







从今天起,开始一点点记录自己学习的路线,也是作为对自己的一个监督。
今天要做的是从西刺代理网(https://www.xicidaili.com/nn/)爬取免费代理ip存入本地redis。
作为一个不舍得花钱买动态代理ip的穷鬼,只能想出这么个鬼办法了。
获取url
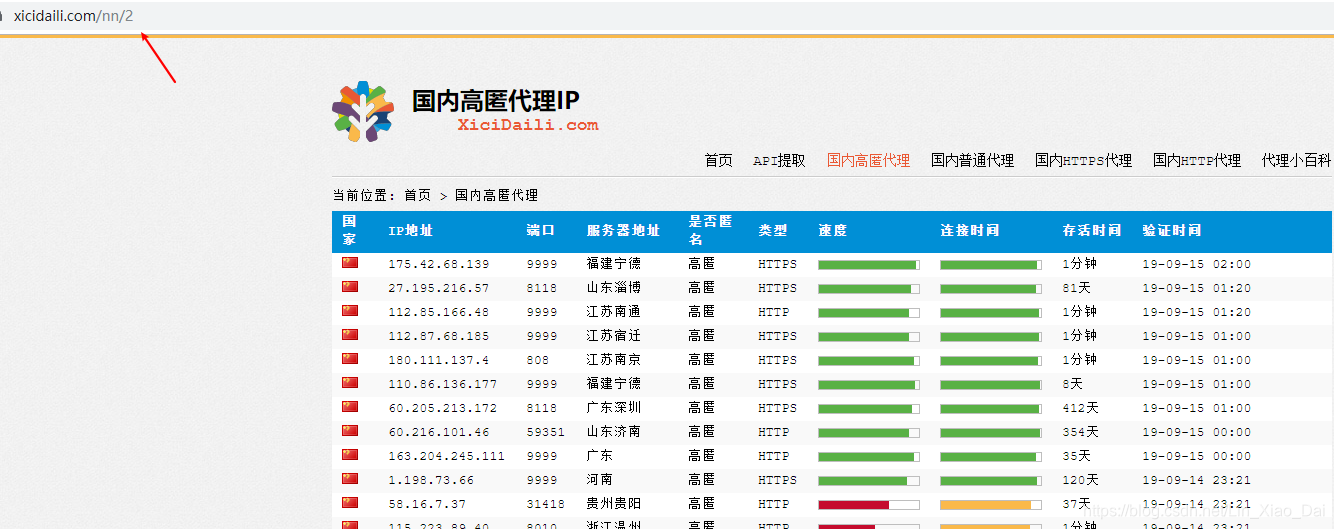
上图为西刺代理网的第二页,我们往后翻几页可以很容易地分析出,西刺url设计的很简单,翻页的变化就在于/nn/后面的数字变化,所以可以确定的是url = f"https://www.xicidaili.com/nn/{page}",这里的page就是列表页的序号,下面代码我用的是format方式进行url的拼接。
def main():
xc = XiCi()
basic_url = "https://www.xicidaili.com/nn/{}"
for page in range(1, 15):
url = basic_url.format(page)
xc.get_page(url)
分析页面的源码
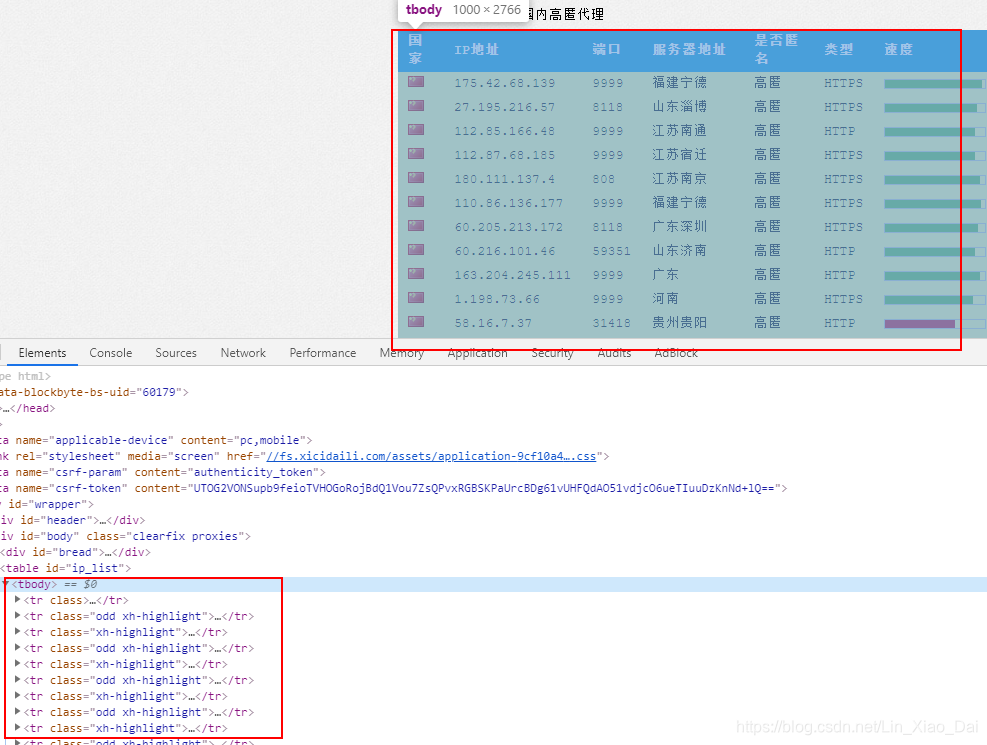
- 通过F12查看渲染后的代码和Ctrl+U查看源码发现两者没有区别,所以可以判断西刺没有做什么加密反爬虫,什么js动态调用数据的事儿所以就方便我们
做坏事爬取代理。 - 我们可以发现整个页面的代理ip列表其实就是放在一个tbody标签里面,里面有一堆的tr,要注意,第一个tr是表头,不是我们要爬取的ip地址,所以我们xpath可以这样写
//tr[position()>1]。 - 打开一个tr我们可以看到,西刺真的是特别好,写的干干净净,host在td[2],port在td[3],协议在td[6]。

