







在做语义分割实验的时候,因为我做的课题的数据集是私有医疗数据集,数据集的图片有很多公有数据集不具备的问题,一个是分辨率很高,最高的接近两万八千多两万多;另一个问题是图片的尺寸不一,小一点的图可能短边只有1440.因此这样的原图在预测阶段比较麻烦,在我总结一番之前的工作后,我在这里写了一个处理多尺寸高分辨率数据集的预测脚本,因为其中主要的思想是冗余切割,因此称之为膨胀预测。
具体想法如下:
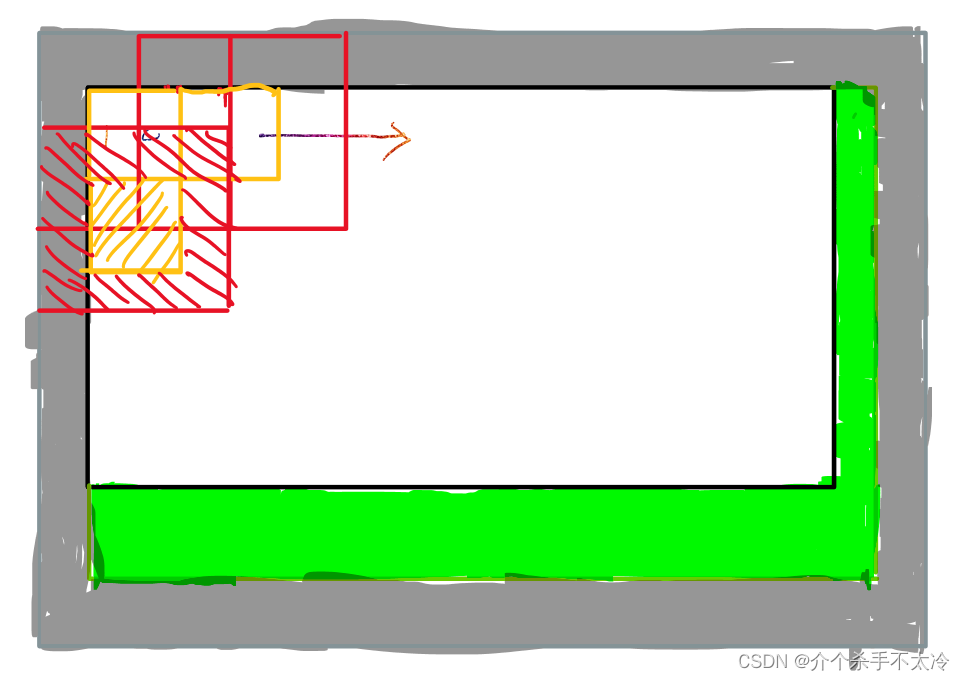
需要先将原图像按patchsize进行切割分成多个patchsize大小的小块图,再进行推理预测。然后将推理得到的结果图按下面的方法进行拼接融合。
1.确定patchsize:
首先根据训练时的patchsize大小, 确定推理时需要将原图切成patchsize大小的小块图。
2.像素填充:
用原图的宽除以patchsize得到一个余数,用patchsize减去刚才计算得到的余数,得到的差值就是在横向(宽)方向需要填充的像素个数,此时将差值像素数填充在原图最右边。同理,用原图的高除以patchsize得到一个余数,用patchsize减去刚才计算得到的余数,得到的差值就是在纵向(高)方向需要填充的像素个数,此时将差值像素数填充在原图最下边。此时经过填充后的图命名为A。
3.边缘膨胀(四周填充):
假设我们的patchsize是1024, 步长为512,那我们需要在上下左右四个边上各填充,步长/ 2512/ 2= 256个的像素,,这样就能以10241024的大小切原图,移动步长是256,这样就能把经过2次填充后的原图切成整数个。
4.推理后的拼接:
将这些patch放入模型推理后得到的结果图,每一个按照顺序取中心512512的区域进行拼接,就能完整的得到经过第一次填充后大小, 即第二步图A的大小,再将右边第一步右边新加的部分和下面新加的部分裁剪,即可得到原图大小的结果图。
这是我画的草图:
以下为代码:
# -*- coding: utf-8 -*-
# @Time : 2021/12/4 13:34
# @Author : WangQiang
# @ProjectName :breast_cancer_segmentation
# @FileName: Inflation_predict.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/Leon1997726
import glob
import os
import shutil
import cv2
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from PIL import Image
from keras_preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
os.environ["CUDA_VISIBLE_DEVICES"] = '0' # 指定第一块GPU可用
config = tf.compat.v1.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.7 # 程序最多只能占用指定gpu50%的显存,服务器上注释掉这句
config.gpu_options.allow_growth = True # 程序按需申请内存
sess = tf.compat.v1.Session(config=config)
Image.MAX_IMAGE_PIXELS = None
model = load_model(r"D:\DeepLearningProjects\Model_Save\unet_cancer_2021-11-16__01_27_12.h5") # 加载模型
slide_window = 4096 # 大的滑动窗口
step_length = 2048
# 1.膨胀图像
Image_Path = r"D:\DataSet\DCI(first)\image\2801-3.png"
Mask_Path = r"D:\DataSet\DCI(first)\mask\2801-3.png"
image = Image.open(Image_Path)
image_name = os.path.basename(r"E:\DCI(first)\image\2801-3.png")[:-4]
width = image.size[0] # 获取图像的宽
height = image.size[1] # 获取图像的高
right_fill = step_length - (width % step_length)
