







写在前面:
第十九届数模研赛在22年10月6-10日开展,我和我的两名队友肝了5天,整出来一篇论文。因为不确定自己做的好不好,所以一直没写博客。前两天结果出来了,我们队拿了国二,在C题里排名88/1134,感觉结果还不错。
以后应该也不会再有机会参加数学建模了,在此简单记录一下最后一次数模的解题思路。
代码就不分享了,也没有分享的必要,准备数学建模竞赛还是重在看懂解题思路,想获奖写好论文比较重要。各位读者有问题可以评论/私聊我~
系列文章链接汇总如下:
(一)C题题目
(二)问题重述
(三)问题一模型建立
(四)问题二模型建立
(五)算例分析
文章目录
根据题意,本文建立了一个两阶段优化模型。第一阶段为自适应并行遗传算法模型,该模型对每辆车身在从涂装车间接出后应送往的目标车道进行编码。 由于模型中送车横移机的卸载位置决策较为复杂(与时序运行结果有关) ,在此我们采用在一阶段遗传算法中嵌套贪心策略进行处理, 算法由该车在贪心算法下的决策以及该车的后一辆车辆的决策,来共同决定是否需要将该车送回返回车道。 第二阶段为贪心寻优模型, 其将以一阶段找到的最优染色体为基础执行贪心算法,寻找对当前解的更优改进。
1.问题一的决策变量
参照(二)问题重述,问题一需要进行决策优化的变量有2个:
- 接车横移机(左)的送车位置:进车道1、2、3、4、5、6的车位10,共6个选择
- 送车横移机(右)的送车位置:总装车间的入车口,返回车道的车位1,共2个选择
变量1采用遗传算法来优化求解,变量2采用贪心策略进行简化。
2.一阶段模型:自适应并行遗传算法模型
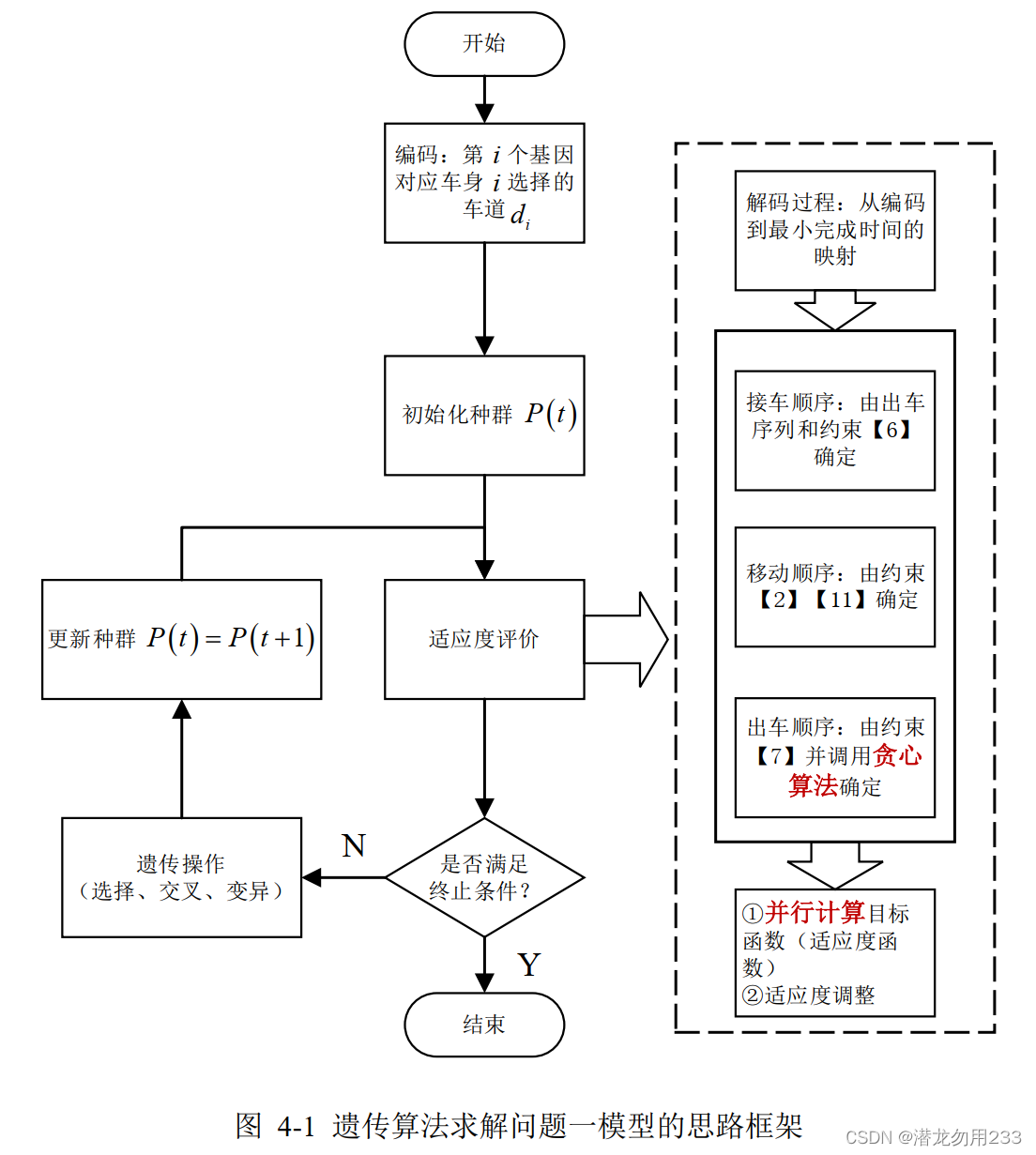
2.1染色体编码
由于变量2已被贪心策略进行简化,模型需要优化确定的仅有一个变量,即变量1。所以仅需对变量1进行编码即可。
我们将各个车身对应的送入目标车道编码为基因,为 1-6 的整数,进而形成一个长度为 318(根据问题附件,一共有318辆进车)的基因组成的染色体,基因在染色体上的排列顺序与涂装车间的出车序列相同。
2.2适应度函数
本文采用目标函数作为适应度函数。
在解码得到总装车间的出车序列之后,我们可以计算种群中各个个体的目标函数。
题目中的目标函数如下所示:

- 优化目标 1 的函数值可以由解码后的序列得到, 可以表示为下式:
o b j 1 = 100 − ∑ i = 1 N p i 1 obj_1=100-\sum_{i=1}^N p_i^1 obj1=100−i=1∑Npi1
优化目标 1 的扣分规则可以被表述为:选择序列中的一个车身,当该车身为非混合动力车型时,不执行扣分;当该车身为混合动力车时,若其后两辆车身均为非混合动力车时,不执行扣分,否则扣 1 分。即有下式:
