







摘要
氨基酸突变降低蛋白质热力学稳定性与许多疾病有关,而具有增强稳定性的工程蛋白质在研究和医学中至关重要。So用于预测突变如何扰乱蛋白质稳定性的计算方法很重要。
在这里,我们介绍了ThermoMPNN,这是一个深度神经网络,经过训练可以预测给定初始结构的蛋白质点突变的稳定性变化。通过这样做,我们展示了一个新发布的大规模稳定性数据集对训练鲁棒稳定性模型的实用性。我们还利用迁移学习,通过使用从经过训练的深度神经网络中提取的学习特征来预测蛋白质的氨基酸序列,从而利用第二个更大的数据集。我们表明,我们的方法使用轻量级模型架构在已建立的基准数据集上实现了竞争性的性能,这使得可以进行快速、可扩展的预测。
介绍
蛋白质在临床、工业和研究领域中的重要性和多样性,强调了蛋白质在生物学和医学中的关键作用。大型语言模型(LLMs)进行蛋白质结构预测,以及通过迁移学习完成各种蛋白质设计任务,包括基于序列的稳定性预测都取得了一定成就。
proteinMPNN基于从PDB中发现的天然蛋白质中学到的结构模式,预测了给定位置所有20种氨基酸作为原始残基的概率。然而,通过生物自然进化来优化的稳定性只是在生存情况下够用,所以仅用proteinMPNN预测DDG°值可能不足以实现很好的性能。因此,作者假设像ProteinMPNN这样训练的序列恢复模型可能适合于迁移学习,以实现准确的DDG°预测。
ThermoMPNN利用序列恢复和稳定性优化任务之间的知识重叠,通过使用预训练的ProteinMPNN嵌入作为转移学习的输入特征。
两个互补的大规模数据集:(1)用于训练ProteinMPNN的序列恢复数据集和(2)“Megascale数据集”,该数据集包括了来自约300个蛋白质的数百万个突变的实验稳定性测量。
直到最近,用于训练和评估蛋白质稳定性预测器的最全面的数据集是来自不同研究的汇编合集,而已编目的突变数量通常在不到10,000个突变的范围内。由于迁移学习和与Megascale数据集的训练相结合,ThermoMPNN学习了可泛化的稳定性结构决定因素,并在各种基准测试中取得了竞争性的性能。我们还调查了不同的训练方案,以确定每个数据集和模型组件的贡献。最后,我们对比了ThermoMPNN与其父序列恢复模型的预测模式和偏差。