bottom_fill = step_length - (height % step_length)
width_path_number = int((width + right_fill) / step_length) # 横向切成的小图的数量
height_path_number = int((height + right_fill) / step_length) # 纵向切成的小图的数量
print(width_path_number, height_path_number)
image = np.array(image)
image = cv2.copyMakeBorder(image, top=0, bottom=bottom_fill, left=0, right=right_fill,
borderType=cv2.BORDER_CONSTANT, value=0)
image = cv2.copyMakeBorder(image, top=step_length // 2, bottom=step_length // 2, left=step_length // 2,
right=step_length // 2,
borderType=cv2.BORDER_CONSTANT, value=0) # 填充1/2步长的外边框
print('图像膨胀步骤完成!')
# 2.将膨胀后的大图按照滑窗裁剪
shutil.rmtree(r'./Image_Crop_Result') # 递归删除文件夹下的所有内容包扩文件夹本身
os.mkdir(r'./Image_Crop_Result')
image_crop_addr = './Image_Crop_Result/' # 图像裁剪后存储的文件夹
image = Image.fromarray(image) # 将图片格式从numpy转回PIL
l = 0
for j in range(height_path_number):
for i in range(width_path_number):
box = (i * step_length, j * step_length, i * step_length + slide_window, j * step_length + slide_window)
small_image = image.crop(box)
small_image.save(
image_crop_addr + image_name + '({},{})@{:03d}.png'.format(j, i, l), quality=95)
l = l + 1
print('膨胀后大图滑窗裁剪步骤完成!')
# 2、对上面裁剪得到的小图进行推理
shutil.rmtree(r'./Image_Predict_Result')
os.mkdir(r'./Image_Predict_Result')
path = r'./Image_Crop_Result/*.png'
expanded_images_crop = glob.glob(path)
# model = load_model("unet_cancer_2021-11-16__01_27_12.h5") # 加载模型
# 对小图一次进行单独预测,再将预测图保存为彩色索引图像
for k in expanded_images_crop:
expanded_image_crop = cv2.imread(k)
expanded_image_crop = cv2.cvtColor(expanded_image_crop,
cv2.COLOR_BGR2RGB) # 将BGR格式转成RGB格式,非常重要,之前缺少了这一步,2021.11.20.13:15分添加
img = expanded_image_crop / 127.5 - 1
img2 = cv2.resize(img, (256, 256))
img3 = img2[np.newaxis, ...] # 因为原先训练集是被打包成
pred_mask = model.predict(img3)
pred_mask = np.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., np.newaxis]
# 利用matplotlib将灰度图保存为彩色索引图像,这种方法为佳
pre = pred_mask[0]
pre = np.squeeze(pre, -1) # plt.save只接受M*N的图像格式,所以删去通道维度!!!
plt.imsave(r'./Image_Predict_Result/{}'.format(os.path.basename(k)), arr=pre)
print('推理步骤完成!')