p i 1 = 0 , i f ( F u e l i = 2 ) p i 1 = 0 , i f ( F u e l i = 1 ) a n d ( F u e l i + 1 = 2 ) a n d ( F u e l i + 2 = 2 ) p i 1 = 1 , e l s e i = 1 , 2 , . . . , N p_i^1 = 0, if (Fuel_i = 2)\\ p_i^1 = 0, if (Fuel_i = 1) and (Fuel_{i+1} = 2) and(Fuel_{i+2} = 2)\\ p_i^1 = 1, else\\ i =1,2,...,N pi1=0,if(Fueli=2)pi1=0,if(Fueli=1)and(Fueli+1=2)and(Fueli+2=2)pi1=1,elsei=1,2,...,N
式中 F u e l i Fuel_i Fueli 为代表总装车间出车序列中第 i i i 辆车的燃料类型,若为 1 则为混合动力车型,若为 2 则为非混合动力车型。
- 优化目标 2 的函数值可以由解码后的序列得到, 可以表示为下式:
o b j 2 = 100 − ∑ i = 1 N p i 2 obj_2=100-\sum_{i=1}^N p_i^2 obj2=100−i=1∑Npi2
优化目标 2 下的扣分规则可以表述为:选择序列中的一个车身,若该车身为四驱车,且其后一辆车为两驱车时为分块边界点,需要判定其所在分块的两驱车数量与四驱车数量之差是否为 0,若不为零,说明两种车型数量不等,则扣 1 分;其他情况均不执行扣分。
p i 2 = 1 , i f ( t y i = 4 ) a n d ( t y i = 2 ) a n d ( s u m i ≠ 0 ) p i 2 = 0 , e l s e i = 1 , 2 , . . . , N p_i^2 = 1, if (ty_i = 4)and(ty_i = 2)and(sum_i \neq 0)\\ p_i^2 = 0, else\\ i =1,2,...,N pi2=1,if(tyi=4)and(tyi=2)and(sumi=0)pi2=0,elsei=1,2,...,N
式中 t y i ty_i tyi 为代表总装车间出车序列中第 i i i 辆车的驱动类型,若为 2 即为两驱车型, 若为 4 即为四驱车型。
S
u
m
i
Sum_i
Sumi 为计数辅助变量,表示为截止到第
i
i
i 辆车身,其所在的分块中两驱车数量与四驱车数量之差。 其含义为,若该车的车型为两驱车,其前一个车型为四驱车,则该车为这一分块的第一辆车,需要将置为 1;其余情况下,若为两驱车则计数辅助变量执行加 1,若为四驱车则计数辅助变量执行减 1。计算式如下:
s
u
m
i
=
1
,
i
f
(
t
y
i
=
2
)
a
n
d
(
t
y
i
−
1
=
4
)
s
u
m
i
=
s
u
m
i
−
1
+
1
,
i
f
(
t
y
i
=
2
)
a
n
d
(
t
y
i
−
1
=
2
)
s
u
m
i
=
s
u
m
i
−
1
−
1
,
i
f
(
t
y
i
=
4
)
i
=
1
,
2
,
.
.
.