ThermoMPNN 架构

两个模块组成:预训练的 ProteinMPNN 模型和稳定性预测模块。作为输入特征,ProteinMPNN 使用目标残基和其 48 个最近邻残基之间的骨架原子之间的配对距离,编码为高斯径向基函数(RBFs)。蛋白质的野生型(生物进化中自然产生的)(WT)氨基酸序列也通过解码机制作为特征传递给 ProteinMPNN。
ProteinMPNN是一个包括三个编码器层(浅蓝框)和三个解码器层(黄色框)的图神经网络。在编码过程中,节点(每个残基一个节点)和边缘(每对残基由边缘连接)之间的消息传递允许每个残基了解其结构环境。解码器层将 WT 序列嵌入与节点和边嵌入相结合,以预测输入结构中所选残基的有利氨基酸,其中每个解码器层中的中间信息存储在 128 维嵌入中(深金色框)。在 ThermoMPNN 中,我们不是将预测一直传递到序列恢复输出层,而是从每个层中提取这些解码器嵌入,仅保留要突变的残基的嵌入(紫色条)。然后,这与相应的序列嵌入(绿框)连接以产生一个大小为128+(128×N)的向量,其中N是包含的解码器层数这是稳定性预测模块的输入向量(图1A,右框)。
ThermoMPNN的下一个组件是一个轻量级注意力块。首先,在一维输入向量上执行两个独立的填充卷积(大小=9,步长=1)。特征卷积通过一个丢弃层(概率=0.25),而注意力卷积则通过softmax层进行重新缩放。然后,这两个输出进行逐元素相乘,根据学习到的注意力模式产生一个重新加权的大小相同的特征向量。最后,这个向量通过具有两个隐藏层(大小为64和32)的MLP进行传递,以预测一个∆∆G°,该∆∆G°通过从预测的突变∆∆G°中减去预测的相同位置的野生型∆∆G°来进行归一化。
∆∆G 和 ∆Tm 都是蛋白质稳定性的指标,但是它们代表不同的概念。
∆∆G(delta delta G)代表蛋白质在突变后自由能变化的差异,通常用来评估蛋白质突变对其稳定性的影响。∆∆G 的值是突变体(mutant)和野生型(wildtype)蛋白质的自由能之间的差异。
