







由于是从Word文档直接复制过来,其中格式如果乱码或者不通顺,请评论区告知我
参考链接:
https://blog.csdn.net/qq_41185868/article/details/86548830
https://zhuanlan.zhihu.com/p/33544892
一、网络结构图


二、SSD原理与实现
https://zhuanlan.zhihu.com/p/33544892
1、SSD和YOLO相同和不同
相同:都是one-stage方法;
不同点:
- 1)SSD采用CNN来直接进行检测;Yolo在全连接层之后做检测(Yolov1包含有全连接层,从而能直接预测 Bounding Boxes 的坐标值。 作者发现通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易。所以从yolov2开始已经去掉了)
- 2)SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;(这个yolo在后面的版本中也借鉴了这个优点)
- 3)SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)
2、设计思路
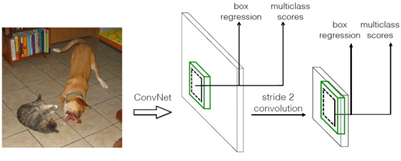
1)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图(feature map),CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如图3所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图(同场景视角但清晰)来用来检测相对较小的目标,而小的特征图(同场景视角但模糊)负责检测大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