,
N
sum_i = 1, if (ty_i = 2)and(ty_{i-1} = 4)\\ sum_i = sum_{i-1} + 1, if (ty_i = 2)and(ty_{i-1} = 2)\\ sum_i = sum_{i-1} - 1, if (ty_i = 4)\\ i =1,2,...,N
sumi=1,if(tyi=2)and(tyi−1=4)sumi=sumi−1+1,if(tyi=2)and(tyi−1=2)sumi=sumi−1−1,if(tyi=4)i=1,2,...,N
- 优化目标 3 的函数值可以由解码后的序列得到, 可以表示为下式:
o b j 3 = 100 − ∑ i = 1 N N i R obj_3=100-\sum_{i=1}^N N_i^R obj3=100−i=1∑NNiR
式中, N i R N_i^R NiR 为使用返回车道的次数。
- 优化目标 4 的函数值可以由解码后的序列得到, 可以表示为下式:
o b j 4 = 100 − 0.01 × ( T − 9 N − 72 ) obj_4=100-0.01\times (T-9N-72) obj4=100−0.01×(T−9N−72)
式中 T T T 为解码后的总时间, N N N 为需要通过调序车间的车辆总数, ( 9 N + 72 ) (9N+72) (9N+72) 为理论的最短通过时间(全走中间车道)。
- 因此,总的目标函数/适应度函数可以写成下式:
o b j = 0.4 × o b j 1 + 0.3 × o b j 2 + 0.2 × o b j 3 + 0.1 × o b j 4 obj=0.4\times obj_1+ 0.3\times obj_2+0.2\times obj_3+0.1\times obj_4 obj=0.4×obj1+0.3×obj2+0.2×obj3+0.1×obj4
2.3解码规则
由于编码过程仅对各个车身对应的送入车道进行了编码,解码过程需要根据这一基因型来推演/模拟出整个车间的运作流程。
这里用三张流程图,分别表示车间中运动的三个物体(在车道内的车、接车横移机、送车横移机)的运动情况,如下所示。
因为我懒,解码这里就不写公式了。反正这一步就是能够通过进车车道模拟出整个运行过程即可。
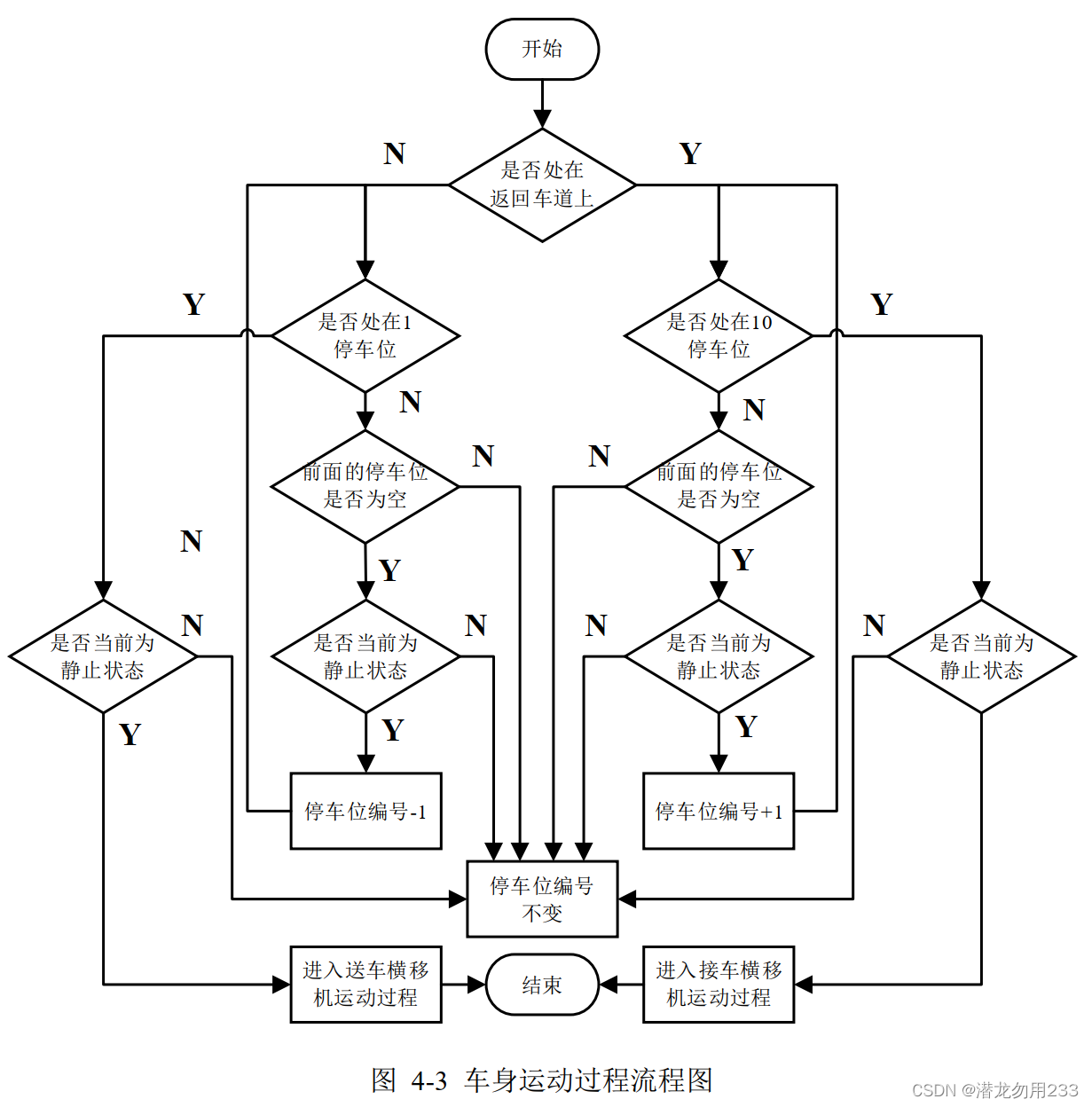
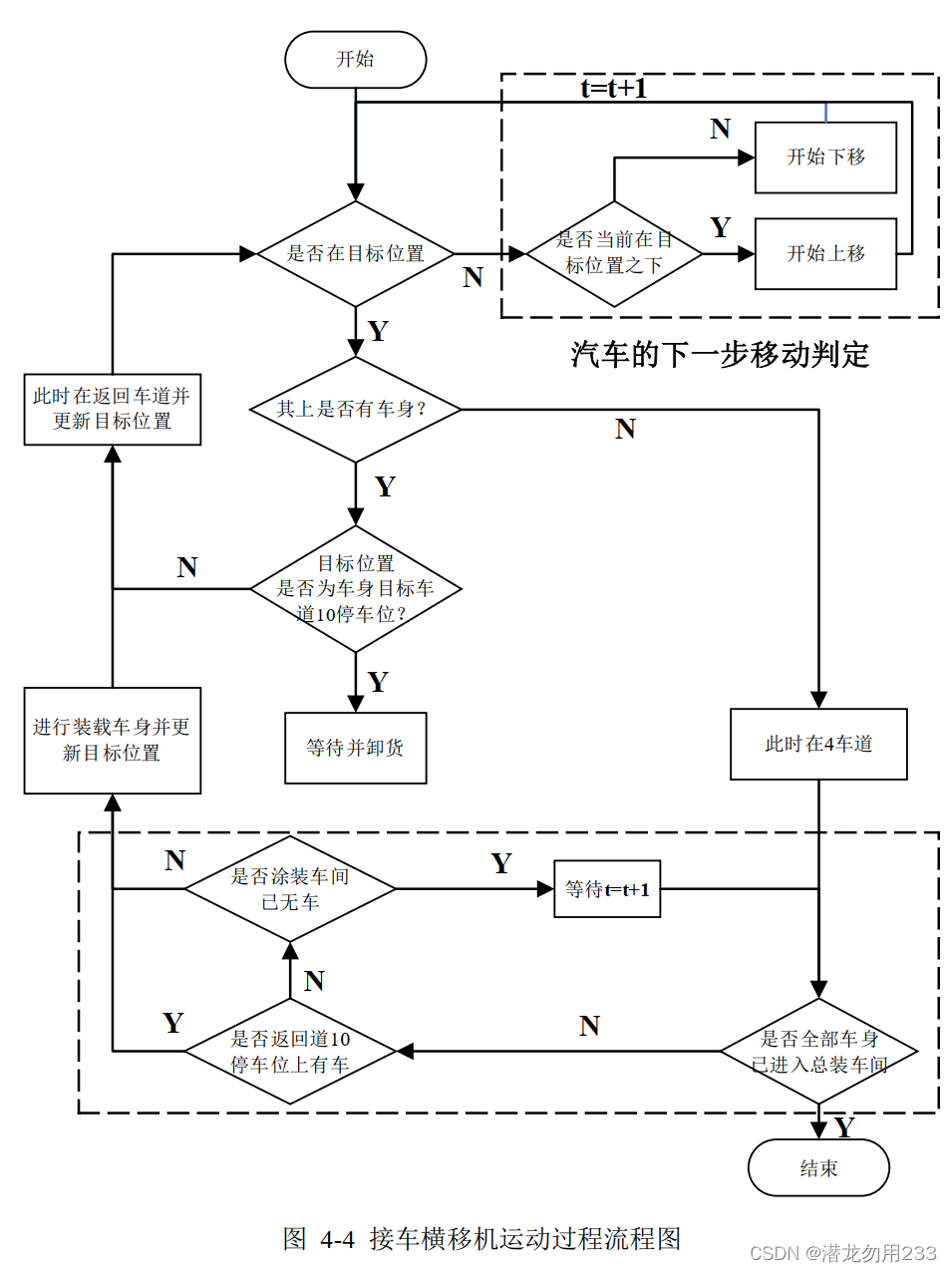
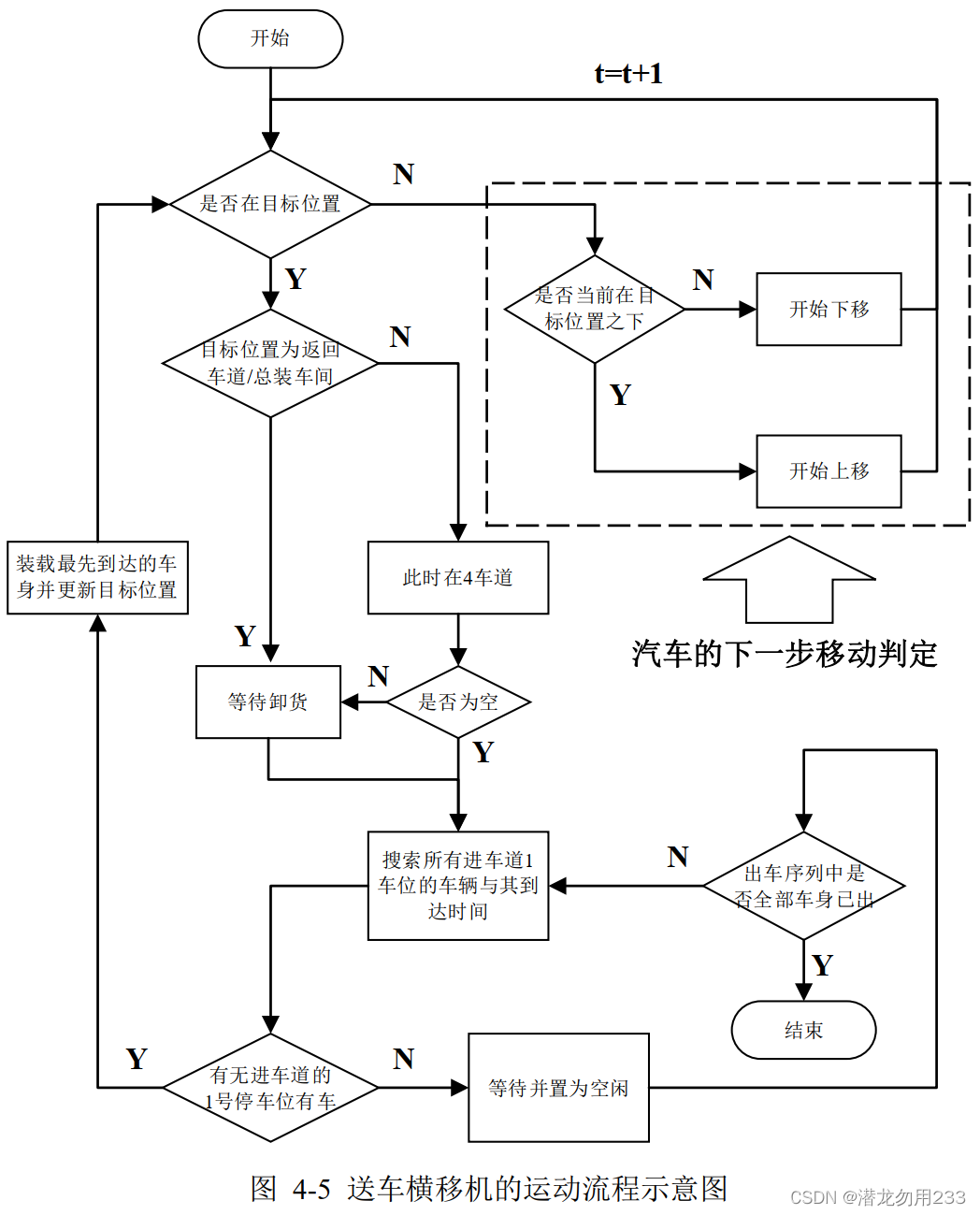
2.4遗传算子
2.4.1交叉算子
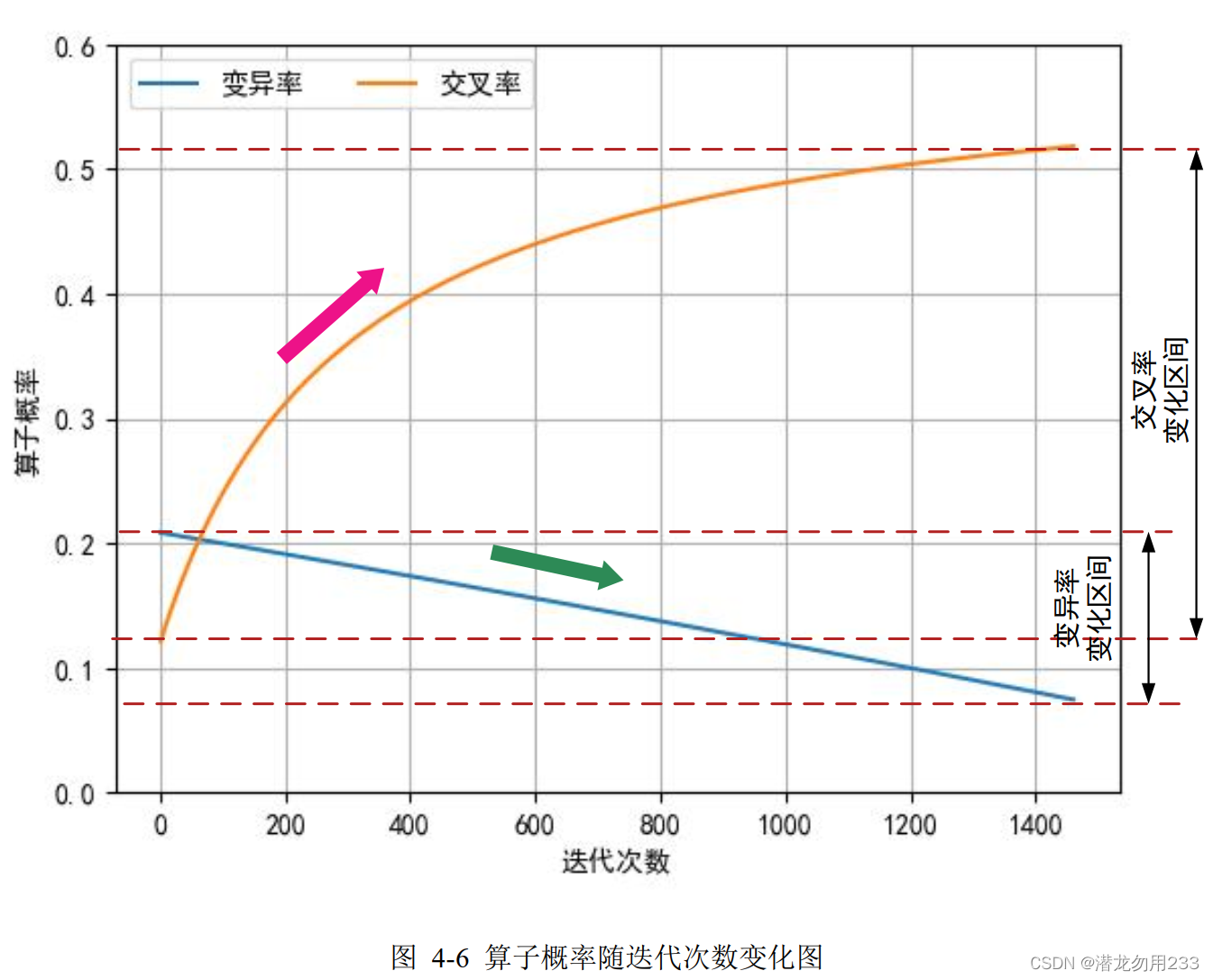
本模型的交叉算子采用单点交叉,即对于要交叉的两条染色体,随机选择一个基因位,交换该基因位之后所有基因。 要进行交叉的染色体按照交叉率的概率进行抽样获得。 为了保证本问题中解的质量, 本模型设置的交叉率随着迭代的次数的变化而变化, 即交叉率随代数增长自适应变化。交叉率的计算表达式如下:
