







 本文探讨了在单目深度估计中,利用几何预训练的方式改善模型性能。通过对结构和运动信息的分离,设计了结构编码器、运动编码器和光流解码器的框架。实验表明,几何预训练能有效地学习到图像的结构信息,进而提高深度估计的准确性。
本文探讨了在单目深度估计中,利用几何预训练的方式改善模型性能。通过对结构和运动信息的分离,设计了结构编码器、运动编码器和光流解码器的框架。实验表明,几何预训练能有效地学习到图像的结构信息,进而提高深度估计的准确性。
一些前提知识
Monocular Depth Estimation:单目深度估计,从单张图片中去预测每个像素点具体的深度,相当于从二维图像推测出三维空间。
ImageNet-Pretraining:基于ImageNet的预训练模型,ImageNet是一个带有标签的大数据集,其中有1,000个类别的图像。CV界常在进行下游任务之前,一般会在ImageNet上进行预训练,以学习到图像的语义信息,便于迁移学习。
optical flow:光流,用于研究图像对齐的算法,分为稀疏光流(一般选角点)和稠密光流。
stereo images:立体图像集,由不同角度拍摄的图像集合。
Abstract
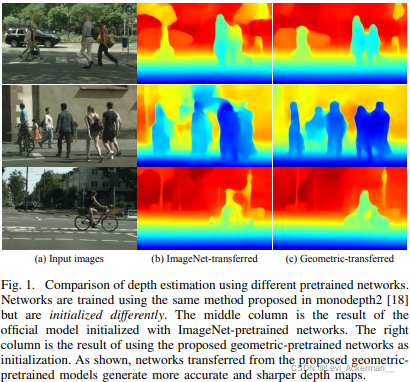
| ImageNet-pretrained networks have been widely used in transfer learning for monocular depth estimation. These pretrained networks are trained with classification losses for which only semantic information is exploited while spatial information is ignored. However, both semantic and spatial information is important for per-pixel depth estimation. In this paper, we design a novel self-supervised geometric pretraining task that is tailored for monocular depth estimation using uncalibrated videos. The designed task decouples the structure information from input videos by a simple yet effective conditional autoencoder-decoder structure. Using almost unlimited videos from the internet, networks are pretrained to capture a variety of structures of the scene and can be easily transferred to depth estimation tasks using calibrated images. Extensive experiments are used to demonstrate that the proposed geometric-pretrained networks perform better than ImageNet-pretrained networks in terms of accuracy, few-shot learning and generalization ability. Using existing learning methods, geometric-transferred networks achieve new state-of-the-art results by a large margin. The pretrained networks will be open source soon1 . | 基于ImageNet的预训练网络已经在单目深度估计的迁移学习中广泛的使用了。这些预训练网络都只挖掘出了图像的语义信息而忽略了其空间信息,但它们对于逐像素的深度预测都十分重要。本文中,我们设计了一个新奇的自监督的为单目深度估计量身定做的使用无标定视频进行训练的几何预训练任务。设计的任务通过简单但有效的条件自编码-解码器架构,将结构信息和输入视频解耦。使用来自互联网的几乎没有限制的视频,整个网络架构通过预训练得到场景不同的结构信息,并且可以使用有标注的图像轻松的迁移至单目深度估计任务中。我们做了许多的实验去验证我们的geometric-pretraining模型在精度、小数据学习和泛化能力上表现优于ImageNet-pretraining。使用现有的学习方法,我们的几何迁移网络实现了新的最先进的结果,并且领先了一大截。我们的预训练网络即将开源。 |
目前研究方法 + 存在的问题 + 我们提出的观点 + 我们的优势 + 实验结果
1 Introduction
| Estimating depth maps of images is of vital importance in computer vision and robotics. Benefiting from the development of deep learning, many methods have been proposed to estimate the depth map using a single input image. These methods can be deployed easily and used in a variety of applications such as visual odometry [1], [2], sensor fusion [3], and augmented reality [4]. Although generating impressive results, learning-based methods need a large amount of data for training. Per-pixel depth annotating of real-world images is almost impossible as LiDAR only provides sparse depth measurements, and time-of-flight (ToF) cameras have limited ranges. The KITTI stereo dataset [5] uses CAD models to densify depth measurements of cars but only contains hundreds of images. Yang et al. [6] propose DrivingStereo with more than 180k frames fused from multi-frame LiDAR measurements. Despite the high accuracy depth measurement in DrivingStereo, the density of annotated pixels is less than 15%. Recently, many self-supervised works [7]–[16] have been proposed to train networks using calibrated stereo images or monocular videos. These methods are built on the assumption that images from nearby |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7804
7804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









