







项目详细讲解
锦鲤日续订活动:
1、网关转发请求后,对入参RSA验签
2、在业务处理器初始化后,把中移动传过来的业务类型参数注入到处理器的属性,然后实现处理器做业务逻辑处理,远程调用用户模块、协议模块暴露的查询服务RPC接口、对用户的uid进行续订资格校验查询,将第三方通知处理结果返回给网关
3、跳转续订页面,小程序后端调用核心模块,如果是续订场景,做业务逻辑处理,续订同步任务记录先初始化入库,更新任务状态为代执行,选择对应的topic,给自己发MQ消息,消费成功时,将同步消息记录表入库,同时调用渠道模块,组装同步信息,走出口网关,同步给中移动发送请求,信息同步给中移
付款模块:
4.1 钱包模块接收到扣款消息,先发送扣款成功半消息
4.2 钱包模块执行本地事务,模拟支付,更新钱包信息,插入扣款流水
4.3 回查逻辑为:查询本地是否存在扣款流水,不存在则回滚事务消息
4.4 订单模块接收到事务消息后,开始更新本地订单状态。此处通过乐观锁保证幂等
避免超发
1、从redis查询库存数量,判断余量
2、@Compensable注解在Try方法,锁定库存改库存TCC状态为TCC处理中;插入用户抽奖记录;调用领券中心发放奖品
3、Confirm阶段:发放成功后,更新中奖记录为TCC处理完成;执行Confirm方法,扣减库存,并解锁,更新抽奖记录
4、Cancel阶段:如果库存和抽奖记录异常,则解锁库存
TCC解决分布式事务
TCC-Transaction框架的核心注解:@Compensable
@Compensable(confirmMethod = "confirmMethod", cancelMethod = "cancelMethod",asyncConfirm = true,
asyncCancel = true,transactionContextEditor = MethodTransactionContextEditor.class)
核心逻辑是通过两个切面CompensableTransactionAspect、ResourceCoordinatorAspect 实现的。
CompensableTransactionAspect:通过@Around为业务方法添加环绕增强。
ResourceCoordinatorAspect:通过设置order等级,来事务的参与者,Order中的值越小,优先级越高
业务解析:
1、Try:生成订单,给订单一个初始状态:pending;预操作,库存状态改为冻结。其中夹杂其他业务逻辑,如库存校验等
2、Confirm:更新订单状态,扣减库存,发放积分
3、Cancel:更新订单状态取消,还原库存,移除预发积分
- 本地消息表:有后台任务定时去查看未完成的消息,然后调用对应的服务,当一个消息多次调用都失败的时候可以记录下然后引入人工,或者直接舍弃
- 事务消息:当半消息被commit了之后确实就是普通消息了,如果订阅者一直不消费或者一直重试,最后进入死信队列
中间件
RocketMq
消息系统的特点:
异步、解耦、削峰填谷、并行 进程级别/线程级别、最终一致
系统解耦:在订单支付成功后,需要更新订单状态、更新用户积分、通知商家有新订单、更新推荐系统中的用户画像
引入 MQ 后,订单支付现在只需要关注它最重要的流程:更新订单状态即可
异步通信:
MQ 把、缴费、开卡、协议签约、权益发放变成了异步执行,能减少开通会员的整体耗时,提升订单系统吞吐量
流量削峰:
MQ 作为 “漏斗” 进行限流保护,然后异步将
消息的延时消费:
利用队列本身的顺序性,来满足消息必须按顺序投递的场景;利用队列 + 定时任务来实现消息的延时消费
基础架构
NameServer:RocketMQ的注册中心,集群的Topic-Queue的路由配置;Broker的实时配置信息
Broker:核心模块,负责接收并存储消息,同时提供Push/Pull接口来将消息发送给consumer。Consumer可选择从Master或者Slave读取数据。多个主/从组成Broker集群,集群内的Master节点之间不做数据交互。Broker同时提供消息查询的功能,可以通过MessageID和messageKey来查询消息。Borker会将自己的topic配置信息实时同步到nameserv。
Producer 消息的发送端,Producer通过NameServ获取所有broker的路由信息,根据负载均衡策略选择将消息发到哪个broker,然后调用broker接口提交消息。
Consumer 消息的消费端,Consumer通过向broker发送Pull请求来获取消息数据。如果consumer在请求时没有数据,Broker可以将请求暂时hold住不返回,等待新消息来的时候再回复,这就是Push模式。Consumer可以以两种模式启动,广播(Broadcast)和集群(Cluster),广播模式下,一条消息会发送给所有consumer,集群模式下消息只会发送给一个consumer
Message结构
* @param topic 消息主题, 最长不超过255个字符; 由a-z, A-Z, 0-9, 以及中划线"-"和下划线"_"构成.