a c r = 0.6 × i t e r + 60 i t e r + 300 acr=0.6\times\frac{iter+60}{iter+300} acr=0.6×iter+300iter+60
式中, a c r acr acr 为交叉率, i t e r iter iter 为迭代次数(子代数)。遗传算法中设置迭代次数至多为2000次,即有 i t e r < = 2000 iter<=2000 iter<=2000。
随着代数的增长,交叉率也在逐渐增长。当代数为 0 时,交叉率初值为 0.12,即有近似 10%的概率进行交叉,当代数为 2000时,交叉率为 0.537,即有超过 50%的概率进行交叉,子代更多地保留了父代的基因特征。
2.4.2变异算子
本遗传算法模型采用位变异,即对基因中的某一位进行变异。 要进行变异的基因位按照变异率的概率进行变异,即每个染色体的每一位都有变异率的概率变异。 为了保证本问题中解的质量, 本模型设置的变异率也同样随着迭代的次数的变化而变化, 即变异率随代数增长自适应变化。变异率的计算表达式如下:
m u t = 2 × i t e r − 2190 i t e r − 21000 mut=2\times\frac{iter-2190}{iter-21000} mut=2×iter−21000iter−2190
式中, m u t mut mut 为变异率, i t e r iter iter 为迭代次数(子代数)。遗传算法中设置迭代次数至多为2000次,即有 i t e r < = 2000 iter<=2000 iter<=2000。
随着代数的增长, 变异率在逐渐减小。当代数为 0 时, 变异率初值为 0.208,即有近似 20%的概率进行变异,当代数为 2000 时,交叉率为 0.02,即有 2%的概率进行变异, 如此保证了在代数增长到一定范围后不会因为变异率过大导致模型不收敛。
下图为交叉率和变异率随代数变化的趋势:
2.4.3选择算子
为了满足种群中每个个体(所有的可行解)进行“优胜劣汰”的选择,需要根据适应度函数确定一个淘汰的阈值,当个体的适应性函数值小于该阈值时, 会将这部分个体进行淘汰,在此我们设置的阈值表达式为:
min { o b j p } + 0.2 × ( max { o b j p } − min { o b j p } ) \min\{obj_p\}+0.2\times(\max\{obj_p\}-\min\{obj_p\}) min{objp}+0.2×(max{objp}−min{objp})
上式的意义为淘汰掉适应度函数(目标函数)值排序后位于后 20%的适应度函数对应的个体。
