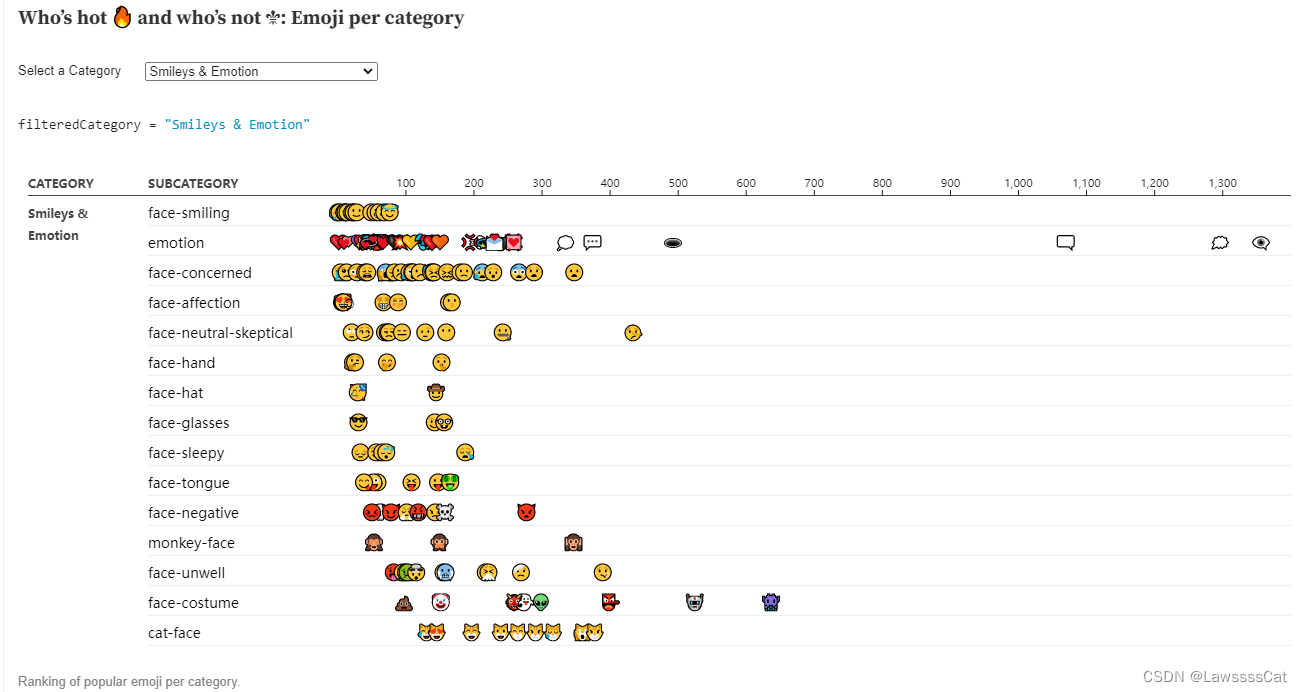

识别和过滤 emoji 字符前,先来了解 emoji 字符。
像下面这种字符,是本文要讨论的 emoji (绘文字)字符:
😄😊😃😍😉
Emoji 绘文字(日语:絵文字/えもじ emoji)不是图片,每个emoji都像文字一样拥有独立编码并且可以存放于字库中,所以可以理解其为图形文字,实际使用中也是和文字一样的使用,可以复制粘贴和输入。
Emoji 是 Unicode 的一部分,它在 Unicode 中有对应的码点( CodePoint),也就是说,Emoji 符号就是一个 Unicode 字符。
常见的Emoji表情符号在Unicode字符集中的范围和具体的字节映射关系
可通过 Emoji Unicode Tables 查看到:https://apps.timwhitlock.info/emoji/tables/unicode#block-6c-other-additional-symbols
注:本篇文章在不同平台下观看效果会不一样
Emoji 码点
Unicode 组织的 Unicode® Emoji Charts v11.0 页面中可以找到完整的 Emoji 码点数据: emoji-data.txt
通过 脚本 getEmojiData.sh 处理 ,可以得到一个 完整的的码表
#! /bin/bash
cat "$1" | sed -n -e '/^#/d' -e '/^$/d' -e 's/[ ]*;.*$//p' | sort -u
$ ./getEmojiData.sh emoji-data.txt > emoji-all-data.txt
Emoji 在 Unicode 编码中的位置
- emoji列表 - https://www.qqxiuzi.cn/zh/emoji.html
在 Unicode 编码中,emoji主要安排在 1号平面第241行至第247行(1F000-1F6FF),以及 0号平面第39行和40行(2600-27FF)等位置
- 2010年10月发布的Unicode 6.0版首次收录绘文字编码,其中582个绘文字符号,66个已在其他位置编码,保留作兼容用途的绘文字符号。
- 在Unicode 9.0 用22区块中共计1,126个字符表示绘文字,其中:
- 1,085个是独立绘文字字符;
- 26个是用来显示旗帜的区域指示符号;
- 以及 12 个(#, * and 0-9)键帽符号;
- 杂项符号及图形768个字符中有637是绘文字;
- 增补符号及图形82个字符中有80个是绘文字;
- 所有80个表情符号都是绘文字;
- 交通及地图符号103个字符中有92个是绘文字;
- 杂项符号256个字符中有80个是绘文字;
- 装饰符号192个字符中有33个是绘文字。
Emoji 字符长度
在 上一篇 文章提到,像 java、js 这些常用的编成语言是以 utf-16 来处理字符编码的。
于是,获取字符长度的时候,其实是根据 16位(2字节) 作为一个编码单元来分割字符串长度的。
于是,我们会看到下面的情况:(明明只有一个字符,长度却不为一的情况)
// javascript
"😀".length // 2