* @param tag 消息标签, 请使用合法标识符, 尽量简短且见名知意
* @param key 业务主键
* @param body 消息体, 消息体长度默认不超过4M, 具体请参阅集群部署文档描述.
Message类型
- 半消息:1.生产者发送【半消息】 2.(生产者)本地监听【半消息】处理结果 3.(消费者)处理-【半消息】
- 普通消息:topic 消息主题、tag 消息标签、key 业务主键、body 消息体
- 延时消息:RocketMQ将消息以SCHEDULE_TOPIC_XXXX为topic将延时消息持久化,定时器轮训,到时间后恢复原有的topic
msg.setStartDeliverTime(delayTime);
- 死信消息:RocketMQ会对RECONSUME_LATER状态的消息进行重新推送,默认16次,再失败进入死信队列,等待人工干预
重试机制
- 生产端重试:发送端没有收到Broker的ACK,DefaultMQProducer可以设置消息发送失败的最大重试次数
- 消费端重试:消费消息后,需要给Broker返回消费状态,ConsumeConcurrentlyStatus*//消费成功*,RECONSUME_LATER;//消费失败,一段时间后重试
MQ高可用
Producer:发送有三种方式:同步,异步,单向(Oneway)
双主双从架构,NameServer多节点,同步双写,异步刷盘,改同步刷盘可靠性更高,消息持续化到磁盘
消息重复消费
RocketMq不解决消息重复消费问题,影响消息系统的吞吐量和高可用,靠业务逻辑来解决
1、消费端处理消息的业务逻辑保持幂等性,例如数据库记录消息的id确保唯一,没有就新增,有就修改
2、在发送消息时,给每条消息指定一个全局唯一的 ID。消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费,如果消费过,那么就不处理
消息丢失问题
1、开启分布式事务,保证producer消息发送给MQ,成功 commit 半消息,就可以消费
2、开启同步刷盘,mq消息持久化时,是先将消息写到内存,如果消息没异步刷盘,Broker宕机,也会丢失
3、消费者自带监听器,消费完消息后,返回CONSUME_SUCCESS,就消费成功,没返回其他消费组处理
消息重复消费
实际场景:放在同一个topic,和同一个tag下消费
改进:保证投递到同一queue
消息积压
修复consumer的问题,新建临时的topic,扩容节点
消息顺序发送
RocketMQ通过轮询随机/hash的MessageQueueSelector的所有队列的方式来确定消息被发送到哪一个队列(负载均衡策略)。比如订单号相同的消息会通过MessageQueueSelector被先后发送到同一个队列中,然后通过订单号确认是同一个队列
消息回溯
MQ事务消息
com.alibaba.rocketmq.example.transaction.TransactionProducer
直接基于 MQ 来实现事务,不再用本地的消息表。RocketMQ相比Kafka支持事务消息
1、发送方给 Broker 发送Prepared消息(半消息),发送成功后发送方再执行本地事务
2、根据本地事务的结果向 Broker 发送 Commit 或者 RollBack 命令,
3、RocketMQ 的发送方会提供一个反查事务状态接口,半消息没有收到任何操作请求,我们需要定义好事务反查接口,根据业务状态确定事务COMMIT, ROLLBACK, 还是继续 UNKNOW。如果是待确认就定时轮询重试
改进:
1、利用本地事务,在创建订单时,也新增事务表一条记录。此时不发消息。
2、同进程内有一单线程的线程池,不断查询事务表,查到事务记录,将事务记录,发送到mq中,传递给下游消息。
或者:用本地事务监听器检查mq消息,入库查询订单记录,判断是否回滚。
3、监听mq的回执,收到回执后删除本地事务表记录。
4、避免重复提交
两阶段提交、补偿事务、本地消息表、MQ 事务消息
Kafka
kafka的一个基本架构:多个broker组成,一个broker是一个节点;你创建一个topic,这个topic可以划分成多个partition,每个partition可以存在于不同的broker上面,每个partition存放一部分数据。kafka在0.8之后,每个partition的数据都会同步到其他机器上,所有的副本会选举一个leader出来
kafka性能高的原因
1、PageCache文件,页缓存优化I/O
2、零拷技术减少拷贝次数
3、批量量处理。合并小的请求,然后以流的方式进行交互
4、Pull 拉模式。使用拉模式进行消息的获取消费
- RocketMQ支持异步实时刷盘,同步刷盘,同步Replication,异步Replication
- Kafka使用异步刷盘方式,异步Replication
- RocketMQ的同步刷盘在单机可靠性上比Kafka更高,不会因为操作系统Crash,导致数据丢失
DUBBO
RPC和http区别
RPC要求适合同环境的远程调用,http不用关注实现,只需遵循rest规范
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全
结构:
business业务逻辑层、RPC配置层(负载均衡、集群容错、代理)、remoting 网络传输层