将这部分个体淘汰掉之后,为保证种群中个体的数量不变, 需用表现型(适应度)最好的个体对种群进行补充,直到达到子代种群的个体数要求,而后再次进行一次交叉和变异,接着进入下一次迭代。
2.5 贪心策略
2.5.1基本原则
在问题一的一阶段遗传算法中,右侧送车横移机选择哪个车辆(变量2)根据贪心策略来确定。
这一贪心策略的基本原则是根据不同动作执行后对目标函数的惩罚来进行贪心选择,即选择执行后对目标函数损失最少的动作执行。
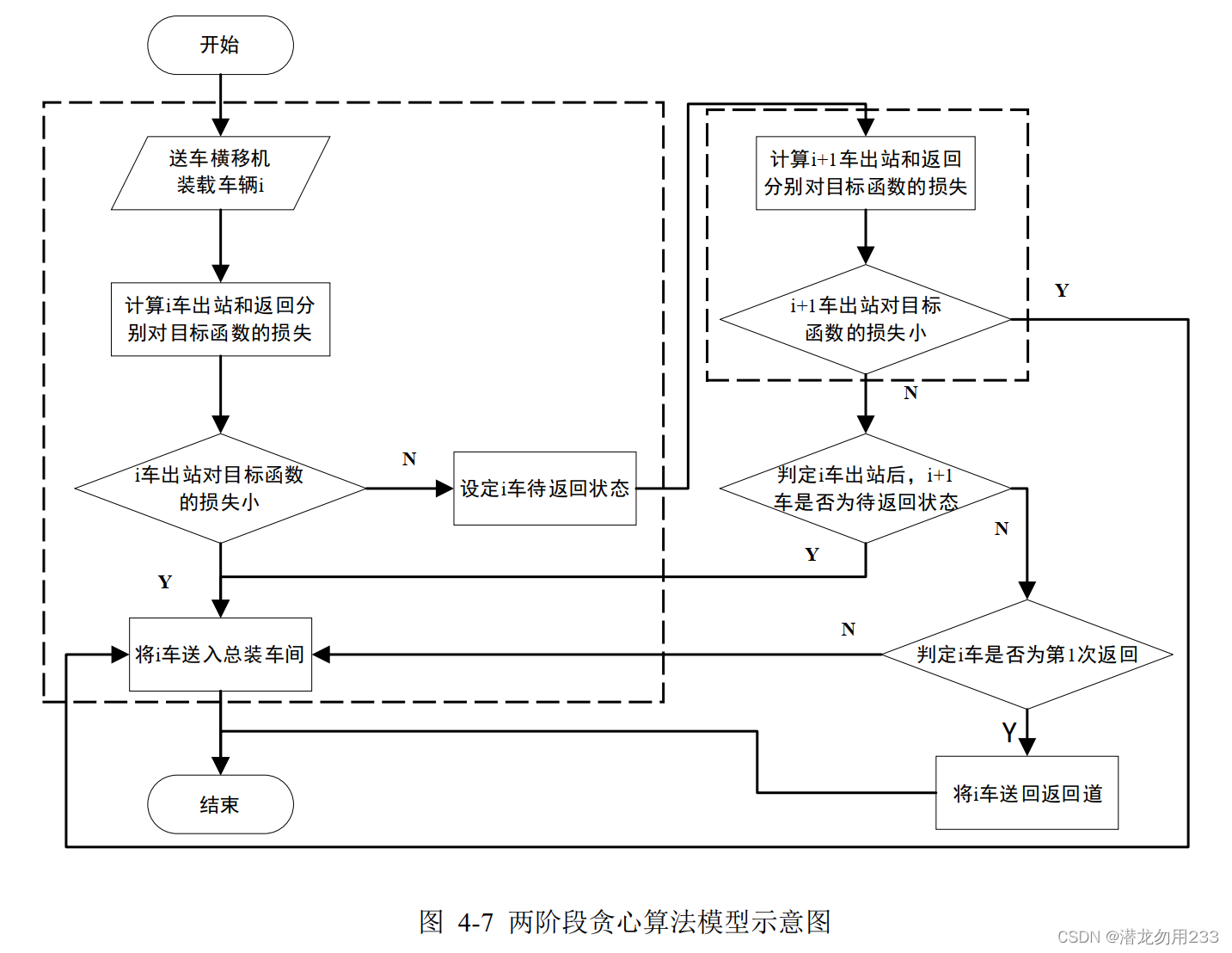
(由于懒惰,我在这里也不写公式了)
这里图画的好像也有一点问题,请看下面我的文字讲解。
贪心的策略说明如下:
当右侧送车横移机接到车后,需要选择是送入返回车道,还是送入总装车间。这一步判断通过计算哪个选择损失的分数更少来决定。
送入总装车间的扣分值计算式为:
S c o r e L o s s i z = 0.4 × b i 1 + 0.3 × b i 2 ScoreLoss_i^z=0.4\times b_i^1+0.3\times b_i^2 ScoreLossiz=0.4×bi1+0.3×bi2
式中, S c o r e L o s s i z ScoreLoss_i^z ScoreLossiz 为将第 i i i 辆车送入总装车间的扣分值, b i 1 b_i^1 bi1 为是否会破坏优化目标1的二元变量(是否对出车排序造成破坏),破坏为1,即扣0.4分,未破坏为0; b i 2 b_i^2 bi2 为是否会破坏优化目标2的二元变量(是否对出车比例造成破坏),破坏为1,即扣0.3分,未破坏为0;
送入返回车间的扣分值计算式为:
S c o r e L o s s i f = 0.2 + 0.1 × ( 9 + T i d + 6 ) ScoreLoss_i^f=0.2+0.1\times (9+T_i^d+6) ScoreLossif=0.2+0.1×(9+Tid+6)
式中, S c o r e L o s s i f ScoreLoss_i^f ScoreLossif 为将第 i i i 辆车送入返回车道的扣分值,送车横移机将车卸载在返回车道,造成的目标函数的损失来源于返回车道的惩罚与多花费时间的惩罚,而多花费的时间来自于该车送回插队对总装车间的进车过程将造成 9 秒的时间消耗、整个送车横移机将车送回返回车道比送到总装车间多花费 T i d T_i^d Tid秒的时间、以及接车横移机装卸载该车身需多花费 6 秒时间。
因此,贪心策略的决策过程如下:
当送入总装车间扣分更少,则直接送出。
因为应当尽可能少地使用返回车道,所以当送入返回车道扣分更少时,不会直接送入返回车道,而会判断一下第 i + 1 i+1 i+1 辆车(下一辆要接的车)是否该送出?
如果第
i
+
1
i+1
i+1 辆车可以直接送入总装车间(即“
i
+
1
i+1
i+1 车出站对目标函数的损失更小”),那么就直接把第
i
i