完整代码
"""
爬取西刺网的免费代理ip,并进行测试,存入redis
"""
import redis
import requests
from fake_useragent import UserAgent
from gevent.threadpool import ThreadPoolExecutor
from lxml import etree
class XiCi(object):
def __init__(self):
"""
类加载的一些初始化设置,包括连接redis,创建线程池等
"""
self.conn = redis.StrictRedis(host="localhost", port=6379, db=1) # 初始化连接redis
self.threadpool = ThreadPoolExecutor(max_workers=100) # 此处使用线程池
self.HTTP_PROXY = 'http_proxy' # 用于存放http代理
self.HTTPS_PROXY = 'https_proxy' # 用于存放https代理
self.count = 0 # 用来计数已经存入几个代理ip
self.test_url = "https://www.baidu.com"
def get_page(self, url):
"""
获取每个详情列表的tr,传入parse进行解析ip,存入redis
:param url:
:return:
"""
headers = {
"User-Agent": UserAgent().random,
}
res = requests.get(url=url, headers=headers)
html = etree.HTML(res.text)
tr_s = html.xpath("//tr[position()>1]") # 这里返回的是一个列表,里面是100个tr
self.threadpool.map(self._parse_proxy, tr_s)
def _parse_proxy(self, tr):
"""
获取每一条tr,对http,ip,port进行解析,将三者拼接再进行测试
将http和https分别存在两个不同的set里面
因为是set所以也直接避免了重复问题
:param tr:
:return:
"""
host = tr.xpath("./td[2]/text()")[0]
port = tr.xpath("./td[3]/text()")[0]
type = tr.xpath("./td[6]/text()")[0].lower()
if type == "http":
proxy = "http://" + host + ":" + port
self._test_proxy(type, proxy)
else:
proxy = "https://" + host + ":" + port
self._test_proxy(type, proxy)
def _test_proxy(self, type, proxy):
"""
测试代理ip是否可用
:param proxy:
:return:
"""
proxies = {
type: proxy,
}
try:
res = requests.get(url=self.test_url, proxies=proxies, timeout=5)
# 如果返回值是200说明访问成功,根据type进行区分,存入不同的set
if res.status_code == 200:
if type == 'http':
self.conn.sadd(self.HTTP_PROXY, proxy)
else:
self.conn.sadd(self.HTTPS_PROXY, proxy)
self.count += 1
print(f"\r已加载{self.count}个proxy", end="")
except Exception as e:
print(f"\r无效ip:{proxy}", end="")
def main():
xc = XiCi()
basic_url = "https://www.xicidaili.com/nn/{}"
for page in range(1, 5):
url = basic_url.format(page)
xc.get_page(url)
if __name__ == '__main__':
main()
总结
- 免费的代理ip基本来回就这几个,很容易被别的网站封了,所以也就是拿来学习。
- 本次使用到的几个知识点是:
– requests
– redis
– fake_useragent
– gevent.threadpool
– lxml - 写的不好还请各位海涵,欢迎各位底下留言批评。














 5944
5944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