启动原理:
0、服务容器负责启动,加载,运行provider。
1、provider和consumer连接到注册中心register做注册,订阅服务
2、register根据配置的订阅关系,把provider提供的信息给consumer,同时consumer本地缓存信息
3、consumer根据负载均衡策略选择一台provider,向monitor返回调用次数和时间
4、consumer通过代理对象发起接口调用
5、provider对数据进行反序列化,实现接口
负载均衡算法
1、随机+权重(random)
在0—总权重之间选择选一个随机数,遍历找到第一个比随机数大的权重,选择对应的provider。如果权重相等,就随机选一个
2、轮询+权重
权重=当前权重+设定权重,调用服务后,invoker的可调用次数减1,实际权重减小。会导致服务最后都堆积在某一台慢机器
3、一致性Hash均衡算法
将provider的地址,32位递增hash在一个环上。一个机器160的节点,根据consumer入参来hash计算选择的节点
4、最少活跃调用数
客户端有计数器,记录请求未完成的数量,选择计数最少的机器+1,如果计数相同,根据随机+权重选择
5、最短响应
计数器*请求成功平均时间,选择最短结果的机器,否则就随机+权重,更加平滑
集群容错机制:
Failover Cluster失败自动切换、失败自动恢复、并行调用多个服务提供者、广播模式
Failback Cluster快速失败:在调用失败,记录日志和调用信息,然后返回空结果给consumer,并且通过定时任务每隔5秒对失败的调用进行重试
生产问题:线程池被打满。
dubbo版本号不同,服务相互间不引用
一次页面2.0改版,进行全链路压测,报RPC异常,ThreadPool is Exhausted。
连接到dubbo服务器,dubbo status -l列出状态,发现默认线程池200被占满,随后都改成1000,并进行链路优化
原因:dubbo请求超时针对客服端,服务端线程不会释放,根据默认重试机制,再次拿线程去处理
配置:
dubbo.zookeeper.address=zk-0:2181,zk-1:2181,zk-2:2181
dubbo.timeout=10000
dubbo.retries=1
zookeeper
ZooKeeper 是一个开源的分布式协调服务
保留了TCP版本的FastLeaderElection选举算法
1.服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
2.服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的myid大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
3.服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的myid最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
4.服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的myid大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
5.服务器5启动,后面的逻辑同服务器4成为小弟
第一台机器server1启动后,发现集群中还没有leader服务器,则向集群中发出leader选举,第一次先推荐自己,会将自己的sid和zxid和epoch发送出去,记作(epoch,sid,zxid)的形式为投票信息发送,其中epoch为一个逻辑时钟,标识leader选举的轮次,每一轮选举都会对epoch进行叠加(直接加1操作)。
由于目前集群中只启动了1台机器,所以server1无法得到集群半数以上的机器同意。所以此时的server1的状态为LOOKING状态。
第二台机器server2启动后,会也首先推荐自己为leader,并像server1的那样将(epoch,sid,zxid)的投票消息发送出去,在每台机器会有接受线程和发送线程来进行处理,这时server1会收到server2发出的推荐消息(epoch,sid,zxid),server1收到消息后和自己推荐的(此时server1推荐的是自己)进行判断,判断条件:
1、如果epoch的轮次比自己大,则更新推荐变更,将自己推荐的为这个最新的epoch的投票并向集群的其他机器发送出去。
2、如果epoch比自己写,则忽略,并坚持自己的投票,将投票信息发送出自己的投票信息到其他机器。
3、如果epoch相等,则判断zxid,如果zxid比自己大,则变更投票为这个收到的投票,并将变更后的投票发送给集群其他机器。
4、如果zxid比自己小,则坚持自己的投票,将投票信息发送给集群其他的机器。
5、如果zxid相等,则判断sid,如果sid比自己小,则坚持自己的投票,并将变更后的投票发送给集群其他的机器。
5、如果sid比自己大,则变更投票,并将变更后的投票发送到集群其他的机器上。