i 辆车送回返回车道;(图里这里有问题,懒得改了)
否则(第
i
+
1
i+1
i+1 辆车也要送入返回车道),我们认为连续送回两辆车是一个一定不好的选择。(贪心的另一重简化思想在这里体现)
因此当第
i
+
1
i+1
i+1 辆车也需要返回(需要连续送回两辆车)时,我们直接将第
i
i
i 辆车送入总装车间。
此外,还需注意,为了尽可能少地使用返回车道,我们规定每辆车最多被送回去一次,即如果这次送回去了,那下次再被右侧送车横移机接到后,必定会直接送入总装车间。
整体的思想为贪心,即人为做了一些假设,预设了多种模式,将复杂的变量决策过程简化为一个连续判断的流程。
诚然,这是一步很大的简化。
我们也想过能否通过双层遗传算法来处理这两个变量,但是我们没有这么做,还是选择了贪心算法,有两方面的考虑:
- 问题一本身题目条件就简化了,可以通过一些可解释的选择策略对变量2进行简化,也是解的寻优过程可以接受的;
- 问题的解空间非常大,且变量2时序依赖于变量1(车道右侧的到达顺序可以被涂装车间的进车顺序+送入车道唯一确定),因此如果嵌套双层模型,我们担心求解时间过长。
因此,还是通过一定的贪心策略对变量2进行了简化,因为我们希望做一个单变量的优化,求解起来快一些。
2.5.2超参数 γ \gamma γ 的选择
- 为什么要引入超参数 γ \gamma γ?
原因:超参数 γ \gamma γ 表示当右侧送车横移机需要判断当前车辆要送往返回车道还是送往总装车间时, 有 γ \gamma γ 的概率直接送往总装车间,有 ( 1 − γ ) (1-\gamma) (1−γ) 的概率需执行本步贪心算法来确定是否返回。
因为贪心策略也不是最优的选择,而且在实验中我们发现以一定概率来执行贪心策略效果会更好,所以才引入了超参数 γ \gamma γ。
关于为什么每次都执行贪心策略的结果不是最优,我们简单解释如下:(也不严谨,但可以简单理解一下我们的思路)
需要注意的是, 在右侧送车横移机需要判断对当前车辆送到哪里时,每次都执行本贪心策略模型不是最优的。 因为在某些情况下, 将车辆送入返回车道是更坏的选择,应该不论惩罚值对比情况如何,都直接送至总装车间。这一点可被以下两点解释说明:
1) 将车送往返回车道,对目标三、四一定会更坏:对目标三,每利用返回车道一次就扣 1 分;对目标四,将车送往返回车道花费了原本不需要的左右横移机的横移时间,总时间必然会增长,惩罚值上升;
2) 将车送往返回车道,对目标一、二不一定会更优: 由假设 1 可知, 同一车辆仅能使用返回车道一次,即本次送回后,下次该车再次被右侧送车横移机装载时,必会直接送往总装车间。由于在第一次判断是否要送往车道的时候不能知道该车返回时已经送往总装车间的车辆的送出序列,因此此时无法知道将本车送回一次后再次抵达车位 1 时,对目标一、二的结果是否有改善。 造成这一结果的原因在于贪心策略的短视性,即只能看到本步最优,没有考虑后续结果的优劣性。
