




1、什么是DataFrame
在Python的Pandas库中,DataFrame 是一个二维的、大小可变的、带有标签的数据结构,你可以把它想象成一个电子表格(如Excel)或SQL数据库中的表。它由行(rows)和列(columns)组成,每一列都可以是不同的数据类型(如数字、字符串、布尔值等)。DataFrame是Pandas中最核心、最常用的数据结构,广泛用于数据清洗、处理、分析和可视化。
简单来说,如果说Series是一条数据列表,那么DataFrame就是由多条共享相同索引的Series组成的“数据表”。
Series 与 DataFrame 对比
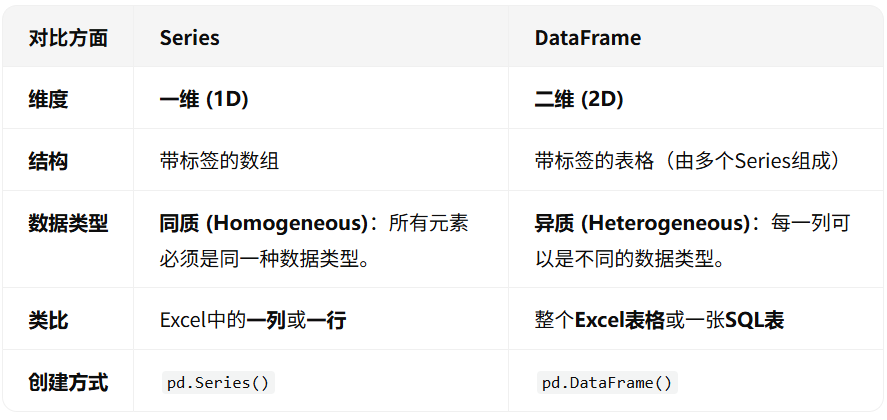
2、创建一个DataFrame对象
语法格式pandas.DataFrame(data,index,columns,dtype,copy)
参数说明:
data:表示数据
index:表示行标签
columns:列表签
dtype:每一列数据的数据类型,与python数据类型不同
copy:用于复制数据
引入pandas库
import pandas as pd设置对齐方式
pd.set_option('display.unicode.east_asian_width',True)2.1 通过二维数组创建
data=[[66,88,99],[56,77,45],[99,67,87]]
columns=['语文','数学','英语']
df = pd.DataFrame(data=data,columns=columns)
print(df)2.2 通过字典创建成绩表
df2 = pd.DataFrame({
'姓名':"张三",
'语文':[66,88,99],
'数学':[56,77,45],
'英语':[99,67,87],
})
print(df2)注:在上述代码中"姓名"的value值是单个数据所以每一行都添加了相同的数据
2.3属性
#部分属性
df2.values #参看所有元素的值
df2.dtypes #查看元素的值
df2.index #查看所有行名
df2.index = [1,2,3] #重命名行名
df.columns #参看所有列名
df.columns = ['yu','sx','wy'] #重命名
df2.T #行列数据转换
df2.head()#查看前n条数据,默认前5条
df2.tail()#查看后n条数据,默认后5条
df2.shape[]#查看行数和列数,[0]表示行,[1]表示列2.4 重要函数
df2.describe() # 查看每列的统计汇总信息,DataFrame类型
df2.count() # 返回每一列中的非空值的个数
df2.sum() # 返回每一列的和,无法计算返回空值
df2.max() # 返回每一列的最大值
df2.min() # 返回每一列的最小值
df2.idxmax() # 返回最大值所在的自定义索引位置
df2.idxmin() # 返回最小值所在的自定义索引位置
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









