







《Emotion-Cause Pair Extraction》论文解读
这是一篇2019ACL的杰出论文,链接: https://arxiv.org/abs/1906.01267v1.
Abstract
Emotion cause extraction (ECE),实现的是在文本中给定情感,提取出潜在的原因。这个问题近些年广泛应用而得到人们的关注,然而ECE有两个不足:
- 在原因提取之前情感必须要被标注;
- 先标注、再提取忽视了二者的相互关系。
所以该论文提出了新的任务:emotion-cause pair extraction (ECPE),用来提取潜在的“情感-原因”对。在ECPE中分为两步,首先通过多任务学习分别提取情感和原因,然后进行情感和原因的配对并进行过滤。
Main contributions:
- 提出了新任务ECPE,解决了传统ECE任务依赖于标注的短板
- 提出了two-step框架解决ECPE
- 基于ECE语料库构造了适合ECPE任务的语料库
1.Introduction
如下图所示,有五个子句,情感“happy”在第四个句子中,并称之为emotion clause,它有两个对应的cause clause:“a policeman visited the old man with the lost money”和“told him that the thief was caught”,由于包含着原因,所以这两个定义为cause clause。
ECE任务是一个二分类问题,目标是检查文档中的每一个子句是否是被标注情感的原因。这篇论文提出的ECPE与ECE的区别如下图所示,ECPE的输出为“情感-原因”对,不需要事先对情感进行标注。在下图的例子中,在ECE中,已知情感是“happy”,目标是提取出两个cause clause:“a policeman visited the old man with the lost money”和“and told him that the thief was caught”;在ECPE中,目标是直接提取所有的 “情感-原因” 对,有:(“The old man was very happy”, “a policeman visited the old man with the lost money”)和(“The old man was very happy”,“and told him that the thief was caught”)

本文提出的任务主要有两个步骤:
- 把“情感-原因”提取任务通过多任务学习网络分为两个独立的任务:提取出情感子句 E = { c 1 e , ⋯ , c m e } E=\{c_1^e,\cdots,c_m^e\} E={c1e,⋯,cme}和原因子句 C = { c 1 c , ⋯ , c n c } C=\{c_1^c,\cdots,c_n^c\} C={c1c,⋯,cnc}
- 将 E 和 C 通过笛卡尔乘积进行配对,通过训练一个filter过滤掉不包含情感和原因关系的配对
2.Approach
首先给出ECPE符号定义:一个包含多个子句的文档
d
=
{
c
1
,
c
2
,
⋯
,
c
∣
d
∣
}
d=\{c_1,c_2,\cdots,c_{\vert d\vert}\}
d={c1,c2,⋯,c∣d∣}
ECPE的目标是提取“情感-原因”对:
P
=
{
⋯
,
(
c
e
,
c
c
)
,
⋯
}
P=\{\cdots,(c^e,c^c),\cdots\}
P={⋯,(ce,cc),⋯}
其中,
c
e
c^e
ce是情感子句,
c
c
c^c
cc是原因子句;在传统抽取任务中,目标是在给定
c
e
c^e
ce的条件下抽取
