






 本文介绍了决策树算法的基本原理,包括信息熵、条件熵、信息增益和基尼值的概念,以及ID3、C4.5和CART决策树的选择准则和改进。C4.5通过增益率平衡属性取值数量的影响,而CART则选择基尼指数最小的属性进行划分。
本文介绍了决策树算法的基本原理,包括信息熵、条件熵、信息增益和基尼值的概念,以及ID3、C4.5和CART决策树的选择准则和改进。C4.5通过增益率平衡属性取值数量的影响,而CART则选择基尼指数最小的属性进行划分。
决策树
1.算法原理
从逻辑角度看是许多if、else组合。
从几何角度看是按照某种准则对于特征空间进行划分。
目的是通过划分取得“纯度”更高,即在一个划分区域内通过信息熵得出的随机变量不确定性程度更低的结果。
2.定义
自信息:
当b=2时单位为bit,当b=e时单位为nat。
信息熵(自信息的期望):
度量随机变量的不确定性,信息熵越大越不确定
(离散型)
计算信息熵时约定:若,则
。当
的某个取值的概率为1时信息熵最小(最确定),其值为0;当
的各个取值的概率均等时信息熵最大(最不确定),其值为
,其中
表示
可能取值的个数。
将样本类别标记视作随机变量,各个类别在样本集合
中的占比
视作各个类别取值的概率,则样本集合
(随机变量
)的信息熵(底数
取2)为
显然,此时的信息熵所代表的“不确定性”可以转换理解为集合内样本的“纯度”
条件熵(Y的信息熵关于概率分布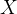 的期望):
的期望):
在已知后
的不确定性
从单个属性(特征)的角度来看,假设其可能取值为{
},
表示属性
取值为
{
}的样本集合,
表示占比,那么在已知属性
的取值后,样本集合
的条件熵为
信息增益:
在已知属性(特征)的取值后
的不确定性减少的量,也即纯度的提升
即信息熵与条件熵的差值。
基尼值:
从样本集合中随机抽取两个样本,其类别标记不一致的频率。
因此,基尼值越小,碰到异类的概率就越小,纯度就越高。
属性 的基尼指数(类比信息熵和条件熵):
的基尼指数(类比信息熵和条件熵):
3.ID3决策树
ID3决策树是以信息增益为准则来选择划分属性的决策树
每次在众多条件中选最优(信息增益最大的条件),经过循环反复迭代,即为ID3决策树最终结果。
4.C4.5决策树
C4.5决策树是在ID3决策树基础上的一种改进
因为ID3决策树基于信息增益准则所以对可能取值数目较多的属性有所偏好,这种偏好可能带来不利影响。
比如,有三名学生,编号为01,02,03,很显然按照编号进行划分时信息增益率很高。这时ID3决策树会更倾向于选择编号作为条件,但其本质原因不是取值数目过多,而是每个取值内包含的样本量太少。
为减少这种偏好的不利影响,C4.5决策树使用了“增益率”代替“信息增益”,并且对增益率定义为:
其中
称为属性的“固有值”,
的可能取值个数
越大,通常其固有值
也越大。可见
可以平衡可能取值数目较多的属性的信息增益。
但是,的可能取值个数
越小,通常其固有值
也越小,增益率
的值就越大。导致增益率对可能取值数目较少的属性有所偏好。
因此,实际使用中C4.5决策树通常采用一种启发式的方法:不用“增益率”完全取代“信息增益”,而是先选出信息增益高于平均水平的属性,再从中选出增益率最高的。
5.CART决策树
CART决策树简单地说就是选择基尼指数最小的属性作为最优化分属性
CART决策树实际构造如下:
首先,对每个属性的每个可能取值
,将数据集
分为
和
两部分来计算基尼指数,即
然后,选择基尼指数最小的的属性及其对应取值作为最优划分属性和最优划分点
最后,重复上述步骤,直至纯度满足停止条件。















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