4、server1收到server2发送的投票信息后,判断后比自己大(先判断epoch,在判断zxid,最后判断sid,由于是首次启动,所以前面的spoch和zxid都是一样的,只有sid小),会变更投票为server2推荐的,server2推荐的是server2自己,所以这个时候server2会等到2票(server1和server2),已经超过半数以上,所以server2会成为leader。
5、当server3启动的时候,也会向集群中发送投票leader,由于前面已经有server2成为了leader,所以,server3的sid虽然是最大的,但是已经存在了leader,则不会再此进行选举,所以server3会成为follower。
6、server2由于故障挂掉后进行重新选举,选举和前面的算法是一样的,只是这个时候的zxid就不一定是一致的。
zk羊群效应
羊群效应常出现于通过zookeeper实现分布式锁的场景。
在加锁的时候,使用顺序临时节点
客户端创建节点,序号最小的获取锁
其他客户端监控最小节点,最小节点完成任务,发出通知,并释放
其他客户端获取通知后,获取所有节点,序号最小的获取锁,依此类推。
zk实现分布式锁
zk实现服务发现 zab
ZAB协议中主要有两种模式,第一是消息广播模式;第二是崩溃恢复模式
- 4.1. 客户端发起一个写操作请求
4.2. Leader服务器将客户端的request请求转化为事物proposql提案,同时为每个proposal分配一个全局唯一的ID,即ZXID。
4.3. leader服务器与每个follower之间都有一个队列,leader将消息发送到该队列
4.4. follower机器从队列中取出消息处理完(写入本地事物日志中)毕后,向leader服务器发送ACK确认。
4.5. leader服务器收到半数以上的follower的ACK后,即认为可以发送commit
4.6. leader向所有的follower服务器发送commit消息。
zk节点类型
持久节点、临时节点、持久顺序节点、临时顺序节点
临时和持久
MAVEN
Maven 是一个优秀的项目构建工具,依赖管理系统、
定位一个Maven工程
groupId:公司或组织域名倒序+项目名、artifactId:模块名、version:版本号
mvn compile :编译源代码
mvn clean package -Dmaven.test.skip=true :清除以前的包后重新打包,跳过测试类
项目部署流程:
1、rm -rf mopmweb 删除项目空间
2、从git clone master分支到机器
3、maven clean 后,不编译测试用例类deploy
docker
Docker是一个容器化平台,Docker镜像用于创建容器。使用build命令创建镜像。
docker push 将镜像推送至远程仓库
docker tag : 标记本地镜像,将其归入某一仓库
docker pull 拉取或者更新指定镜像
docker rm 删除容器
docker rmi 删除镜像
docker images 列出所有镜像
docker ps 列出所有容器状态
docker run xxx -d 后台运行 -p 端口映射 --name “xxx” 容器名称
git
常用命令
git branch 查看本地所有分支
git commit -am “init” 提交并且加注释
git clone git://github.com/schacon/grit.git 从服务器上将代码给拉下来
git pull 本地与服务器端同步
git push (远程仓库名) (分支名) 将本地分支推送到服务器上去
git fetch 相当于是从远程获取最新版本到本地,不会自动merge
git merge origin/dev 将分支dev与当前分支进行合并
git blame -L 38,38 查看代码每一行的提交信息
shell
//查端口占用
netstat -apn | grep 端口号
//查进程
ps -ef | grep 进程号
cpu详情 cat /proc/cpuinfo
docker rmi $(docker images -q)
$ docker ps -a *# 查看所有容器*
$ docker ps -a -q *# 查看所有容器ID*
docker exec -it containerID bash
K8S
进入到部署路径下
cd /data/marketing/mfbizweb/helm
helm del --purge mfbizweb-dev
helm install -n mfbizweb-dev ./mfbizweb --values ./mfbizweb/values.yaml --namespace gyjx-marketing --set image.tag=1.2.98.5 --set probe.enabled=false
自动化容器的部署和复制
K8s将集群中的机器划分为一个Master节点和一群工作节点Node
一、Master节点:Master指的是集群控制节点
apiserver:HTTP Rest接口的关键服务进程,是K8s做CRUD作的唯一入口
controller:管理所有资源
scheduler:Pod调度
二、Node:worker
Kubelet:创建管理Pod
proxy:对Pod节点进行负载均衡
Docker:创建容器
pod:
三、Pod
Pause容器:代表Pod容器状态
conainter:业务容器
