







由于之前做的东西偏计算机视觉方向,也对机器学习有了一定的认识,但是并没有形成一个系统的知识架构,因此决定看看吴恩达(Andrew NG)老师的斯坦福机器学习公开课。这个公开课对于机器学习领域的人来说应该是无人不晓,应该也是入门必备吧,我可能会挑选其中的部分进行观看,并进行相关记录,写出一些自己的感悟,以便后面复习起来方便查阅。
1.监督学习(supervised learning)
众所周知,机器学习的问题可以大致分成三类:1.监督学习。2.半监督学习。3.无监督学习。其中监督与无监督的区别在于输入的训练数据是否有标签。
比如我需要训练一个图片分类器,输入一张图片,输出这张图片中的目标是猫、狗、马等等,那么在训练这个分类器的时候,如果你的训练数据是猫的图片+猫这个标签,狗的图片+狗的标签,马的图片+马的标签这样的成对数据,那么就是监督学习(可以通过分类器输出与真实标签的误差来驱动模型参数的更新);如果训练数据包含图片,以及相应的一些弱的标签,则是半监督学习;如果训练数据只有图片,则是无监督学习(通过聚类等方法来做)。
而本节主要介绍的是监督学习的训练方法。
2.损失函数(loss function)
对于监督学习来说,模型的更新/训练,就是通过模型实际输出与理想输出的误差来更新权重,而损失函数就是这个误差的某种函数表示。一般损失函数由损失项和正则项构成,损失项计算误差,正则项对参数进行约束,而NG这堂课的话损失函数只包含损失项,我们后面也只考虑损失项。
下面介绍下符号:
(x,y)为训练样本对,x是输入变量, y是理想输出(标签), 总共有m个样本。则系统的实际输出为: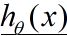
我们采用最简单的均方误差作为损失函数:
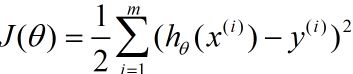
可以看出就是理想输出与实际输出差值的函数。
注意:x的上标(i)表示第i个样本,下标i则表示第i类输入变量/特征变量(因为系统的输入可能有多个因素)
所以训练模型的目标为:改变参数theta的值,最小化目标函数J(theta),而我们接下来就是要求这个函数的最优化。
3.梯度下降(gradient descent)
对于上面得到的目标函数,我们训练的过程就是:首先初始化参数theta=theta0;然后最小化目标函数J,改变theta值,直到收敛。而梯度下降法则是最常见求解方法,即:每次选择目标函数对参数theta求偏导,即得到梯度方向,然后按照负梯度方向来更新参数,最终最小化目标函数,得到参数的最优值。公式如下:
首先计算梯度:
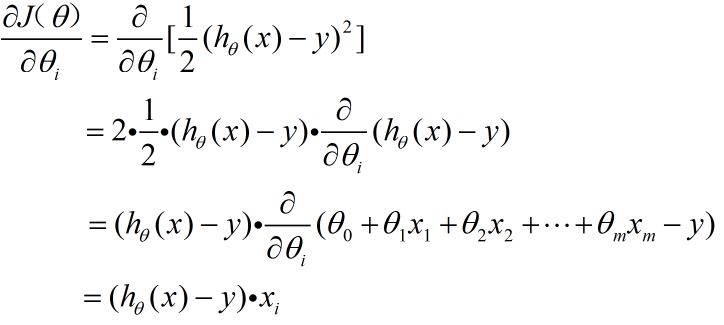
然后更新权重/参数:
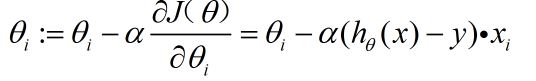
为什么要选负梯度方向呢,因为梯度方向是函数变化最快的方向,而负梯度则是下降最快的方向。其中alpha是学习率。
这里加上几点注意事项
(1) 梯度下降法并不一定的到全局最优,是有可能得到局部最优的。
(2) 初始权重选择不同,梯度下降得到的结果也不一定相同。
(3) 在刚开始时,梯度值可能会很大,下降会很快,但当接近局部极小时,梯度值会变得非常小,每次下降的距离也很小。
3.1 批量梯度下降(batch gradient descent)
上面的到梯度下降的一般公式,是针对一个样本xi的结果,而我们在实景应用中,往往是采用全部的样本来计算权重更新的,因此引入了批量梯度下降的概念。即,每次计算梯度更新权重的时候,将全部样本都纳入计算,如下图所示:
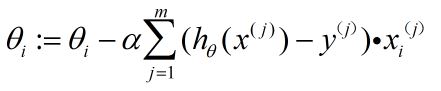
每次更新权重计算所有样本的误差梯度,这样的做法会很明显的导致计算量大,耗时耗力,因此下一节又引入了随机梯度下降的概念。
3.2 随机梯度下降(stochastic gradient descent)
随机梯度下降,即每次梯度更新时只计算一个样本的梯度,公式如下:
for j=1 to m{
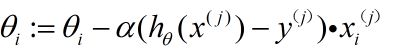
}
这样的不同是,收敛可能会比较慢,并且是曲折的到达极小值点。
最后调整下之前的学习计划:编程C,C++,Python是首要的;接下来就是caffe这个框架要好好学;再就是目标检测目标跟踪的一些知识。
另markdown真的很好用,排版好的很多,神器。
文中难免存在疏漏,欢迎拍砖















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