∆Tm(delta Tm)代表蛋白质的熔解温度变化,通常用来评估蛋白质突变对其热稳定性的影响。∆Tm 的值是突变体和野生型蛋白质的熔解温度之间的差异。
数据集准备过程
Megascale数据集源自Tsuboyama等人最近的一项研究,其中点突变DDG°值是从蛋白酶敏感性实验中推断得出的。为了进行本研究,通过仅选择具有可靠DDG°值和有效野生型结构的单点突变来进行数据筛选,以获取最终数据集,跨越298个蛋白质共计272,712个突变。
为了评估模型在使用传统生物物理技术收集的热力学稳定性数据上的性能,我们通过将FireProtDB数据库中的基于序列的稳定性数据与PDB中的实验结构相匹配,最终数据集Fireprot,包括了100个独特蛋白质的3,438个突变。
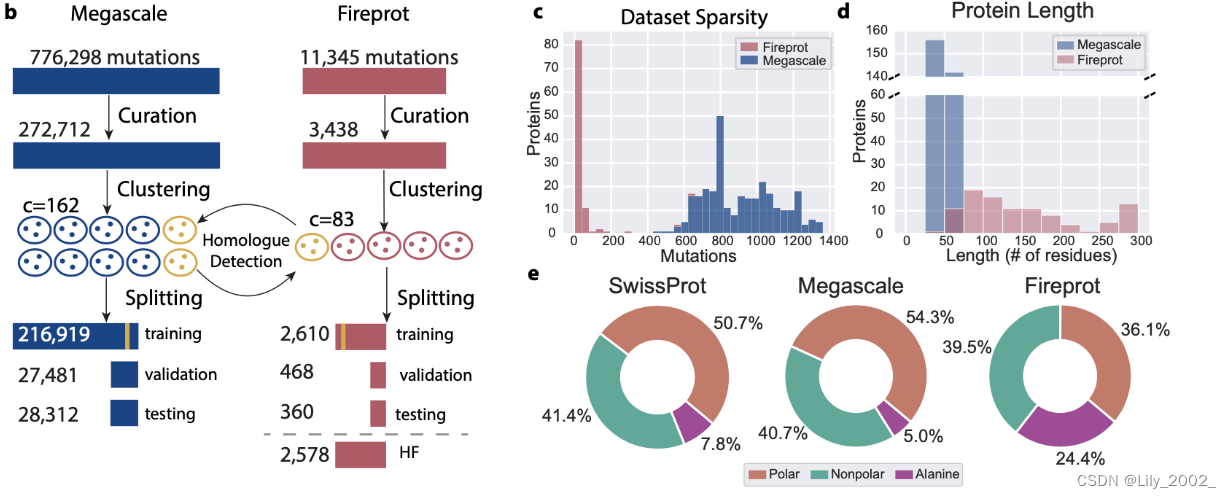
然后,使用MMseqs2进行严格的序列相似性切割将两个筛选过的数据集进行聚类。对这两个数据集进行交叉参考,以检测数据集之间的同源重叠,任何具有同源匹配的蛋白质聚类都自动分配到其相应的训练数据集。这确保了Megascale或Fireprot测试集中的任何蛋白质在任何一个训练集中都没有任何同源物。然后,将剩余的聚类随机拆分,以产生每个数据集的大约80/10/10的突变比例分配。在拆分Fireprot数据集时,具有>250个数据点的蛋白质也会自动分配到训练集,因为它们包含在验证集或测试集中可能会主导任何性能估计,从而扭曲结果。最后,通过保留除了与Megascale数据重叠的所有Fireprot数据以外的所有数据,为了评估仅使用Megascale数据训练的模型,制作了第四个拆分,“无同源”(HF)Fireprot。
实验结果
b图的横坐标exp是生物实验做出来的结果
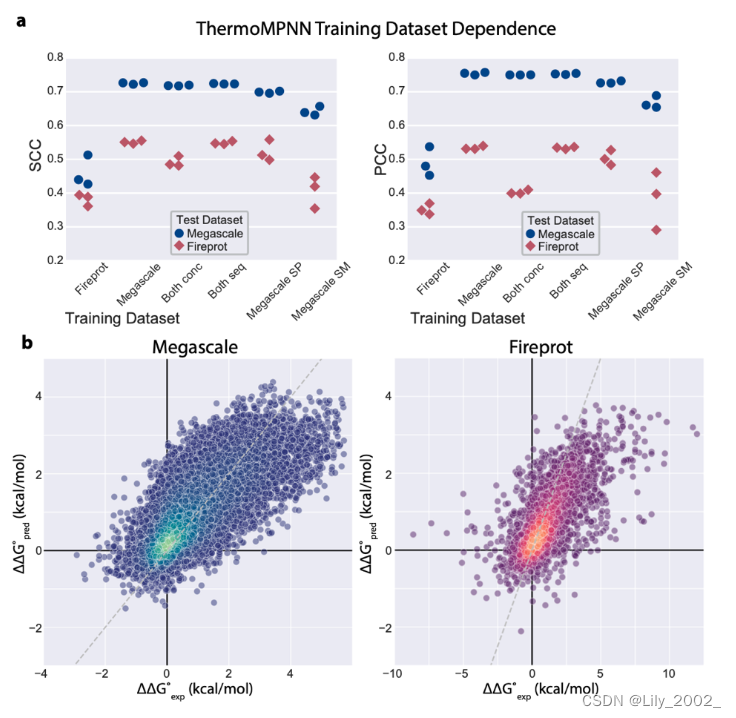
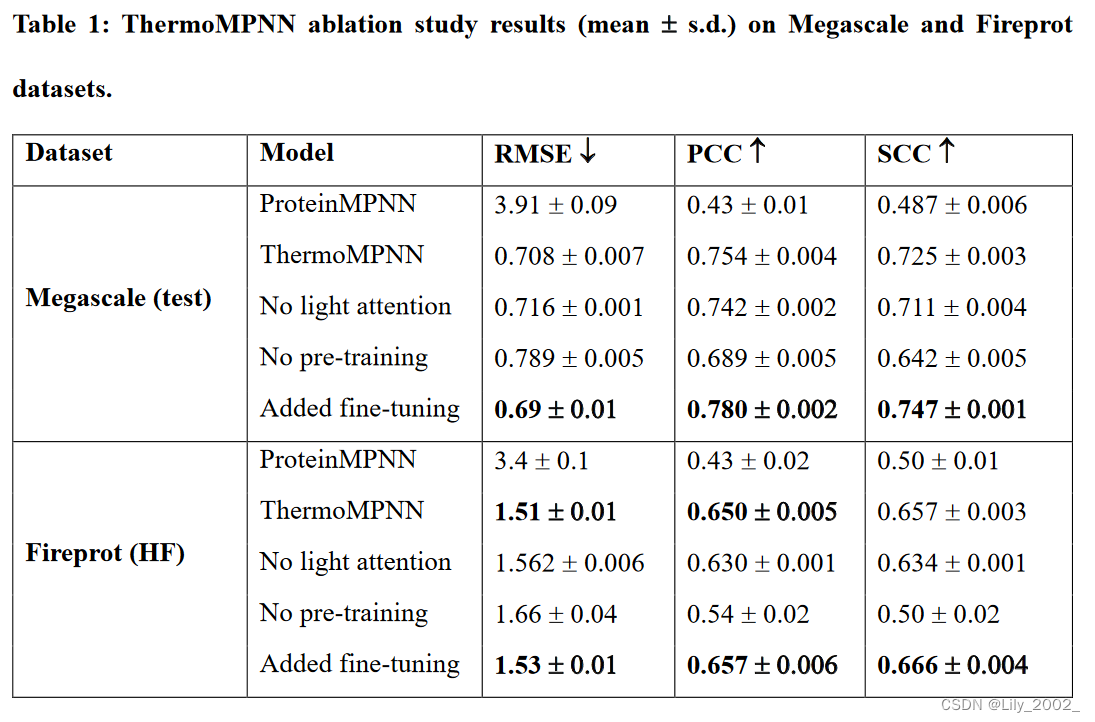
消融实验















 3151
3151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