普通的Pod一旦被创建,就会被放入到etcd中存储,确后会被KubernetesMaster调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的kubelet进程实例化成一组相关的Docker容器并启动起来
同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。
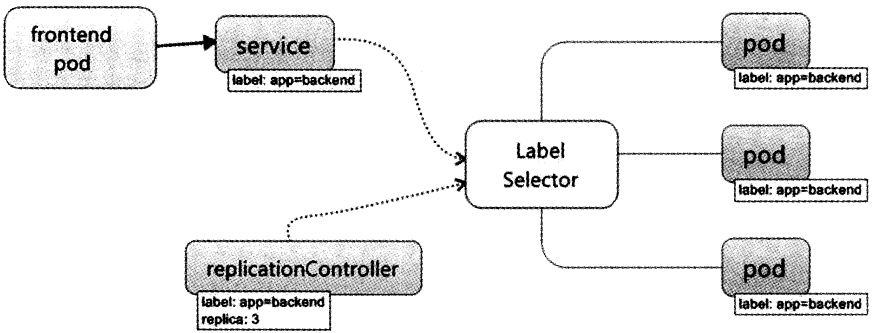
四、Lable
Lable类似Tag,可使用K8s专有的标签选择器(Label Selector)进行组合查询
五、Replication Controller
Pod副本数量的自动控制
六、Service
客服端访问k8s的对外服务端口,前端pod通过service定义的服务访问入口,经过LabelSelect选择对应的服务端Pod的业务容器,执行服务
LivenessProbe(存活探针)
存活探针主要作用是,用指定的方式进入容器检测容器中的应用是否正常运行,如果检测失败,则认为容器不健康,那么 Kubelet 将根据 Pod 中设置的 restartPolicy (重启策略)来判断,Pod 是否要进行重启操作,如果容器配置中没有配置livenessProbe存活探针,Kubelet 将认为存活探针探测一直为成功状态。
readinessProbe(就绪探针)
readinessProbe: 指示容器是否准备好服务请求。如果就绪探针失败,端点控制器将从Pod匹配的所有Service的端点中删除该pod的IP地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success。
**HTTPGet:**通过容器的IP地址、端口号及路径调用 HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器 健康。
mybatis
Mybatis的核心接口和类
MyBatis以一个SqlSessionFactory对象的实例为核心,根据XML配置文件或者Configuration类的实例构建该对象,SqlSession对象中完全包含以数据库为背景的所有执行SQL操作的方法。
每个线程都有自己的SqlSession实例,SqlSession实例不能被共享,也不是线程安全的。因此最佳的作用域范围是request作用域或者方法体作用域内。
缓存机制
一级缓存:也称为本地缓存,用于保存用户在一次会话过程中查询的结果,用户一次会话中只能使用一个sqlSession,一级缓存是自动开启的,不允许关闭。
二级缓存:也称为全局缓存,是mapper级别的缓存,是针对一个表的查结果的存储,可以共享给所有针对这张表的查询的用户。也就是说对于mapper级别的缓存不同的sqlsession是可以共享的。
#{}和${}
#{parameterName}引用参数,Mybatis会**把这个参数认为是一个字符串,并自动加上引号。
简单说**#{}是经过预编译的,是安全的**。可以将恶意参数当作占位符,防止sql注入
而**${}**是未经过预编译的,仅仅是取变量的值,是非安全的,存在SQL注入。
模糊查询Like,在sql语句中拼接通配符
mci_gy_id LIKE concat('%',#mciGyId#,'%')
shardingjdbc
1、配置datasource、连接池、双主库8从库
2、分片策略:标准分片策略、复合分片策略、行表达式分片策略、Hint分片策略、不分片策略
3、分片算法:精确分片算法(分片键 =与in)、范围分片算法(分片键 between and)、复合分片算法、Hint分片算法
分库分表策略、分片规则、精确分片算法
配置分片策略、分表规则
3、指定自增主键为user_id,不指定默认为雪花算法
负载均衡策略(两种):1.round_robin(默认)循环 2.RANDOM 随机
注意:数据分片+多主多从负载均衡方式由于涉及到数据分片,而逻辑SQ在改写过程中会生成多个物理SQL,shardingSphere采用异步执行得方式并行处理,故负载均衡维度在表级别,而不是数据库级别。
springcloud
SpringCloud隔离,限流,熔断,降级
eureka
服务注册实现
ribbon
HTTP和TCP的客户端负载均衡工具
调用负载均衡:
1、服务提供者只需要启动多个服务实例并注册到一个注册中心或是多个相关联的服务注册中心。
2、服务消费者直接通过调用被@LoadBalanced注解修饰过的RestTemplate来实现面向服务的接口调用。
hytrix
feign
feign+hystrix 在服务的消费方实现服务熔断
nacos
nacos采用的是客户端主动拉pull模型,应用长轮询(Long Polling)的方式来获取配置数据。
存储空间namespace、group、dataId
客户端数据结构
cacheMap是个Map结构,key为groupKey,是由dataId, group, tenant(租户)拼接的字符串;value为CacheData对象,每个dataId都会持有一个CacheData对象
















 2063
2063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