- 超参数 γ \gamma γ 的选择方式
本小节对 4.2.2 节中的超参数 γ \gamma γ 进行选择,以使模型完整。对超参数 γ \gamma γ 的实验方式为生成 10000 个种群,执行 1 代,保留适应度函数最高的子代;其效果等价于在解空间内随机抽样 10000 个样本,取目标函数最优值。按照此验证方式, 对超参数 γ \gamma γ 从 0 到 1 以 0.1 为步长执行 10 次,得到结果如下表所示
表 超参数 γ \gamma γ 实验验证过程最优子代目标函数值表
| γ \gamma γ | 附件1的最优值 | 附件2的最优值 | γ \gamma γ | 附件1的最优值 | 附件2的最优值 |
|---|---|---|---|---|---|
| 0 | -21.300 | 17.253 | 0.6 | 6.634 | 34.636 |
| 0.1 | -21.300 | 21.080 | 0.7 | 9.138 | 34.686 |
| 0.2 | -10.490 | 23.423 | 0.8 | 12.037 | 36.868 |
| 0.3 | -6.024 | 25.549 | 0.9 | 15.159 | 38.319 |
| 0.4 | -2.428 | 28.548 | 0.99* | 18.281 | 39.814 |
| 0.5 | 3.133 | 30.575 |
*此处的 0.99 按照步长的设置应该为 1,但是如果 γ = 1 \gamma=1 γ=1,其对应的情况为右侧送车横移机会将所有的来车直接送出, 彻底不用返回车道,与题意所述的调序调度不符,故此处用 0.99 代替 1。
需要指出的是,本试验的实验结果带有一定随机性,无法仅通过附件 1、 2 的最优值来判断参数选择的好坏。但是仍能从上表中看出一定的趋势——随着超参数 γ \gamma γ 的增大,目标函数值也在逐渐上升。
因此,选取 0.9、 0.95、 10.99 三组数据做了进一步参数对比分析,实验方式为对三个参数分别执行 1000 代每代 1000 个种群的一阶段遗传算法,记录其最优适应度函数值,实验结果如下表所示,下文算例分析将依据此结果来选择参数 γ \gamma γ 的取值。
表 超参数 γ \gamma γ 进一步实验验证过程最优子代目标函数值表
| γ \gamma γ | 附件1的最优值 | 附件2的最优值 |
|---|---|---|
| 0.9 | 17.657 | 40.278 |
| 0.95 | 18.044 | 41.854 |
| 0.99 | 26.298 | 47.580 |
因此,从上表中可以看出, γ = 0.99 \gamma=0.99 γ=0.99 对阶段一的遗传算法最优,故算例分析中将取该值作为超参数 γ \gamma γ 的取值。
3.二阶段模型:贪心寻优算法模型(邻域搜索)