# 3.将膨胀过的图裁剪回原来的大小
shutil.rmtree(r'./Image_Recover')
os.mkdir(r'./Image_Recover')
expanded_images = glob.glob(r'./Image_Predict_Result/*.png')
for expanded_image in expanded_images:
img = Image.open(expanded_image)
img_name = os.path.basename(expanded_image)
box = (64, 64, 192, 192)
original_image = img.crop(box)
original_image.save(r'./Image_Recover/' + img_name, quality=95)
print('图像裁剪回原来大小步骤完成!')
# 4、图片拼接
IMAGES_PATH = r'./Image_Recover/' # 图片集地址
IMAGES_FORMAT = ['.png'] # 图片格式
IMAGE_SIZE = 128 # 每张小图片的大小
# 获取图片集地址下的所有图片名称
image_names = [name for name in os.listdir(IMAGES_PATH) for item in IMAGES_FORMAT if
os.path.splitext(name)[1] == item]
image_names.sort(key=lambda x: int(x[-7:-4])) # 这句不能少,os.listdir得到的文件没有顺序,必须进行排序,
print("image_names", image_names)
IMAGE_ROW = int(height_path_number) # 图片间隔,也就是合并成一张图后,一共有几行
IMAGE_COLUMN = int(width_path_number) # 图片间隔,也就是合并成一张图后,一共有几列
# 简单的对于参数的设定和实际图片集的大小进行数量判断
if len(image_names) != IMAGE_ROW * IMAGE_COLUMN:
raise ValueError("合成图片的参数和要求的数量不能匹配!")
to_image = Image.new('RGB', (IMAGE_COLUMN * IMAGE_SIZE, IMAGE_ROW * IMAGE_SIZE)) # 创建一个新图
# 循环遍历,把每张图片按顺序粘贴到对应位置上
for y in range(1, IMAGE_ROW + 1):
for x in range(1, IMAGE_COLUMN + 1):
from_image = Image.open(IMAGES_PATH + image_names[IMAGE_COLUMN * (y - 1) + x - 1]).resize(
(IMAGE_SIZE, IMAGE_SIZE), Image.ANTIALIAS)
to_image.paste(from_image, ((x - 1) * IMAGE_SIZE, (y - 1) * IMAGE_SIZE))
# 拼接完的大图的右侧和下侧有多余填充上去的部分,应裁掉
box2 = (0, 0, int(to_image.size[0] - right_fill / (width + right_fill) * to_image.size[0]),
int(to_image.size[1] - bottom_fill / (height + bottom_fill) * to_image.size[1]))
original_mask = to_image.crop(box2)
original_mask.save(r'./Big_Image_Predict_Result/' + image_name + ".png", quality=95) # 保存新图
print('图像拼接步骤完成!')
# 5、显示大图预测结果
img_predict = Image.open(r'./Big_Image_Predict_Result/' + image_name + ".png")
img_predict = img_to_array(img_predict)
# img_predict = cv2.resize(img_to_array(img_predict), (1024, 1024))
Image_yuantu = Image.open(Image_Path)
Image_yuantu = img_to_array(Image_yuantu)
# Image_yuantu = cv2.resize(img_to_array(Image_yuantu), (1024, 1024))
Mask = Image.open(Mask_Path)
Mask = img_to_array(Mask)
# Mask = cv2.resize(img_to_array(Mask), (1024, 1024))
# Mask = Mask[..., np.newaxis] # 如果是多分割就启用,二分割就注释掉
plt.rcParams['font.sans-serif'] = ['SimHei'] # 改字体,防止plt显示中文乱码
plt.rcParams['axes.unicode_minus'] = False
plt.figure(dpi=600)
plt.suptitle("大图预测结果可视化(" + os.path.basename(Image_Path) + ")", fontsize=20)
plt.subplot(1, 3, 1)
plt.title('real image')
plt.imshow(tf.keras.preprocessing.image.array_to_img(Image_yuantu))
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.subplot(1, 3, 2)
plt.title('real mask')
plt.imshow(tf.keras.preprocessing.image.array_to_img(Mask))
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.subplot(1, 3, 3)
plt.title('pred mask')
plt.imshow(tf.keras.preprocessing.image.array_to_img(img_predict), cmap='plasma')
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.savefig(r'D:\DataSet\膨胀\预测结果(' + os.path.basename(Image_Path)[:-4] + ').png', dpi=600)
plt.show()
print("大图预测显示步骤完成!")














 1818
1818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