"🇨🇳".length // 4
"👩🏽🦳".length // 7
"👨👩👧👧".length // 11
可是,长度为 2 编码单元 可以理解为 码点 在 辅助平面 上,但 4、7、11 怎么理解?
这就涉及到Unicode的一个很重要的特性:组合字符
组合字符、字位簇
组合字符
Unicode 包含一个系统,可以合并多个编码点,动态组合字符。此系统用各种方式增加灵活性,而不引起编码点的巨大组合膨胀。
例如:
带重音的字符 “Á” 会被表示成由两个编码点组成的字符串:U+0041 “A” 拉丁大写字母 a 加上 U+0301 “◌́”组合尖音符号。这个字符串自动被渲染成单个字符:“Á”。
字位簇
如上所见,Unicode 包含多种情况,用户认为的一个“字符” 事实上底下可能由多个编码点组成。Unicode 使用「字位簇」的概念来表示这种情况。一个由一个或多个编码点组成的字符串构成一个 “用户感知的字符”。
UAX #29 为字位丛定义了精确的规则。
字位簇主要被用在文本编辑:
- 它们对光标和文本选择来说是最明显的单元;
- 使用字位簇,确保在复制和粘贴文本时不会突然丢掉一些符号;
- 同时左右方向键也总是以一个可见字符的距离移动;
- 等等
组合规则
现在,我们知道了一个Emoji表情可能由多个码点组成,这些码点都遵循着一定的规则来组合成不同的 Emoji 表情,我们来看下几种常见的规则:
-
单Unicode
最基本的Emoji表情,码点位于辅助平面上。在UTF-16下通过String.length()会被判断为2个长度,可以使用String.codePoints()通过码点数来获取正确的长度。
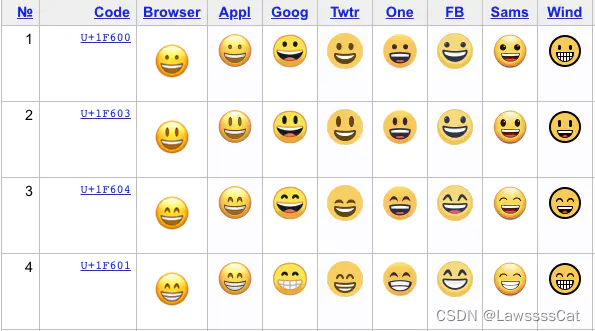
String.fromCodePoint(parseInt("1F600", 16)) // '😀' -
双Unicode
最具代表性的就是旗帜序列(Flag Sequence),这类 Emoji 串是通过两个地域指示符(regional_indicator)组合的方式来表示一个国家的国旗。
总共有 26 个地域指示符(U+1F1E6~U+1F1FF),每个指示符又对应于一个英文字母含义,例如 U+1F1E8 为地域指示符 C, U+1F1F3 为地域指示符 N。这些指示符两两组合表示一个国旗CN即中国国旗(🇨🇳)在不支持Emoji5.0的系统上,会被显示为两个字母Emoji表情(🇨 🇳)。并不是 26 x 26 种组合是全部合法的,合法的 Flag Sequence 只有 256 种。

String.fromCodePoint(parseInt("1F1E8", 16), parseInt("1F1F3", 16)) // '🇨🇳' -
变量选择器
在众多 Emoji 中, 有一些特殊的 Emoji 并没有显示的样式, 只是起到了控制的作用。这些控制型的 Emoji 与基础 Emoji 出现在一起, 可以展示更多的样式。比如 变量选择器:- 变量选择器 - 15 (VARIATION SELECTOR-15, 简写 VS-15):
<U+FE0E>, 作用是让基础 Emoji 变成更接近文本样式 (text-style); - 变量选择器 - 16 (VARIATION SELECTOR-16, 简写 VS-16):