第二阶段的贪心寻优模型以一阶段找到的最优染色体为基础执行贪心算法,寻找对当前解的更优改进。
设置第二阶段的目的为,由于本问题的解空间过于庞大,一阶段遗传算法很难在短时间内收敛到全局最优的结果,因此在一阶段遗传算法所得的较优解的基础上寻求改进是一种对程序执行时间不够长的平衡。
在二阶段模型中,对两个可变量进行贪心寻优:每个车身的左侧接车横移机送入的目标车道(变量 1) ,以及每个车身是否可以返回(变量 2) 。
对变量 1 的一次贪心寻优过程可以描述为: 对任意一辆车被左侧接车横移机接到后要送往的目标车道而言,如果目标车道是车道 4,则认为无法更优;如果目标车道不是车道4,则将其向车道 4 靠近 1 个进车道。 如果按上述步骤改变某一辆车的目标车道后,新生成的染色体的目标函数值更优,则将更优的染色体序列替换原先的序列,而后继续进行下一次贪心寻优。
对变量1的贪心寻优,即以期望所用时间更少为贪心策略,看能否送入车道更加靠近中间车道(车道4)。
因为车身通过每个车道的时间是相同的(在不堵车的前提下),因此影响调序车间工作时间长短的只是左右两个横移机的移动时间长短,而中间车道(车道4)是能够使两个横移机移动时间都为0的车道选择。
所以我们假设送入中间车道(车道4)最优,看能否通过让车辆更加靠近车道4的方式来减少总时间。
由于假设 1(每辆车仅可返回 1 次),因此存储车辆是否返回的序列中的值为 0 或 1(0 为不可返回, 1 为可以返回) ,对于每辆车的变量 2 可能的变化也仅有两种情况。因此,对变量 2 的一次贪心寻优可以描述为: 对存储车辆是否返回的序列顺次进行遍历, 每次仅改变一辆车的值,如果为 0 则修改为 1,如果为 1 则修改为 0, 执行后如果出现了结果更优的目标函数值,则将更优的是否返回序列替换原先的序列,替换后继续进行下一次贪心寻优。
对变量2的贪心寻优,即看改变右侧横移机送入的车位后,是否会对结果更加优化。
执行的过程是在其他情况都固定的情况下,对右侧变量2的可能情况进行遍历,得到更优的结果。
本阶段仅对一条染色体进行优化,采用贪心的思想, 能够将遍历的空间大大减少。
整体的寻优模型可叙述为如下过程:拿到一阶段输出的最优染色体之后,先对变量 1 执行贪心寻优,过程中如果有更优染色体则需要替换原先染色体,之后对变量 2 执行贪心寻优,过程中如果有更优的返回序列则需要替换原先的返回序列, 然后回到起始阶段,对变量 1执行贪心寻优,再对变量 2 执行贪心寻优, 以此类推,进行循环,直到满足终止条件时跳出循环, 解码后输出最优染色体对应的结果。
本贪心寻优算法的终止条件为:顺次对两个变量分别进行贪心寻优,算法执行后对应的变量序列没有被更新,即遍历后没有找出更优解,就终止寻优过程,将该段染色体记为最优染色体并输出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









