









经典损失函数比较
1 平方误差损失函数
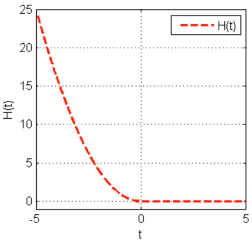
损失函数:
minJ(w)=1n∑i=1nH(yif(xi,w)),whereH(t)={t20t<0t≥0
分类实例:
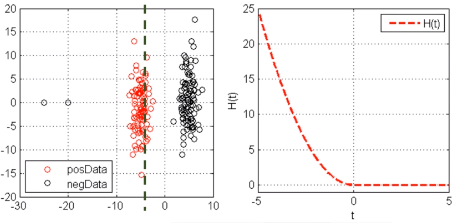
优点:容易优化(一阶导数连续)
缺点:对outlier点很敏感(因为惩罚是指数增长的,左图的两个outlier将分类面强行拉到左边,得不到最优的分类面)
2 感知机损失函数(L1 margin cost)
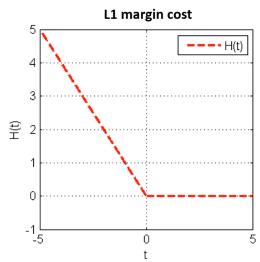
损失函数:
minJ(w)=1n∑i=1nH(yif(xi,w)),whereH(t)={−t0t<0t≥0
在 t=0 处不连续,所以不可导,但是可以求 次梯度(导数)。
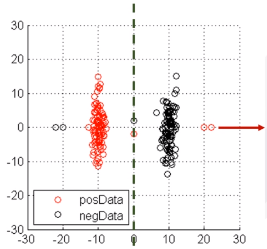
优点:稳定的分类面,次梯度可导
缺点:二阶不可导,有时候不存在唯一解
3 Logit损失函数(Logistic 回归)
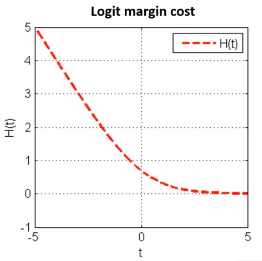
损失函数:
minJ(w)=1n∑i=1nH(yif(xi,w)),whereH(t)=ln(1+exp(−t))
优点:稳定的分类面,严格凸,且二阶导数连续
4 Hinge损失函数(SVM)
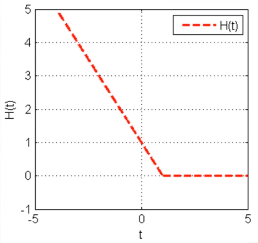
minJ(w)=1n∑i=1nH(yif(xi,w)),whereH(t)={−t+10t<1t≥0
优点:稳定的分类面,凸函数。对分对的但又不是很对的样本也进行惩罚(0-1之间),可以极大化分类间隔。
【问题】为什么不能用回归的损失函数来处理分类的问题
例子:
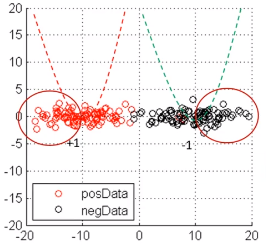
上例中,红圈中的样本是被正确分类了,但是回归损失函数还是会惩罚它们,而按照分类的观点是不应该惩罚的。
分类 != 回归
特例:1998年LeCun LeNet5 和 2016年的YOLO用回归解决分类问题,是因为它们的特征特别强。
5 两种正则化方法
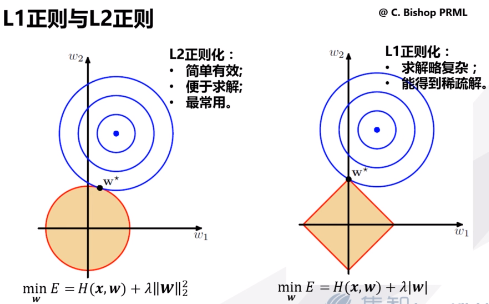
L1正则化假设了模型的先验概率分布服从拉普拉斯分布;L2正则化假设了模型的先验概率分布服从高斯分布。
【问题】什么样的损失函数是好的损失函数?
有明确的极大似然/后验概率解释,如果不满足,则满足以下几条:
minJ(w)=1n∑i=1nH(yif(xi,w))+Ω(w)
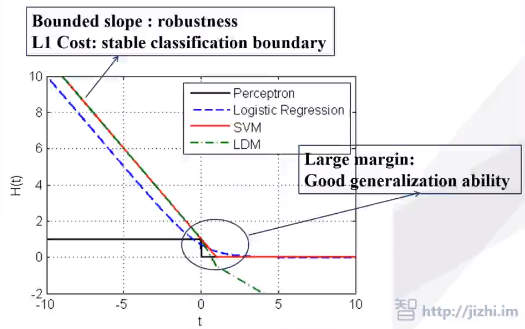
- H(t) 梯度需要有界,鲁棒性保障(反例:AdaBoost)
- 将L1作为H(t)的渐近线,稳定的分类边界(L1满足最小误分样本数)
- 大分类间隔,保障泛化性能
- 选择正确的正则化方式(一般默认L2)
Reference
1 次导数 次梯度 小结
http://blog.csdn.net/bitcarmanlee/article/details/51896348















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