<U+FE0F>, 作用则是让基础 Emoji 变成更接近Emoji 样式 (emoji-style).
VS-15 和 VS-16 加在基础 Emoji 字符的后面, 可以起到控制作用 (前提是必须系统支持, 否则会被忽略)。
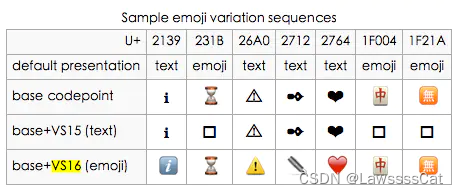
String.fromCodePoint(parseInt("26A0", 16)); // '⚠' '⚠'.length // 1 String.fromCodePoint(parseInt("26A0", 16), parseInt("FE0E", 16)); // 更接近文本样式 (text-style) // '⚠︎' '⚠︎'.length // 2 '⚠' == '⚠︎' // false String.fromCodePoint(parseInt("26A0", 16), parseInt("FE0F", 16)); // 更接近Emoji 样式 (emoji-style). // '⚠️'而在 VS-16 的基础上,还有一种 键帽序列 (KeyCap Sequence),这类 emoji 序列是将数字
(0-9),*与#通过一个U+20E3字符转换为键帽的样式。由于这种样式要求必须以 emoji 风格展示,所有会在序列中添加样式限制U+FE0F。例如U+0023 U+FE0F U+20E3的 emoji 样式即是 #️⃣,U+0030 U+FE0F U+20E3的 emoji 样式即是 0️⃣。其它与此类似。String.fromCodePoint(parseInt("0023", 16)); // '#' String.fromCodePoint(parseInt("0023", 16), parseInt("FE0F", 16)); // '#️' String.fromCodePoint(parseInt("0023", 16), parseInt("FE0F", 16), parseInt("20E3", 16)); // '#️⃣'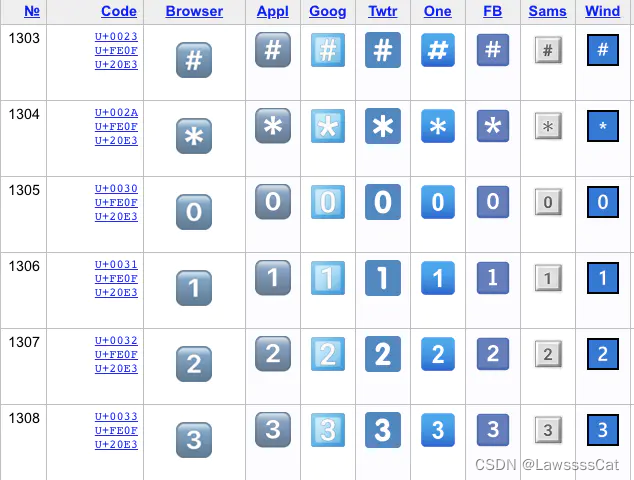
另外, 还有一些控制型的 Emoji, 可以对人体肤色进行改变,改变对象仅限于 “表示人身体部位的Emoji”。
目前定义了五种修饰字符,分别表示颜色的由浅及深,它们分别是:U+1F3FB ~ U+1F3FF(🏻…🏿) 共五个, 分别简称为:- FITZ-1-2
- FITZ-3
- FITZ-4
- FITZ-5
- FITZ-6
例如,
U+270D(✍️) 就是一个可以被修饰的 emoji 字符,那么它被U+1F3FF修饰后就会变成U+270D U+1F3FF(✍️🏿)。var colors = ['1F3FB', '1F3FC', '1F3FD', '1F3FE', '1F3FF'] for(var i=0; i<colors.length; i++) { var color = colors[i] var c = String.fromCodePoint(parseInt("270D", 16), parseInt(color, 16)); console.log(c) } // ✍🏻 // ✍🏼 // ✍🏽 // ✍🏾 // ✍🏿 - 变量选择器 - 15 (VARIATION SELECTOR-15, 简写 VS-15):