c
c
c^c
cc:
c
e
→
c
c
c^e \rightarrow c^c
ce→cc
- Step 1:情感提取和原因提取
第一步有Independent Multi-task Learning和 Interactive Multi-task Learning两种方法,后者要优于前者,可以在前者基础上进一步抓取了情感和原因之间的联系,下面对这两种方法进行介绍:- Independent Multi-task Learning
有文档 d = { c 1 , c 2 , ⋯ , c ∣ d ∣ } d=\{c_1,c_2,\cdots,c_{\vert d\vert}\} d={c1,c2,⋯,c∣d∣},每个句子 c i c^i ci包含多个单词 c i = { w i , 1 , w i , 2 , ⋯ , w i , ∣ c i ∣ } c_i=\{w_{i,1},w_{i,2},\cdots,w_{i,\vert c_i\vert}\} ci={wi,1,wi,2,⋯,wi,∣ci∣}, 使用2层的Bi-LSTM,如下图所示
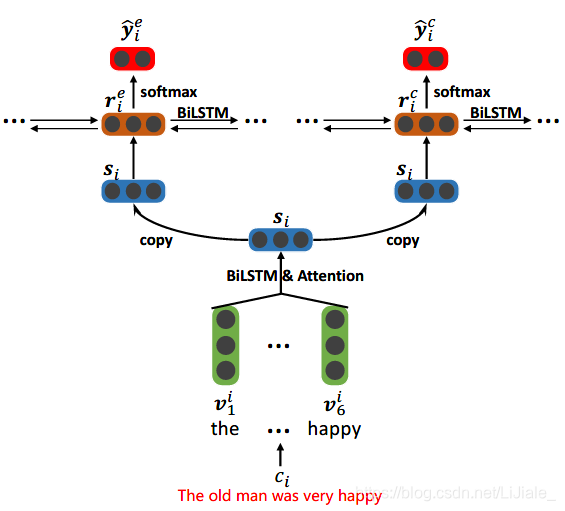
底层用的是word-level的Bi-LSTM,每个Bi-LSTM对应一个子句,获得每个子句中单词的上下文信息,通过attention机制获得句子的表示 s i s^i si,(原文中没有写具体形式,个人认为这里的attention,大概体现在子句中每个单词的重要程度);第二层对应为两部分,一个是情感提取一个是原因提取,每个Bi-LSTM都是句子级别的,接收下层传上来的句子的表示 [ s 1 , s 2 , ⋯ , s ∣ d ∣ ] \lbrack s_1,s_2,\cdots,s_{\vert d\vert}\rbrack [s1,s2,⋯,s∣d∣],隐藏状态 r i e r_i^e rie和 r i c r_i^c ric可以看作是句子 c i c^i ci的context-aware representation,最终送入softmax层进行情感预测和原因预测(下标e和c分布代表情感和原因):
y ^ i e = s o f t m a x ( W e r i e + b e ) ; y ^ i c = s o f t m a x ( W c r i c + b c ) \widehat y_i^e=softmax(W^er_i^e+b^e); \widehat y_i^c=softmax(W^cr_i^c+b^c) y ie=softmax(Werie+be);y ic=softmax(Wcric+bc) L e L^e Le和 L c L^c Lc是情感预测和原因预测的交叉熵损失,λ为权衡参数,模型的损失函数为:
L p = λ L e + ( 1 − λ ) L c L^p=\lambda L^e+(1-\lambda)L^c Lp=λLe+(1−λ)Lc - Interactive Multi-task Learning
上一方法中顶层的两部分是相互独立的,给定情感可以有助于提取原因,但是给定原因也有助于提取情感,于是Interactive Multi-task Learning致力于捕捉情感和原因之间的关系。使用情感抽取来帮助原因抽取的方法称为Inter-EC,用原因抽取来帮助情感抽取的方法称为Inter-CE,二者的结构相似,文章只对Inter-EC进行了介绍,结构如下图所示:
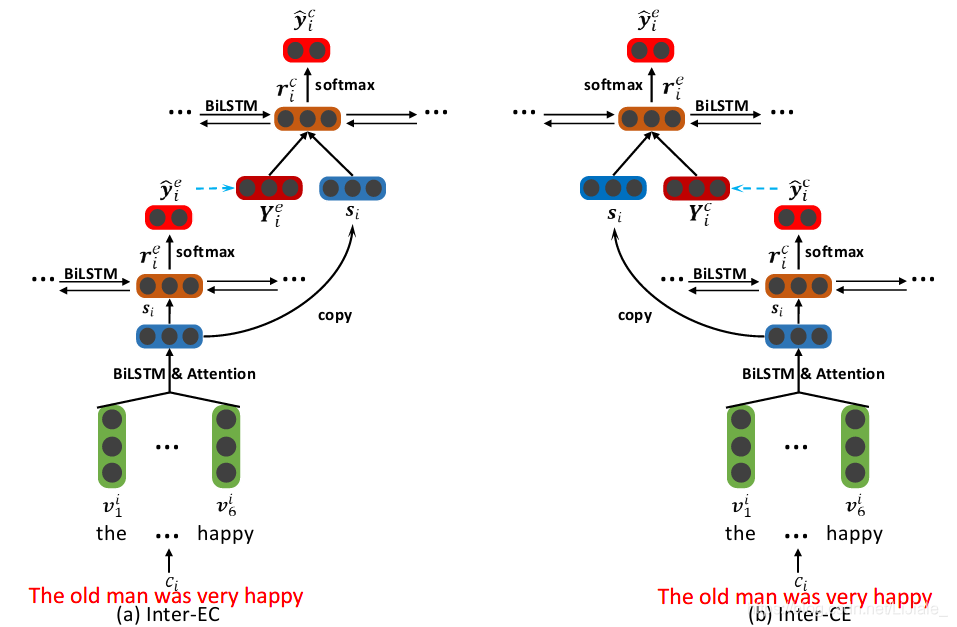
