






一、机器学习三观:what、why、how
what:什么是机器学习?
机器学习是研究关于“学习算法”(一类能从数据中得出其背后潜在规律的算法)的一类学科
why:为什么要学习机器学习
从事机器学习理论的研究、系统的开发,将其中算法迁移到自己从事的研究领域,从事AI研究
how:怎样学机器学习?
本书只涉及基础的理论研究内容。当前机器学习尚处于工程领先理论阶段,还有很多的未解之谜。
二、基本术语
样本(sample):也称为“示例(instance)”,是关于是个事件或对象的描述。
一般来说,带有标记的称为样本,不带标记的称为示例
eg:一个“色泽青绿、根蒂蜷缩、敲声清脆”的西瓜可用向量表示为:
x = (青绿;蜷缩;清脆)
向量中的各个维度称为“特征(feature)”或“属性(attribute)”,比如例子中的“色泽、根蒂、敲声”
属性上的取值,称为“属性值(attribute value)”,比如例子中的“青绿;蜷缩;清脆”
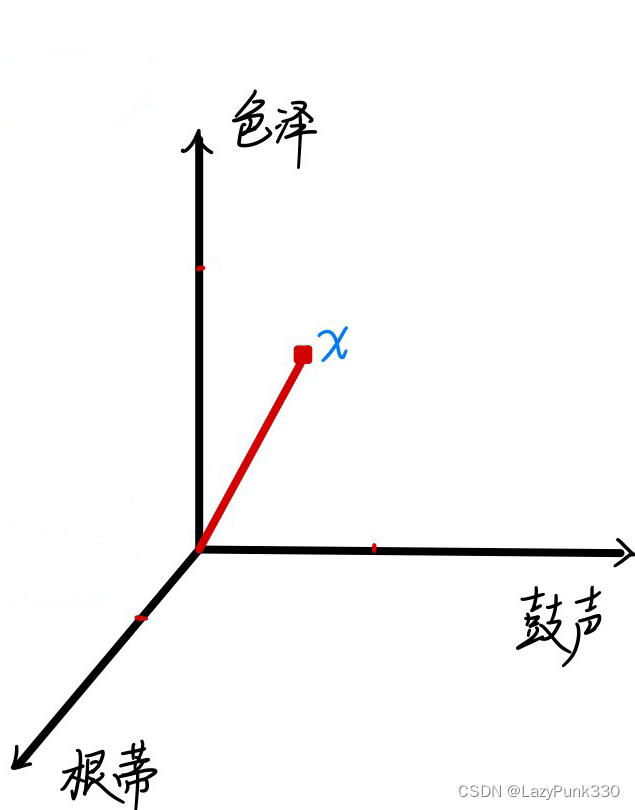
属性张成的空间称为“属性空间(attribute space)”、“样本空间(sample space)”或“输入空间”,用花式大写X表示
如图1,以“色泽”、“根蒂”、“敲声”为坐标轴张成一个用于描述西瓜的三维空间,每个西瓜都能在空间中找到自己的坐标位置。
由于空间中的每个点对应一个坐标向量,因此我们也把一个势力称为一个“特征向量(feature vector)”
向量中的元素用分号“;”分隔时表示此向量为列向量,用逗号“,”分隔时表示为行向量。
特征工程:将属性值按一定的规则变为计算机可识别的数字
标记(label):机器学习的本质就是在学习样本在某个方面的表现是否存在潜在的规律,该方面的信息称为“标记”
标记通常也看做样本的一部分,因此,一个完整的样本通常表示为(x,y)
eg:一个西瓜样本:x = (青绿;蜷缩;清脆),y = 好瓜
标记空间(label space):类比样本空间,标记所在的空间,也称“输出空间”,用花式大写Y表示
根据标记的取值类型不同,可将机器的学习任务分为两种:
分类(classification):标记取离散值,比如一颗瓜为好瓜或坏瓜。涉及多个类别时称为“多分类(multi-class classification)”任务,研究多分类问题时通常将其分解为二分类问题。分类只涉及两个类别是称为“二分类(binary classification)”任务,通常称其中一个为“正类(positive class)”另一个为“反类(negative class)”,正反类的划分不固定可以互相交换,通常记正类为1,反类为0,即Y= {0,1}
回归(regression):标记取连续值,例如一颗西瓜的成熟度0.95、0.37。由于是连续型,因此标记的所有可能无法直接罗列,通常只有取值范围,回归任务的取值范围通常是整个实数域R,即Y = R
三、假设空间和版本空间
将学习过程看作是一个在所有假设组成的空间中进行搜索的过程,搜索的目的是找到与训练集“匹配(fit)”的假设。假设的表示一旦确定,假设空间及其规模大小就确定了。通过多种策略对这个假设空间进行搜索,如自上而下、从一般到特殊或是反其道而行之,搜索过程中不断删除与正例不一致的假设、和(或)与反例一致的假设,最终获得与训练及一致(及对所有训练样本都能正确判断)的假设,即为学得结果。
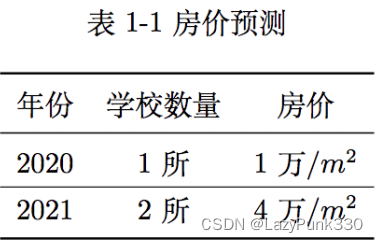
例子:假设现已收集到某地区近⼏年的房价和学校数量数据,希望利⽤收集到的数 据训练出能通过学校数量预测房价的模型,具体收集到的数据如下表所示:
四、归纳偏好(inductive bias)
机器学习算法在学习的过程中对某种类型假设的偏好,称为“归纳偏好”或简称为“偏好”
为了防止机器学习算法被假设空间中在训练集上看似“等效”的假设迷惑,而无法产生确定的学习结果,任何一个有效的机器学习算法必有其偏好。
有没有一种一般性原则人引导算法确立“正确的”偏好?
奥卡姆剃刀(Occam's razor)——若有多个假设与观察一致,则选最简单的那个
如非必要,勿添实体
但是运用奥卡姆剃刀原则是应注意对于“简单”的定义并不简单,往往需要借助其他机制来解决对于“简单”的定义问题。
事实上,算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法是否能取得好的性能。
NFL(No Free Lunch)定理:一个算法A在某些问题上比另一个算法B好,则比存在另一些问题B比A好。
如果我们精心设计的算法与随便乱猜的算法数学期望一致,那么我们的学习算法是无意义的吗?
当然不是,NFL定理的重要前提是所有问题出现的机会相等、或所有问题同等重要。但实际上我们关注的只有自己在解决的问题。
那么NFL定理的意义是什么呢?其实它最重要的寓意是脱离具体问题,空泛的谈论“什么算法更好”毫无意义。——具体问题,具体分析















 3313
3313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