-
无缝连接序列
上面说到,通过一些特定的Emoji组合,可以结合出不同肤色的表情
性别,职业,等也可以结合
这种特殊不可见的排列方式被称为 “无缝连接” (“Zero-width joiner,即ZWJ”)
U+200D便是连接这些表情的字符
例如:U+1F468 U+200D U+1F469 U+200D U+1F467(👨👩👧) 这个 emoji 表示家庭即由三个emoji字符经 ZWJ 连接而成的:U+1F468(👨)U+1F469(👩)U+1F467(👧)
当然不局限于家庭人物,包括职业,运动等许多都是用这种方式组成的



Emoji的碎片化 💣
上述的 组合字符 提供非常便利的方案来快速的扩充 emoji 字符的丰富度。Emoji表情和ZWJ字符串不需要标准码协会批准就可以建立并在自有平台上使用 (不需要耗一个月甚至一年的时间等候审批,使表情开发变得更快)。即使在不支持ZWJ的老版本中,最多也是显示两个或是两个以上独立的表情,添加新的代码不会破坏其他或是出现丑陋的问号块。
标准码协会利用ZWJ字符序列的方式(可以跨多平台使用),使得各IT公司可以轻易地进行开发,不过同时也有个明显的问题。
苹果或是谷歌可以自主添加标志或解决问题,而不会影响与其他平台的兼容。这也使以ZWJ序列排列出的表现被跨平台支持,但事实上却没能被支持:
- 各个平台都在开发属于自己的表情,会导致不同平台间的符号不兼容,比如字符长度的问题,在IOS系统上,一个Emoji表情发送到Android手机上,可能会出现4、5个,如果在有长度限制的条件下,便可能会出现截断的问题;
- 标准码协会提供所有表情符号的名称和简单的图片,但任何Emoji文章展示,你通过手机和电脑看起来也有轻微的区别;
(不同的操作系统和程序开发者都想通过不同的emoji表情来达到更美观,而不是用统一的通用字符集。)
上述的问题导致了Emoji的混乱,这点其实跟Unicode的“统一”多多少少是有点冲突的。但不管怎么说,Emoji都是一个非常伟大且成功的发明。
Emoji 的识别
识别 Emoji 问题在于划定其编码范围。但经过上面的描述我们知道,Emoji 的编码其实也是零散的(组合字符的使用导致任何一个普通字符都可能发展成 emoji 字符)
如何确定 Emoji 的编码范围?
可以查看官网给出的码点范围:http://www.unicode.org/charts/
相对应的,下面是识别 emoji 的 utf-16 编码正则表达式:
(\u00a9|\u00ae|[\u2000-\u3300]|\ud83c[\ud000-\udfff]|\ud83d[\ud000-\udfff]|\ud83e[\ud000-\udfff])
https://ihateregex.io/expr/emoji/



















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