底层得到的句子表示 [ s 1 , s 2 , ⋯ , s ∣ d ∣ ] \lbrack s_1,s_2,\cdots,s_{\vert d\vert}\rbrack [s1,s2,⋯,s∣d∣]作为情感提取的输入,隐藏状态 r i e r_i^e rie是标签 y ^ i e \widehat y_i^e y ie的特征, y ^ i e \widehat y_i^e y ie经过嵌入得到 Y i e Y_i^e Yie,继续向上走, ( s 1 ⊕ Y i e , s 2 ⊕ Y 2 e , ⋯ , s ∣ d ∣ ⊕ Y ∣ d ∣ e ) (s_1\oplus Y_i^e,s_2\oplus Y_2^e,\cdots,s_{\vert d\vert}\oplus Y_{\vert d\vert}^e) (s1⊕Yie,s2⊕Y2e,⋯,s∣d∣⊕Y∣d∣e)(⊕代表concatenation)作为原因提取的输入,隐藏态 r i c r_i^c ric用来预测 y ^ i c \widehat y_i^c y ic,至此实现了两者的交互
- Independent Multi-task Learning
- Step 2:情感原因的配对和过滤
经过Step 1,得到了一组情感情感子句 E = { c 1 e , ⋯ , c m e } E=\{c_1^e,\cdots,c_m^e\} E={c1e,⋯,cme}和原因子句 C = { c 1 c , ⋯ , c n c } C=\{c_1^c,\cdots,c_n^c\} C={c1c,⋯,cnc};Step 2中,E和C做笛卡尔乘积,得到所有可能的配对 P a l l = { ⋯ , ( c i e , c j c ) , ⋯ } P_{all}=\{\cdots,(c_i^e,c_j^c),\cdots\} Pall={⋯,(cie,cjc),⋯},接下来 P a l l P_{all} Pall中的每一对都用有三种特征构成的特征向量表示:
x ( c i e , c j c ) = [ s i e , s j c , v d ] x_{(c_i^e,c_j^c)}=\lbrack s_i^e,s_j^c,v^d\rbrack x(cie,cjc)=[sie,sjc,vd]
其中 s e s^e se和 s c s^c sc是情感子句和原因子句的表示, v d v^d vd代表两个句子的距离。
接着用逻辑回归检测每个候选对 ( c i e , c j c ) (c_i^e,c_j^c) (cie,cjc)是否有因果关系,
y ^ ( c i e , c j c ) ← δ ( θ T x ( c i e , c j c ) ) {\widehat y}_{(c_i^e,c_j^c)\leftarrow\delta(\theta^Tx_{(c_i^e,c_j^c)})} y (cie,cjc)←δ(θTx(cie,cjc))
( c i e , c j c ) (c_i^e,c_j^c) (cie,cjc)存在因果关系时 y ^ ( c i e , c j c ) = 1 {\widehat y}_{(c_i^e,c_j^c)}=1 y (cie,cjc)=1,否则 y ^ ( c i e , c j c ) = 0 {\widehat y}_{(c_i^e,c_j^c)}=0 y (cie,cjc)=0; δ ( ) \delta() δ()是Sigmoid函数,最终将 P a l l P_{all} Pall中 y ^ ( c i e , c j c ) = 0 {\widehat y}_{(c_i^e,c_j^c)}=0 y (cie,cjc)=0的对移除,就得到了最终的“情感-原因”对。














 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









